What are LLM Benchmarks?
LLM Benchmarks are standardized evaluation datasets and frameworks designed to assess and compare the performance of frontier and open source Large Language Models (LLMs) across diverse tasks and capabilities.
What are the leading models?
| Model | Average | MMLU | GPQA | MMMU | HumanEval | MATH |
|---|
| Claude 3.5 Sonnet | 79.85% | 88.70% | 59.4% | 68.3% | 92.00% | 71.10% |
| GPT-4o (0513) | 75.92% | 88.70% | 53.6% | 69.1% | 90.20% | 76.60% |
| GPT-4 Turbo (0409) | 73.20% | 86.50% | 48.0% | 63.1% | 90.20% | 72.20% |
| Claude 3 Opus | 72.88% | 86.80% | 50.4% | 59.4% | 84.90% | 60.10% |
| GPT-4o Mini | 67.36% | 82.00% | 40.2% | 59.4% | 87.20% | 70.20% |
| GPT-4 (0314) | 67.36% | 86.40% | 35.7% | 56.8% | 67.00% | 52.90% |
| Gemini 1.5 Pro | 64.18% | 81.90% | 46.2% | 62.2% | 71.90% | 58.50% |
| Llama 3 70B | 63.90% | 82.00% | 39.5% | — | 81.70% | 50.40% |
| Gemini Ultra | 62.28% | 83.70% | 35.7% | 59.4% | 74.40% | 53.20% |
| Gemini 1.5 Flash | 62.92% | 78.90% | 39.5% | 56.1% | 67.50% | 67.70% |
| Claude 3 Sonnet | 62.30% | 79.00% | 46.4% | 53.1% | 73.00% | 43.10% |
| Claude 3 Haiku | 61.88% | 75.20% | 40.1% | 50.2% | 75.90% | 38.90% |
| Gemini Pro | 58.88% | 71.80% | 27.9% | 62.2% | 67.70% | 32.60% |
| Mistral Large | 57.70% | 81.20% | 35.1% | — | 45.10% | 45.00% |
| GPT-3.5 | 50.60% | 70.00% | 28.1% | — | 48.10% | 34.10% |
| Llama 3 8B | 54.20% | 68.40% | 34.2% | — | 62.00% | 30.00% |
| Mixtral 8×7B | 48.60% | 70.60% | 37.2% | — | 40.20% | 28.40% |
These benchmarks serve several crucial purposes, including:
-
Performance Measurement — They provide quantitative metrics to gauge an LLM's proficiency in different areas, such as language understanding, generation, reasoning, and domain-specific knowledge.
-
Model Comparison — Benchmarks enable researchers and practitioners to compare different LLMs objectively, helping to track progress in the field and identify state-of-the-art models.
-
Capability Assessment — They help identify strengths and weaknesses of LLMs, highlighting areas where models excel or need improvement.
-
Progress Tracking — As models evolve, benchmarks offer a consistent way to measure advancements in AI and natural language processing over time.
A few prominent LLM benchmarks include:
- MMLU (Massive Multitask Language Understanding): Evaluates models on a wide range of academic and professional subjects.
- TruthfulQA: Assesses a model's ability to avoid generating false or misleading information.
- HellaSwag: Tests common sense reasoning and situational understanding.
- GPQA (Graduate-Level Google-Proof Q&A): Challenges models with expert-level questions in biology, physics, and chemistry.
- MT-Bench: Evaluates multi-turn conversational abilities of language models.
- LMSYS Chatbot Arena: A dynamic platform for evaluating and ranking large language models based on their conversational abilities, using a combination of human feedback and automated scoring.
It's important to note that while benchmarks provide valuable insights, they may not fully capture a model's real-world performance or its ability to generalize to diverse tasks. Therefore, a holistic evaluation approach, combining multiple benchmarks and task-specific assessments, is often recommended for a comprehensive understanding of an LLM's capabilities.
Our analysis reveals limitations in current benchmarks, highlighting the need for customized evaluation methods tailored to specific use cases and domains.
Based on leading eval benchmarks, how do LLMs rank in 2024?
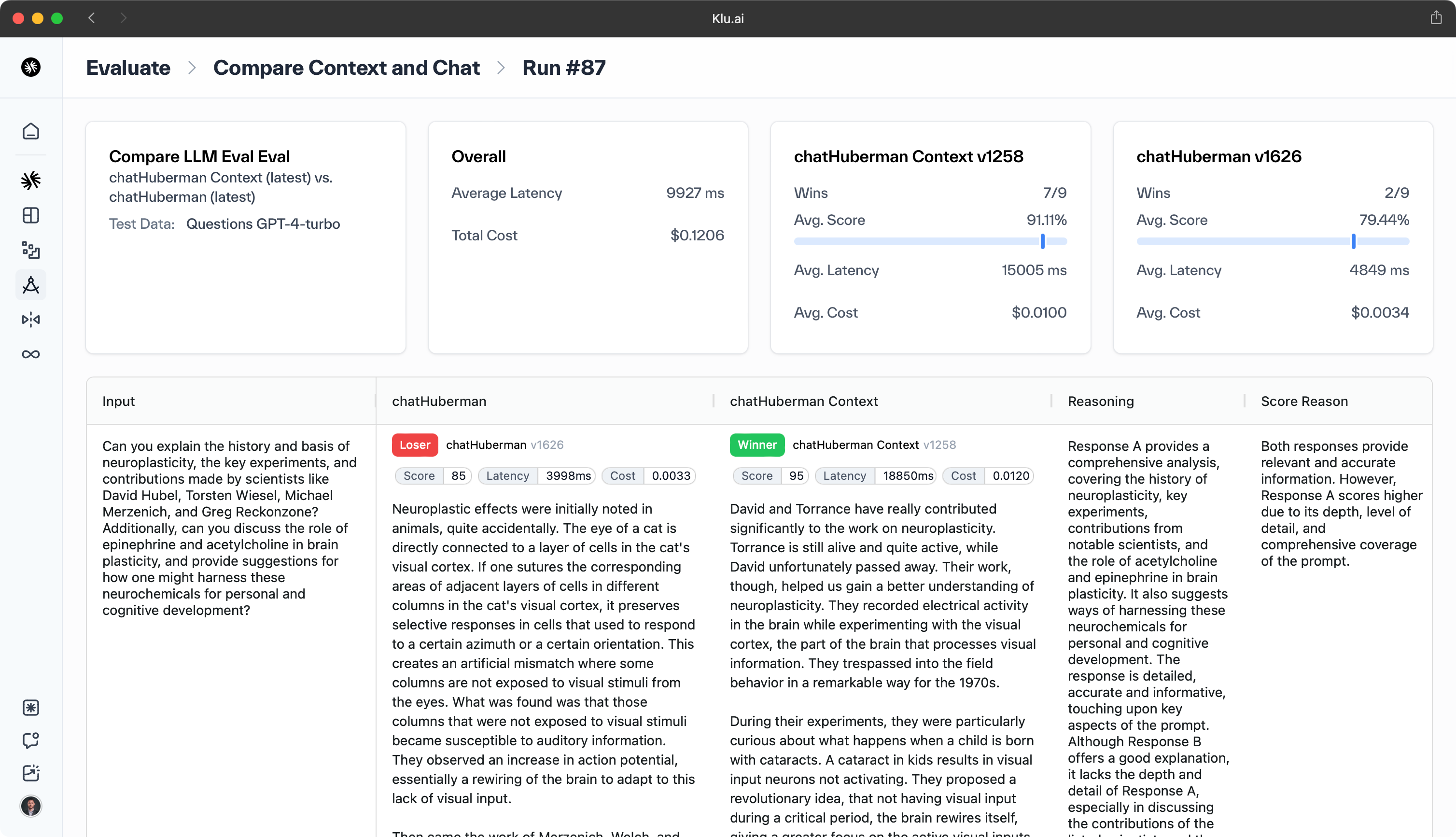
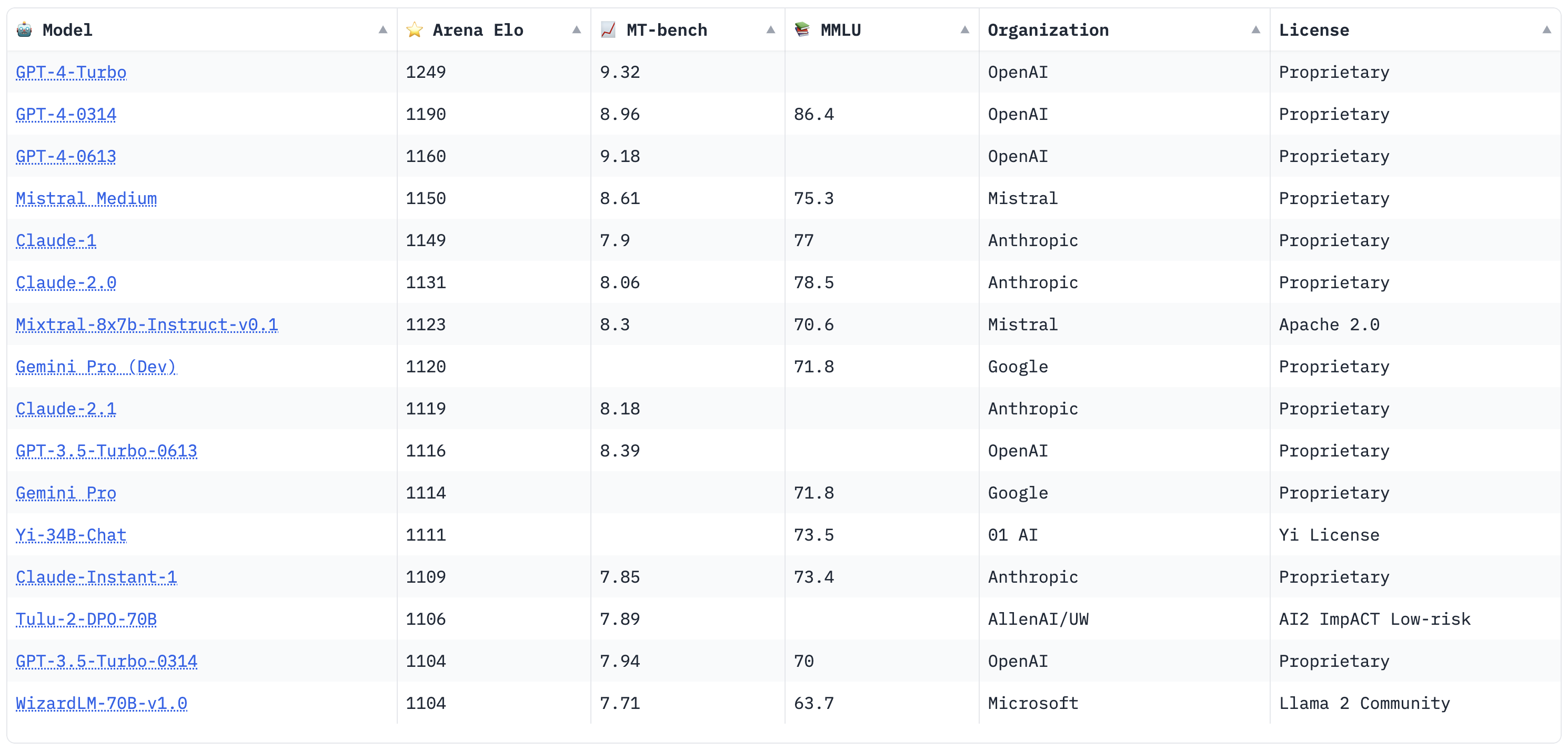
As of June 28, 2024, GPT-4o leads the LLM rankings. It tops the Arena Elo rating at 1287 and scores 9.32 on MT Bench, excelling in both human preference and LLM-as-a-judge.
The above models are evaluated based on their performance on the Chatbot Arena Elo, MT-bench, AlpacaEval 2, and MMLU benchmarks. Chatbot Arena Elo is a head-to-head human prefence ranking, while MT-bench is an LLM-as-a-judge eval, AlpacaEval is a head-to-head LLM preference ranking, and MMLU benchmarks reading comprehension.
Ranking last updated July 19, 2024
Key Takeaways
-
LLM benchmarks are essential standardized tests that consistently evaluate language models' capabilities across various tasks, including language generation, translation, reasoning, and summarization. These benchmarks enable fair comparisons between models and track progress in the field over time, providing a standardized framework for assessing model performance.
-
Different types of LLM benchmarks offer comprehensive assessments of models' strengths and weaknesses across diverse fields. These include reasoning and comprehension benchmarks, QA and truthfulness benchmarks, math and logic benchmarks, and coding benchmarks. Each type focuses on specific aspects of language understanding and generation, collectively providing a nuanced view of a model's capabilities across different domains of knowledge and skill.
-
Current LLM benchmarks face limitations that necessitate ongoing development and evolution. These challenges include restricted scope, which may overlook important aspects of language understanding, rapid obsolescence due to quick advancements in model capabilities, and the potential for overfitting to specific benchmark datasets or tasks. To address these issues, there is a continuous need for developing more robust, diverse, and adaptable benchmarking frameworks, including custom benchmarks for specific use cases and evolving evaluation methodologies to keep pace with rapid advancements in language model capabilities.
As natural language processing evolves from small models to LLMs, evaluation is crucial, particularly for tasks like natural language inference. This blog post aims to clarify the complex evaluation process, helping readers understand and compare the performance of different models for various tasks.
We will discuss key benchmarks, their significance, and how they contribute to developing more reliable and efficient models.
Deep Dive Benchmarks
Want to learn more? Deep dive benchmarks with a detailed analysis of specific evaluation metrics and methodologies used to assess the performance of large language models (LLMs). These benchmarks offer insights into the strengths and weaknesses of LLMs across various specialized tasks and domains.
Understanding LLM Benchmarks
LLM benchmarks are standardized tests designed to measure a model’s capabilities in various tasks. These benchmarks are crucial for evaluating LLM performance, as they provide a consistent and objective way to compare different models. By using standardized tests, researchers and developers can assess how well a model performs in specific tasks, such as:
- Educational tests
- Language generation
- Text summarization
- Translation
- Reasoning
- Information retrieval
- Summarization
- Sentiment analysis
- Question-answering
- Agentic tasks
- Coding
- Reasoning
- Math
- Truthfulness
Benchmarking LLMs involves giving the model a task, measuring the results, and ensuring a reliable evaluation. This process helps identify the strengths and weaknesses of LLMs, guiding improvements and innovations in the field. Standardized benchmarks also allow the community to build on each other’s progress, facilitating continuous advancement in LLM capabilities.
Definition of LLM Benchmarks
LLM benchmarks are standardized evaluation frameworks designed to assess the performance and capabilities of large language models across a diverse range of tasks. These benchmarks serve multiple crucial purposes:
- Quantification: They provide a systematic way to measure and quantify an LLM's performance on specific tasks or domains.
- Comparison: Benchmarks enable fair and consistent comparisons between different models, facilitating progress tracking in the field.
- Identification: They help identify strengths and weaknesses of models, guiding further development and improvement efforts.
- Standardization: Benchmarks establish common evaluation criteria, promoting transparency and reproducibility in LLM research.
By assessing models across this wide spectrum of capabilities, LLM benchmarks provide a nuanced understanding of a model's overall performance, highlighting areas of excellence and identifying opportunities for enhancement. This multifaceted evaluation approach is crucial for advancing the field of natural language processing and artificial intelligence.
Importance of LLM Benchmarks
Benchmarks are essential for evaluating large language models’ performance, enabling easier comparison of models and helping organizations decide which models best suit their objectives,. By providing an objective indication of an LLM’s performance, benchmarks facilitate the selection of the best model for a specific use case.
Moreover, benchmarks are crucial for building reliable and fail-safe models. They allow researchers and developers to build on each other’s progress and make necessary improvements, driving continuous innovation in the field of LLMs.
Types of LLM Benchmarks
There are various types of LLM benchmarks designed to evaluate different aspects of language model performance, including general language understanding evaluation. These benchmarks include:
-
Reasoning and comprehension — GLUE (General Language Understanding Evaluation), SuperGLUE, and SQuAD (Stanford Question Answering Dataset) are widely used benchmarks in this category.
-
QA and truthfulness — TruthfulQA, MMLU (Massive Multitask Language Understanding), and ARC (AI2 Reasoning Challenge) are prominent benchmarks for assessing question-answering capabilities and truthfulness.
-
Math and logic — GSM8K (Grade School Math 8K), MATH (Mathematics Aptitude Test of Heuristics), and LogiQA are key benchmarks for evaluating mathematical and logical reasoning skills.
-
Coding — HumanEval, MBPP (Mostly Basic Python Programming), and CodeXGLUE are popular benchmarks used to assess coding abilities of language models.
Each type of benchmark focuses on specific tasks and capabilities, providing a comprehensive assessment of a model’s strengths and weaknesses.
The evaluation of LLMs is a critical process that leverages various tools and libraries, such as Klu.ai and the OpenAI Eval library, which incorporate metrics like HellaSwag, TruthfulQA, and MMLU. This comprehensive assessment is crucial for aligning LLMs with human values, ensuring their utility, safety, and fairness, and ultimately selecting the most suitable model for specific applications. As a core component of LLMOps, LLM evaluation plays a pivotal role in the ongoing development and optimization of these powerful language models, driving continuous improvement in their performance and real-world applicability.
Reasoning and Comprehension Benchmarks
Reasoning and comprehension benchmarks, such as MMLU (Massive Multitask Language Understanding) and HellaSwag, play a crucial role in evaluating the cognitive capabilities of large language models. These sophisticated assessment tools are designed to measure a model's ability to comprehend complex information and apply logical reasoning across a diverse range of tasks and domains.
MMLU, for instance, is a comprehensive benchmark that covers 57 subjects across fields like mathematics, history, law, and medicine. It assesses not only factual knowledge but also the model's capacity to apply this knowledge in context-specific scenarios. This multifaceted approach provides a nuanced understanding of a model's reasoning abilities and its potential to handle real-world applications that demand high-level cognitive processing.
HellaSwag, on the other hand, presents a unique challenge in the form of commonsense reasoning. It comprises a dataset of 10,000 carefully curated sentences, each with multiple possible endings. The task for the model is to select the most appropriate and logical conclusion based on its understanding of everyday scenarios and general knowledge about how the world functions. This benchmark is particularly effective in evaluating a model's grasp of implicit information and its ability to make intuitive leaps in reasoning.
Another notable benchmark in this category is DROP (Discrete Reasoning Over Paragraphs), which pushes the boundaries of natural language understanding even further. DROP requires models to perform complex reasoning tasks such as numerical operations, sorting, and counting based on information extracted from given passages. This benchmark is instrumental in assessing a model's capability to not only comprehend text but also to manipulate and reason with the information contained within it.
These benchmarks collectively provide a comprehensive evaluation of a model's cognitive abilities, offering insights into its potential performance in applications that require sophisticated language understanding and reasoning. By setting high standards for comprehension and logical inference, these tools drive the continuous improvement of language models, pushing them closer to human-like reasoning capabilities.
QA and Truthfulness Benchmarks
QA and truthfulness benchmarks, such as TruthfulQA, are specifically designed to evaluate the veracity and reliability of responses generated by large language models. TruthfulQA, a prominent benchmark in this category, comprises a comprehensive set of 817 questions meticulously curated across 38 diverse categories. These categories encompass a wide range of domains, including but not limited to health, law, finance, and politics. The benchmark's questions are carefully crafted to assess not only the model's factual knowledge but also its ability to discern truth from misinformation and avoid generating false or misleading content.
In the health category, for instance, questions might probe the model's understanding of medical facts, treatments, and public health information. The law section could test the model's grasp of legal principles, regulations, and judicial processes. Finance-related questions might assess knowledge of economic concepts, financial instruments, and market dynamics. Political questions could evaluate understanding of governmental systems, historical events, and current affairs.
The importance of these benchmarks cannot be overstated, particularly in an era where the dissemination of accurate information is crucial. They play a vital role in applications where the integrity and truthfulness of AI-generated content are paramount, such as in healthcare advisory systems, legal research tools, financial analysis platforms, and public information services. By rigorously testing models against these benchmarks, developers and researchers can identify and mitigate potential biases, inaccuracies, or tendencies to generate false information, thereby enhancing the reliability and trustworthiness of AI systems in critical decision-making contexts.
Math and Logic Benchmarks
Math and logic benchmarks, such as GSM8K and MATH, play a critical role in evaluating a language model's mathematical reasoning and logical thinking capabilities. These sophisticated benchmarks are designed to assess the model's ability to solve intricate mathematical problems and navigate complex logical sequences, providing valuable insights into the model's cognitive processes.
The GSM8K (Grade School Math 8K) benchmark, developed by OpenAI, is particularly noteworthy for its focus on multi-step mathematical reasoning. This benchmark comprises a dataset of 8,500 linguistically diverse grade-school math word problems, carefully curated to challenge the model's ability to interpret natural language, extract relevant information, and apply mathematical concepts in a step-by-step manner. The problems in GSM8K range from basic arithmetic to more advanced topics like ratios and percentages, requiring the model to demonstrate not only computational accuracy but also a nuanced understanding of problem-solving strategies.
Complementing GSM8K, the MATH benchmark raises the bar even further by presenting 12,500 challenging competition mathematics problems. These problems are sourced from various mathematical olympiads and contests, representing a level of difficulty that would challenge even highly skilled human mathematicians. What sets MATH apart is its inclusion of step-by-step solutions for each problem, allowing for a granular assessment of the model's problem-solving approach. This feature enables evaluators to analyze not just the final answer but also the logical progression and methodology employed by the model, providing a comprehensive view of its mathematical reasoning capabilities.
Together, these benchmarks serve as rigorous tests of a model's mathematical prowess, pushing the boundaries of what artificial intelligence can achieve in the realm of quantitative reasoning and logical problem-solving. By subjecting language models to these demanding evaluations, researchers and developers can identify areas for improvement and drive advancements in AI's capacity to handle complex mathematical and logical tasks.
Coding Benchmarks
Coding benchmarks such as HumanEval and MBPP (Mostly Basic Python Programming) are sophisticated evaluation tools designed to assess the code generation capabilities of large language models. These benchmarks go beyond simple syntax checks, delving into the model's ability to comprehend complex programming concepts, interpret natural language instructions, and produce functionally correct and efficient code.
HumanEval, developed by OpenAI, is a particularly rigorous benchmark consisting of 164 unique programming tasks. Each task is meticulously crafted to evaluate different aspects of coding proficiency. A typical HumanEval problem includes a function signature that defines the input parameters and return type, a detailed docstring explaining the function's purpose and expected behavior, a partially implemented function body, and a comprehensive set of unit tests. This structure challenges the model to not only complete the code but also to ensure it adheres to the specified requirements and passes all test cases.
MBPP, in contrast, focuses on a broader range of programming skills with its dataset of 1,000 crowd-sourced Python programming problems. These problems are carefully curated to cover a wide spectrum of difficulty levels, primarily targeting beginner to intermediate programmers. MBPP tasks often involve translating natural language descriptions into functional Python code, testing the model's ability to bridge the gap between human instructions and machine-executable programs. This benchmark is particularly valuable for assessing an LLM's grasp of fundamental programming concepts such as data structures, control flow, and basic algorithms, as well as its capacity to generate clean, readable, and Pythonic code.
Both HumanEval and MBPP play crucial roles in pushing the boundaries of AI-assisted coding, driving improvements in areas like automated code generation, intelligent code completion, and natural language to code translation systems. By providing standardized, diverse, and challenging coding tasks, these benchmarks enable researchers and developers to rigorously evaluate and compare the performance of different language models in the domain of software development.
Popular LLM Benchmarks Explained
This section provides an in-depth exploration of some of the most prominent and widely adopted LLM benchmarks in the field of artificial intelligence. We offer a comprehensive analysis of each benchmark's intricate design, its fundamental purpose in the evaluation landscape, and the specific cognitive and linguistic skills it aims to assess. Throughout this examination, we maintain a keen focus on the critical importance of LLM benchmarks in the broader context of AI development and application.
This section examines key LLM benchmarks, highlighting their unique designs and purposes. We'll explore how each benchmark assesses different aspects of LLM performance, including reasoning, knowledge, language skills, and task-specific abilities. This analysis reveals how these benchmarks collectively measure AI progress, guide model development, and inform real-world LLM applications.
HellaSwag
HellaSwag is a sophisticated benchmark designed to evaluate the commonsense reasoning capabilities of large language models (LLMs). This assessment tool probes an LLM's grasp of general world knowledge through intricate sentence completion tasks. In the HellaSwag challenge, models are presented with a diverse set of 10,000 sentences, each accompanied by four possible endings. The LLM's task is to select the most logical and plausible continuation, thereby demonstrating its ability to comprehend context and make intuitive inferences.
The evaluation methodology of HellaSwag closely resembles that of the MMLU (Massive Multitask Language Understanding) benchmark, where models are scored based on the proportion of exact correct answers. This approach provides a quantitative measure of an LLM's language comprehension and reasoning skills, offering valuable insights into its performance and accuracy across a wide range of scenarios.
ARC
The ARC (AI2 Reasoning Challenge) benchmark is a sophisticated tool designed to evaluate the human-like general fluid intelligence of large language models (LLMs). This rigorous assessment confronts LLMs with a carefully curated collection of complex, multi-part science questions typically encountered at the grade-school level.
The ARC corpus goes beyond simple fact retrieval, requiring language models to demonstrate both comprehensive knowledge and advanced reasoning abilities to solve intricate problems. By presenting challenges that demand the integration of information across multiple domains and the application of logical thinking, ARC provides a nuanced and robust assessment of an LLM's cognitive capabilities. This benchmark not only tests the breadth of a model's scientific understanding but also its ability to synthesize information, draw inferences, and apply knowledge in novel contexts, offering valuable insights into the model's potential for human-like reasoning and problem-solving in scientific domains.
MMLU
The MMLU (Massive Multitask Language Understanding) benchmark is a comprehensive evaluation tool designed to assess the multitask accuracy of language models across an extensive array of 57 diverse tasks. This rigorous benchmark demands that models demonstrate not only extensive problem-solving skills but also possess a vast repository of world knowledge. MMLU's scope is remarkably broad, encompassing subjects ranging from elementary mathematics and US history to computer science and law, thereby testing the model's versatility and depth of understanding across multiple disciplines.
At its core, the MMLU dataset comprises 15,908 meticulously crafted questions, strategically divided into categories such as humanities, social sciences, and STEM. The benchmark's scoring methodology involves averaging the scores from these individual categories to produce a comprehensive final score, providing a holistic view of the model's performance. What sets MMLU apart from other Natural Language Understanding (NLU) benchmarks is its distinct focus on evaluating specialized knowledge. While benchmarks like SuperGLUE primarily assess basic language understanding, MMLU delves deeper, challenging models to demonstrate expertise in specific fields, thus offering a more nuanced and demanding evaluation of a model's capabilities.
TruthfulQA
TruthfulQA is a sophisticated benchmark designed to assess the veracity and accuracy of language models' responses. This rigorous evaluation tool comprises 817 carefully crafted questions spanning 38 diverse categories, including health, law, finance, and politics. The primary objective of TruthfulQA is to gauge a model's capacity to generate truthful and reliable answers, a critical factor in applications where precision and trustworthiness are paramount.
The benchmark employs a two-stage evaluation process. Initially, the language model generates responses to the given questions. Subsequently, it faces a series of multiple-choice questions, requiring true or false selections. These choices are meticulously tallied to quantify performance. Human evaluators then score each model-generated response, with the final score reflecting the proportion of truthful outputs.
TruthfulQA's significance is underscored by the performance of even advanced models like GPT-3, which achieved only a 58% success rate. This modest result highlights the inherent challenges in consistently producing truthful responses and emphasizes the ongoing need for improvement in this crucial aspect of language model development.
Evaluating Model Performance
Evaluating model performance is a critical process that involves a comprehensive assessment of an LLM's capabilities across multiple dimensions. This section delves into the intricacies of performance evaluation, focusing on:
-
The crucial role of standardized benchmarks in ensuring consistent and comparable assessments across different models and research efforts.
-
Essential metrics used to quantify various aspects of model performance, including accuracy, fluency, coherence, and task-specific measures.
-
The synergistic relationship between automated evaluation techniques and human judgment, highlighting how this combination provides a more nuanced and holistic understanding of a model's strengths and limitations.
-
Emerging evaluation methodologies that aim to capture more subtle aspects of language model performance, such as reasoning ability, factual consistency, and ethical considerations.
By exploring these key areas, we aim to provide a thorough understanding of the multifaceted approach required to effectively evaluate and compare the performance of large language models in today's rapidly evolving AI landscape.
Key Metrics for Evaluation
Key evaluation metrics for LLMs encompass a range of sophisticated measures designed to assess various aspects of model performance. Accuracy, a fundamental metric, quantifies the model's ability to make correct predictions by calculating the ratio of accurate predictions to total predictions. Speed evaluates the model's efficiency in processing and generating responses, crucial for real-time applications. Grammar and readability metrics assess the linguistic quality and comprehensibility of the model's outputs, while unbiasedness measures ensure fair and equitable performance across diverse topics and demographics.
Advanced metrics further refine the evaluation process. The BLEU (Bilingual Evaluation Understudy) score assesses text fluency and coherence, particularly valuable in translation tasks. METEOR (Metric for Evaluation of Translation with Explicit ORdering) provides a nuanced measure of accuracy and relevance, considering synonyms and paraphrases. ROUGE (Recall-Oriented Understudy for Gisting Evaluation) evaluates the similarity between model-generated text and reference texts, offering insights into summarization capabilities.
For question-answering tasks, the F1-score stands out as a critical metric. It harmoniously balances precision (the proportion of correct answers among retrieved answers) and recall (the proportion of correct answers retrieved from all possible correct answers). This comprehensive measure provides a robust evaluation of a model's question-answering proficiency, ensuring that LLMs not only provide accurate responses but also capture a wide range of relevant information. These meticulously designed metrics collectively form a rigorous framework for validating and comparing LLM performance across diverse linguistic and cognitive tasks.
Automated vs. Human Evaluation
Automated evaluation methods excel in rapidly processing extensive datasets, delivering consistent results and significantly reducing evaluation time. These methods leverage algorithms to assess various aspects of language model performance, such as accuracy, fluency, and coherence. However, they often fall short in detecting subtle, human-like errors or nuances in language use that require contextual understanding or cultural knowledge.
Human evaluation, on the other hand, provides invaluable insights into the qualitative aspects of language model outputs. Evaluators can assess factors like relevance, creativity, and appropriateness of responses in ways that automated systems currently cannot. This approach, while offering a depth of analysis unmatched by automated methods, is inherently time-consuming and can be subject to individual biases and inconsistencies across evaluators.
The ideal evaluation strategy strikes a balance between automated and human methods, leveraging the strengths of each approach. Automated evaluations serve as an efficient first pass, identifying broad patterns and performance metrics. Human evaluations then complement these findings by providing nuanced feedback on specific examples, capturing subtleties in language use, and assessing the model's ability to generate contextually appropriate and culturally sensitive responses. This combined approach ensures a comprehensive and robust assessment of language model performance, addressing both quantitative metrics and qualitative aspects of language generation.
AI Teams building with Klu.ai use Feedback to log user preference and behaviors to generations. Additionally, Klu automatically labels helpfulness, sentiment, and more.
Combining Quantitative and Qualitative Analysis
A comprehensive evaluation of LLM performance necessitates a balanced approach that integrates quantitative analysis metrics with qualitative insights. This methodology ensures a thorough assessment of the model's capabilities across various dimensions. Consistency, a critical metric in this evaluation framework, measures the model's ability to generate nearly identical responses to similar prompts, thus ensuring reliability and predictability in its outputs.
The synergy of automated metrics and human evaluation proves invaluable in capturing the full spectrum of an LLM's performance. While automated metrics provide objective, scalable measurements of performance aspects such as accuracy, speed, and linguistic correctness, human evaluation delves into the subjective nuances of language use, contextual appropriateness, and creative expression. This dual approach allows for a nuanced understanding of both the quantifiable aspects of performance and the qualitative elements that define human-like text generation.
By combining these methodologies, evaluators can construct a comprehensive performance profile that encompasses not only statistical measures but also the subtle intricacies of language use that resonate with human readers. This holistic evaluation strategy provides stakeholders with a robust understanding of an LLM's strengths, limitations, and potential areas for improvement, ultimately guiding more informed decisions in model development and deployment.
Limitations of Current LLM Benchmarks
While current LLM benchmarks play a crucial role in assessing model performance, they face significant challenges that limit their effectiveness. Two primary limitations stand out: restricted scope and short lifespan. The narrow focus of many benchmarks often fails to capture the full range of an LLM's capabilities, particularly emerging skills in rapidly evolving models. Additionally, the accelerated pace of AI advancement quickly renders benchmarks obsolete, necessitating frequent updates or replacements. These constraints not only hinder the comprehensive evaluation of language models but also impede our ability to track and measure the rapid progress in the field. Understanding these limitations is essential for developing more robust and adaptable evaluation methods that can keep pace with the dynamic landscape of AI and language model development.
Scope and Relevance
The restricted scope of current LLM benchmarks presents a significant challenge in accurately assessing the full spectrum of capabilities in advanced language models. These benchmarks often fall short in evaluating emerging and unforeseen skills, particularly at an advanced professional level. Their narrow focus tends to concentrate on areas where models have already demonstrated proficiency, leaving potential new capabilities unexplored and unassessed.
This limitation is particularly evident in complex, open-ended scenarios such as chatbot assistance. The multifaceted nature of conversational AI, with its requirement for contextual understanding, nuanced responses, and adaptability, often exceeds the scope of traditional benchmarks. Consequently, these evaluation methods may provide an incomplete or potentially misleading assessment of a model's true performance and potential. This gap between benchmark capabilities and the evolving landscape of AI underscores the need for more comprehensive, flexible, and forward-looking evaluation methodologies that can keep pace with rapid advancements in language model technology.
Short Life Span
The rapid advancement of language models presents a significant challenge for benchmarking, as these evaluative tools quickly become obsolete. This phenomenon, known as benchmark saturation, occurs when models achieve or surpass human-level performance on existing tests. Consequently, the AI research community must continually develop more sophisticated and challenging benchmarks to accurately assess and drive progress in language model capabilities.
This cycle of benchmark creation, model improvement, and subsequent obsolescence is exemplified by the HellaSwag dataset. Introduced in 2019, HellaSwag initially posed a formidable challenge to state-of-the-art models, which struggled to achieve even 45% accuracy. However, the swift progress in language model development, coupled with advanced fine-tuning techniques, rapidly rendered HellaSwag and similar benchmarks outdated. This accelerated obsolescence underscores the need for dynamic, adaptable evaluation methods that can keep pace with the exponential growth in language model capabilities.
To address this issue, researchers and developers must adopt a proactive approach to benchmark design. This involves creating multi-faceted, scalable evaluation frameworks that can evolve alongside language models, incorporating increasingly complex tasks and nuanced performance metrics. By doing so, the AI community can ensure that benchmarks continue to provide meaningful insights into model performance and drive innovation in the field of natural language processing.
Customizing LLM Benchmarks
While standard benchmarks provide valuable insights into general LLM performance, they often fall short in addressing the unique requirements of specific use cases. This limitation necessitates the development of custom benchmarks tailored to particular applications and industries. By customizing LLM benchmarks through innovative techniques such as synthetic data generation and carefully defined evaluation protocols, organizations can ensure that their evaluation metrics are not only relevant but also precisely aligned with their specific tasks and objectives. This approach enables a more accurate assessment of LLM capabilities in real-world scenarios, ultimately leading to more effective model selection and deployment strategies.
Creating Synthetic Data
Synthetic data generation, leveraging advanced models like GPT-4, offers a sophisticated approach to creating custom benchmarks without the need for manual data collection or annotation. This method proves particularly valuable in crafting tailored evaluation datasets that address specific use cases while maintaining long-term relevance. By employing data evolution techniques such as in-depth and in-breadth evolving, researchers can significantly enhance the complexity and diversity of synthetic data, thereby ensuring a comprehensive and nuanced evaluation process.
The generation of synthetic data empowers researchers to develop unique, task-specific evaluation datasets with unprecedented efficiency. This approach not only substantially reduces the time and financial resources typically associated with dataset creation but also ensures a high degree of domain relevance and longevity. Consequently, synthetic data generation emerges as a powerful tool in the ongoing effort to create more accurate, adaptable, and enduring benchmarks for assessing the performance of large language models across a wide spectrum of applications.
Defining Evaluation Protocols
Defining robust evaluation protocols is crucial for accurately assessing LLM performance. This process begins with establishing clear, measurable objectives and carefully selecting metrics that align with specific tasks and use cases. The evaluation datasets should closely mirror real production data, ensuring that the assessment accurately reflects the challenges customers will encounter in practical applications.
The evaluation of LLM prompts involves two steps. First, create an LLM evaluation metric benchmark by establishing a dedicated LLM-based eval to label data as effectively as a human-labeled "golden dataset." Benchmark your metric against this eval. Then, run this LLM evaluation metric against your LLM application results.
To create comprehensive evaluation datasets, it's essential to prioritize tasks that typically challenge models, as these areas often reveal critical performance gaps. Additionally, incorporating high-value examples from key customers provides insights into the model's effectiveness in addressing crucial business needs. A particularly effective approach is the development of Gold Standard Questions (GSQs), which are meticulously crafted datasets derived from proprietary information tailored to specific use cases. While GSQs offer unparalleled relevance and depth in evaluation, it's important to acknowledge that their creation can be a resource-intensive process, requiring significant time and expertise to ensure accuracy and comprehensiveness.
By focusing on these elements, organizations can develop evaluation protocols that not only assess current model capabilities but also drive continuous improvement in areas most critical to their operational success and customer satisfaction.
Latest Developments in LLM Benchmarking
The rapid pace of innovation in large language models (LLMs) has led to significant developments in LLM benchmarking. Notable models like LLaMa, Pythia, and MPT have been released, showcasing advancements in model performance and efficiency,.
This section explores new benchmarking frameworks, existing benchmarks, and future directions in LLM benchmarking.
New Benchmarking Frameworks
To evaluate and optimize LLM-powered applications, it is essential to create an evaluation dataset, define passing criteria for each metric, and use appropriate evaluation frameworks.
Some innovative evaluation methods include RAGAS, which evaluates LLM retrieval based on various metrics like faithfulness, relevancy, and harmfulness, and Klu.ai, a platform for iterating, testing, evaluating, and monitoring LLM applications.
DeepEval is an open-source LLM evaluation framework that simplifies the benchmarking process. BigBench Hard (BBH) introduced Chain-of-Thought (CoT) prompting, which enhances the performance of LLMs on challenging tasks, demonstrating the continuous evolution of benchmarking frameworks.
Future Directions
The evolution of general foundation models is expected to significantly expand their capabilities beyond text-based tasks. These advancements will encompass a broader range of modalities, including code understanding and generation, visual content processing, and audio analysis. As these models progress, they will not only extend their reach across diverse domains but also deepen their knowledge and proficiency within each area.
Concurrently, there is a growing emphasis on integrating LLMs with various tools and platforms to enhance their accessibility and practical application in everyday scenarios. This integration aims to bridge the gap between advanced AI capabilities and user-friendly interfaces, making powerful language models more readily available to a wider audience.
Looking ahead, the development of future LLM benchmarks must prioritize domain relevance to effectively align with specific applications such as legal analysis or medical interpretation. By focusing on domain-specific benchmarks, researchers can ensure that LLMs are rigorously evaluated against the unique challenges and requirements of various industries. This targeted approach will lead to more accurate assessments of model performance in specialized contexts, ultimately driving the development of LLMs that can meet the diverse and complex needs of different sectors.
Summary
Platforms like Klu.ai streamline LLM App Evaluation with features for prompt engineering, semantic search, version control, testing, and performance monitoring. These systems utilize various tools and methods for evaluation, fine-tuning, and deployment.
To evaluate and optimize LLM-powered applications, it is essential to create an evaluation dataset, define passing criteria for each metric, and use appropriate evaluation frameworks.
This comprehensive exploration of large language model evaluation has delved into the nuanced process of benchmarking. We've examined the critical role benchmarks play in quantifying model performance, dissected various benchmark types, and highlighted popular tools employed by researchers and practitioners.
Our analysis has also uncovered the inherent limitations of existing benchmarks and emphasized the necessity for tailored evaluation methods to address specific use cases and domains.
The continuous evolution of LLMs demands equally sophisticated and adaptable benchmarking techniques. As we push the boundaries of language model capabilities, it becomes imperative to develop and refine robust, multifaceted evaluation frameworks.
These advanced benchmarks must accurately gauge not only the general performance of models but also their proficiency in specialized tasks and domains.
By leveraging such comprehensive evaluation methods, we can drive the development of more powerful, efficient, and versatile language models that effectively meet the diverse and ever-changing requirements of real-world applications.
Frequently Asked Questions
Why are LLM benchmarks important?
LLM benchmarks play a crucial role in the advancement of artificial intelligence by providing a standardized framework for evaluating and comparing language models.
These benchmarks enable organizations to assess the performance of different models across various tasks, facilitating informed decision-making in model selection and development.
Benchmarks offer quantifiable metrics that drive innovation, encourage model improvements, and foster competition in AI. This accelerates progress in language model technology through collaborative efforts and continuous refinement.
What are the limitations of current LLM benchmarks?
Current LLM benchmarks face several significant limitations that impact their effectiveness. Firstly, their scope is often restricted, focusing on specific aspects of language understanding while potentially overlooking other critical capabilities.
Secondly, the rapid pace of advancements in language models leads to a short lifespan for many benchmarks, as they quickly become outdated. This rapid obsolescence means that benchmarks may fail to effectively evaluate emerging skills in cutting-edge models.
Additionally, many benchmarks struggle to capture the nuances of real-world applications, potentially providing an incomplete picture of a model's practical performance. Lastly, there's a risk of overfitting, where models are optimized for specific benchmarks rather than general language understanding and generation.
How can LLM benchmarks be customized?
Customizing LLM benchmarks involves a multifaceted approach to create more relevant and task-specific evaluation metrics. One effective method is utilizing synthetic data generation techniques to produce diverse and representative datasets that closely mirror real-world scenarios. This approach allows for the creation of benchmarks that are tailored to specific domains or use cases.
Additionally, defining robust evaluation protocols is crucial, involving the careful selection of metrics that align with the intended application of the model. Organizations can also incorporate domain-specific knowledge and edge cases into their benchmarks to ensure comprehensive evaluation.
By combining these strategies, it's possible to develop customized benchmarks that provide more accurate and meaningful assessments of LLM performance for particular needs and contexts.