What is LLM Evaluation?
LLM Evaluation is the systematic assessment of Large Language Models (LLMs) to determine their performance, reliability, and effectiveness in various applications. For most engineers, the evaluation is on the model responses to prompts.
Evals are vital for identifying the strengths and weaknesses of LLM prompts, guiding deployment and iteration decisions.
The evaluation process includes performance assessment on various tasks, generalization analysis, robustness evaluation against adversarial attacks, and bias, fairness, and ethical considerations.
Evaluations measure an LLM's performance in generating accurate, fluent, and context-relevant responses, pinpointing its capabilities and areas for improvement.
There are several methods and metrics used in holistic LLM evaluation:
-
System Evaluation — Evaluates system components under your control, such as prompts and context, assessing input-output determination efficiency, model perplexity, or retrieval relevancy.
-
Human Evaluation — Assesses outputs, by domain expert or representative end user, integrating subjective, evaluator opinions into preference-based evals. Manual assessment by humans to measure quality and performance, considering aspects like fluency, coherence, creativity, relevance, and fairness.
-
Benchmarking — Evaluates models on specific tasks using predefined metrics, ranking comparable models based on performance.
-
Engagement & Retention — Measures user engagement with LLM features, interaction quality, and second-order metrics. Retention measures feature or app stickiness, comparing AI-activated cohorts.
-
LLM-as-a-Judge — Uses another LLM to evaluate the tested model's outputs, reflecting human preferences for certain use cases.
To build a comprehensive evaluation, combine several measures to build a full evaluation snapshot. Use both qualitative and quantitative measurements to capture stated and revealed preferences for system optimization.
LLM Evaluation can be conducted using different methods, including:
- Domain-Specific Datasets — Using datasets relevant to a particular industry or application to assess performance.
- Adversarial Testing — Evaluating robustness against adversarial attacks to test resilience to various adversarial inputs.
- Prompt and Context Evaluation — Assessing how well inputs (prompts) determine outputs, which may involve changing the prompt template while holding the LLM constant.
- Automated Metrics — Utilizing libraries and tools such as Klu.ai or the OpenAI Eval library, which includes metrics like HellaSwag, TruthfulQA, and MMLU.
Evaluating LLMs is essential for enhancing their alignment with human values and ensuring their utility, safety, and fairness. This evaluation is also key to choosing the best model for specific applications and is a core aspect of LLMOps, which focuses on LLM development and optimization.
Existing evaluation methods may not fully capture the diversity and creativity of LLM outputs, as they often focus solely on accuracy and relevance.
Furthermore, be skeptical of standardized benchmarks, as these methods typically rely on specific benchmark datasets or tasks, which may not accurately represent real-world use.
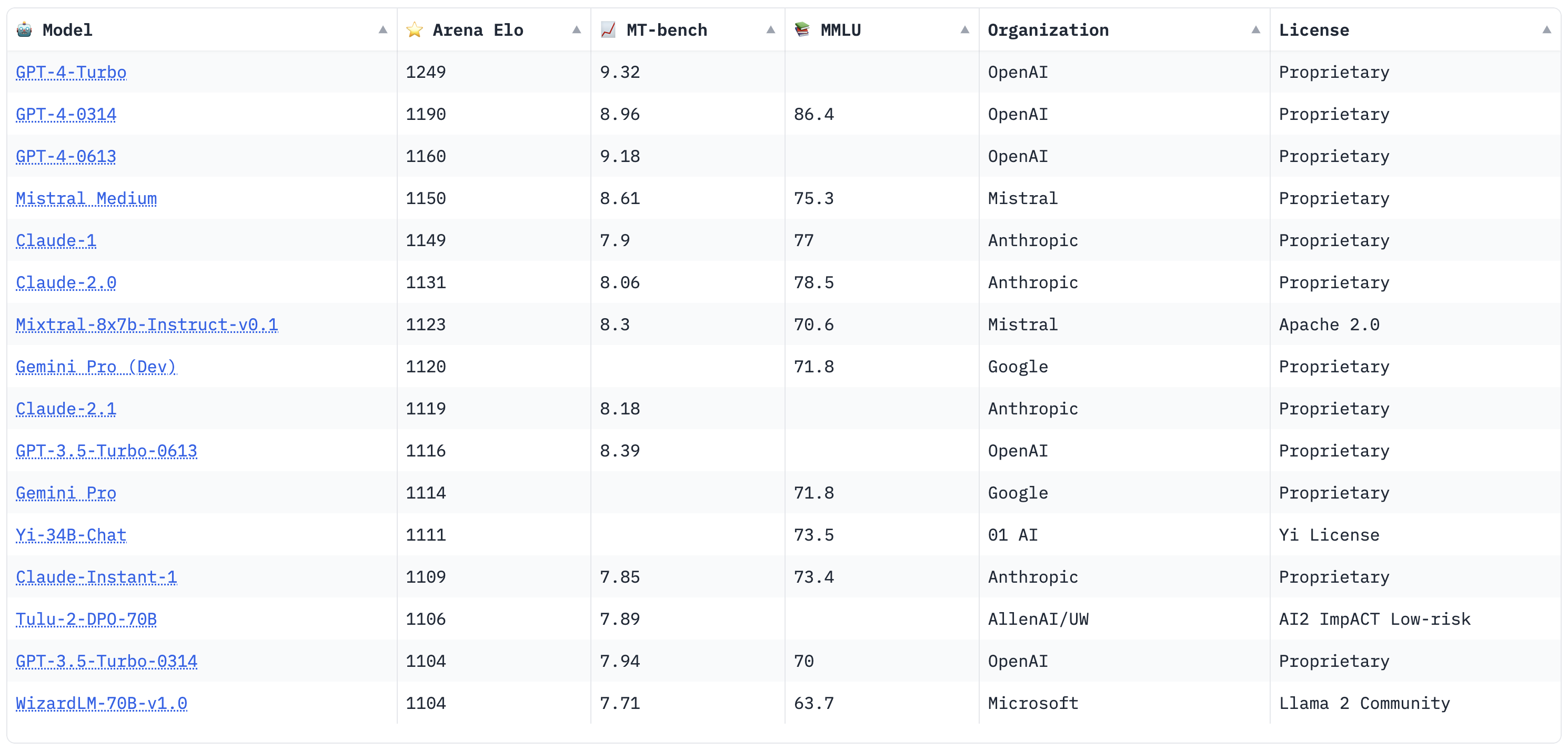
Based on leading eval benchmarks, how do LLMs rank in 2024?
Based on the leading evaluation benchmarks for 2024, the clear leader among LLMs is GPT-4o. With the highest Arena Elo rating of 1287 and an impressive MT Bench score of 9.32, it outperforms other models in both human preference and LLM-as-a-judge evaluations.
The above models are evaluated based on their performance on the Chatbot Arena Elo, MT-bench, AlpacaEval 2, and MMLU benchmarks. Chatbot Arena Elo is a head-to-head human prefence ranking, while MT-bench is an LLM-as-a-judge eval, AlpacaEval is a head-to-head LLM preference ranking, and MMLU benchmarks reading comprehension.
Ranking last updated July 19, 2024
Deep Dive Benchmarks
Want to learn more? Dive into in-depth benchmarks that thoroughly analyze specific evaluation metrics and methodologies for assessing the performance of large language models (LLMs). These benchmarks provide valuable insights into the strengths and weaknesses of LLMs across a range of specialized tasks and domains.
How does LLM Evaluation work?
Large Language Models (LLMs) evaluation involves appraising factors like language fluency, coherence, contextual understanding, factual accuracy, and the ability to generate relevant and meaningful responses.
To evaluate LLMs, there are several methods and frameworks available, such as:
-
LLM System Evaluation — Platforms like Klu.ai offer automated evaluations using algorithms, code, embeddings, human feedback, or LLM-as-a-judge feedback to streamline the evaluation workflow. This is a complete evaluation of components that you have control of in your system, such as the prompt (or prompt template) and context. LLM system evaluations assess how well your inputs can determine your outputs. The outcome metric for this evaluation depends on what you are trying to evaluate.
-
Human Evaluation — This method involves human judges who assess the quality of the model's outputs based on various criteria. It is considered the gold standard for assessing LLMs as it can capture nuances that automated metrics might miss, providing a comprehensive understanding of a model's performance. However, it can be subjective, prone to bias, and time-consuming, especially for large-scale evaluations.
-
User Engagement and Satisfaction Metrics — These metrics measure how often the user engages with the LLM features, the quality of those interactions, and how likely they are to use it in the future. These metrics are applicable to any LLM and can be built directly from telemetry collected from AI models.
-
Automated Metrics — These include metrics like BLEU or ROUGE, which require reference data for comparison. These metrics are often used in conjunction with other evaluation methods for a more comprehensive assessment of LLM performance.
-
Benchmark Tasks — These include evaluations like AlpacaEval, MT-Bench, GAIA, MMMU, or MMLU, which use standardized questions and answers to assess model performance. These benchmarks are great for showcasing relative LLM performance, but may not fully reflect the challenges of real-world applications. The benchmarks evaluate on a controlled dataset that may not generalize well to diverse and dynamic scenarios where LLMs are deployed.
Combining these evaluation methods creates a more accurate picture of the model's performance and highlights areas for improvement. The choice of evaluation method for LLMs depends on factors like cost and accuracy, however establishing robust evaluation procedures is crucial for any LLM-based system, and it's advisable to gather task-specific evaluations such as prompt, context, and expected outputs for reference.
What's the difference between online and offline LLM evals?
Evaluating Large Language Models (LLMs) involves both online and offline methods. Online evaluation measures LLMs in production with real user data, capturing live performance and user satisfaction through direct and indirect feedback. It's conducted on logs from live production, with evaluators set to run automatically with new log entries.
Offline evaluation tests LLMs against specific datasets, often within a continuous integration (CI) environment, to ensure features meet performance standards before deployment. This method is ideal for assessing aspects like tone and factuality and can be automated within development pipelines.
Online evaluation excels in reflecting the complexity of real-world use and incorporates user feedback, making it ideal for ongoing performance monitoring. Offline evaluation, by contrast, offers a controlled environment for testing and faster iterations, without the need for live data, making it cost-effective and suitable for pre-deployment checks and regression testing.
A combination of both online and offline evaluations provides a robust framework for understanding and improving the quality of LLMs throughout the development and deployment lifecycle.
How do you evaluate LLM App user engagement?
User Engagement & Utility Metrics
Evaluating the utility of LLM features is essential to ensure they provide value that justifies their cost. We use an Overall Evaluation Criteria (OEC) for product-level utility assessment and specific usage and engagement metrics for direct impact analysis of LLM features.
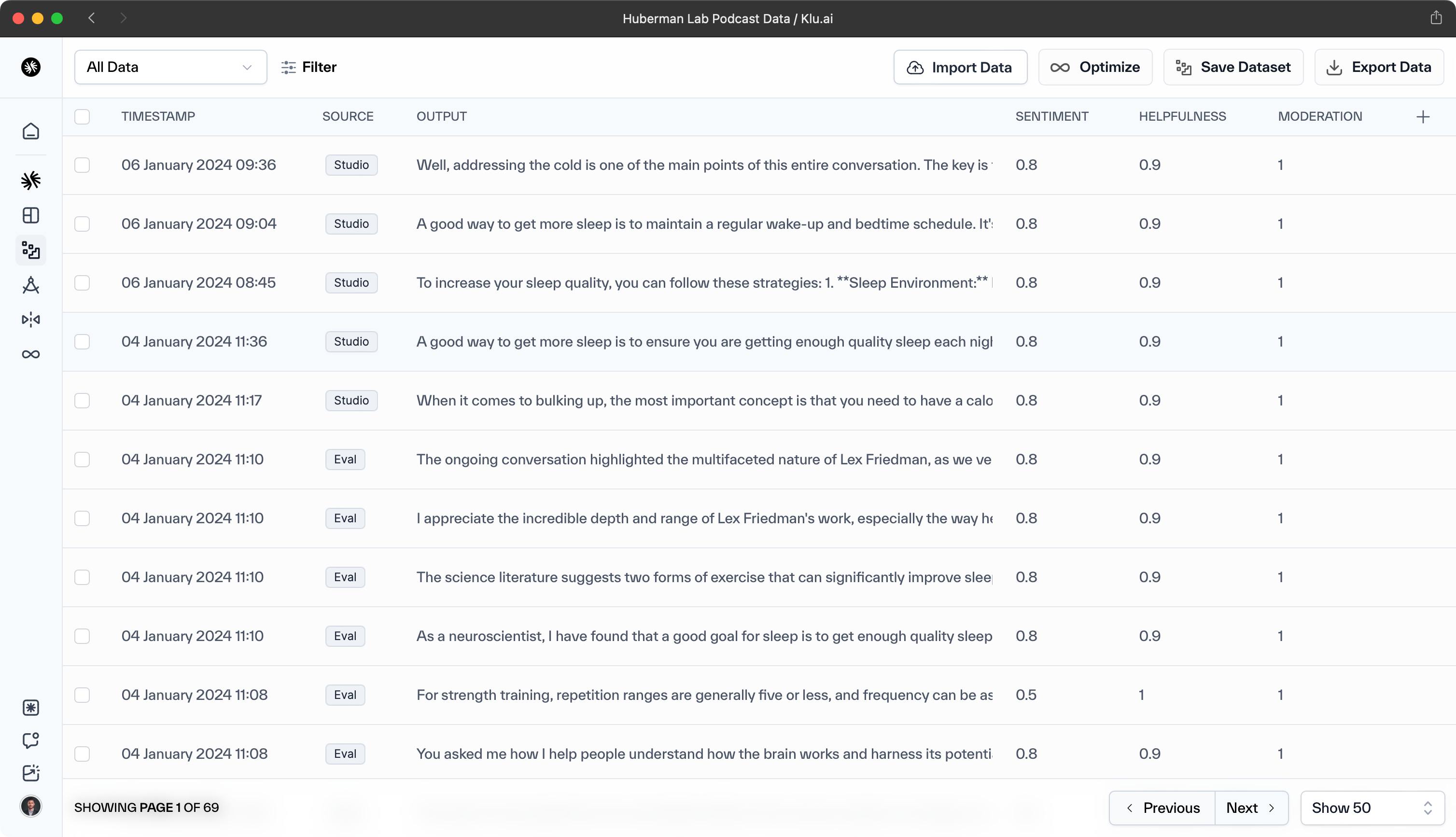
AI Teams building with Klu.ai use Feedback to log user preference and behaviors to generations. Additionally, Klu automatically labels helpfulness, sentiment, and more.
Opportunities and Visibility
- Opportunities to Suggest Content — Total instances where the LLM was called, regardless of user visibility.
- Prompts to LLM — Total number and frequency of prompts made.
- Responses from LLM — Total number and frequency of LLM responses.
- Responses Seen by Users — Total number and frequency of responses displayed to users, accounting for moderation and relevance.
User Interaction
- User Acceptance Rate — Frequency of user acceptance, which varies by context (e.g., text inclusion or positive feedback in conversational scenarios).
- Content Retention — Number and rate of LLM-generated content retained by users after a set period.
Quality of Interaction
- Prompt and Response Lengths — Average lengths of prompts and responses.
- Interaction Timing — Average time between prompts and responses, and time spent on each.
- Edit Distance Metrics — Average edit distance between user prompts and between LLM responses and retained content, indicating prompt refinement and content customization.
Feedback and Retention
- User Feedback — Number of responses with Thumbs Up/Down feedback, noting potential bias due to low response rates.
- Conversation Metrics — Average length and duration of LLM conversations, number of conversations, and active days using LLM features.
- User Retention — Daily active users, retention rate of new users, and first-session feature usage.
Creator Productivity Metrics
- Content Creation Efficiency — Evaluation of content creation speed and quality improvement with LLM assistance.
- Content Reach and Quality
- Number of users and sessions creating content per document.
- Number of documents edited with LLM assistance.
- Total characters retained per user and length of LLM interactions.
- Number of total and user edits, and use of rich content elements like images and charts.
- Editing Effort — Average time spent by users in editing mode.
Consumer Productivity Metrics
- Content Consumption Efficiency — Evaluation of content consumption speed and quality with LLM-edited documents.
- Content Reach and Quality
- Number of users and sessions consuming content per document.
- Number of documents read that were edited with LLM.
- Consumption actions (e.g., sharing, commenting) per AI-edited document.
- Consumption Effort — Average time spent in consumption mode per document per user.
User Engagement and Satisfaction
We track user interaction frequency with LLM features, the interaction quality, and the likelihood of future use.
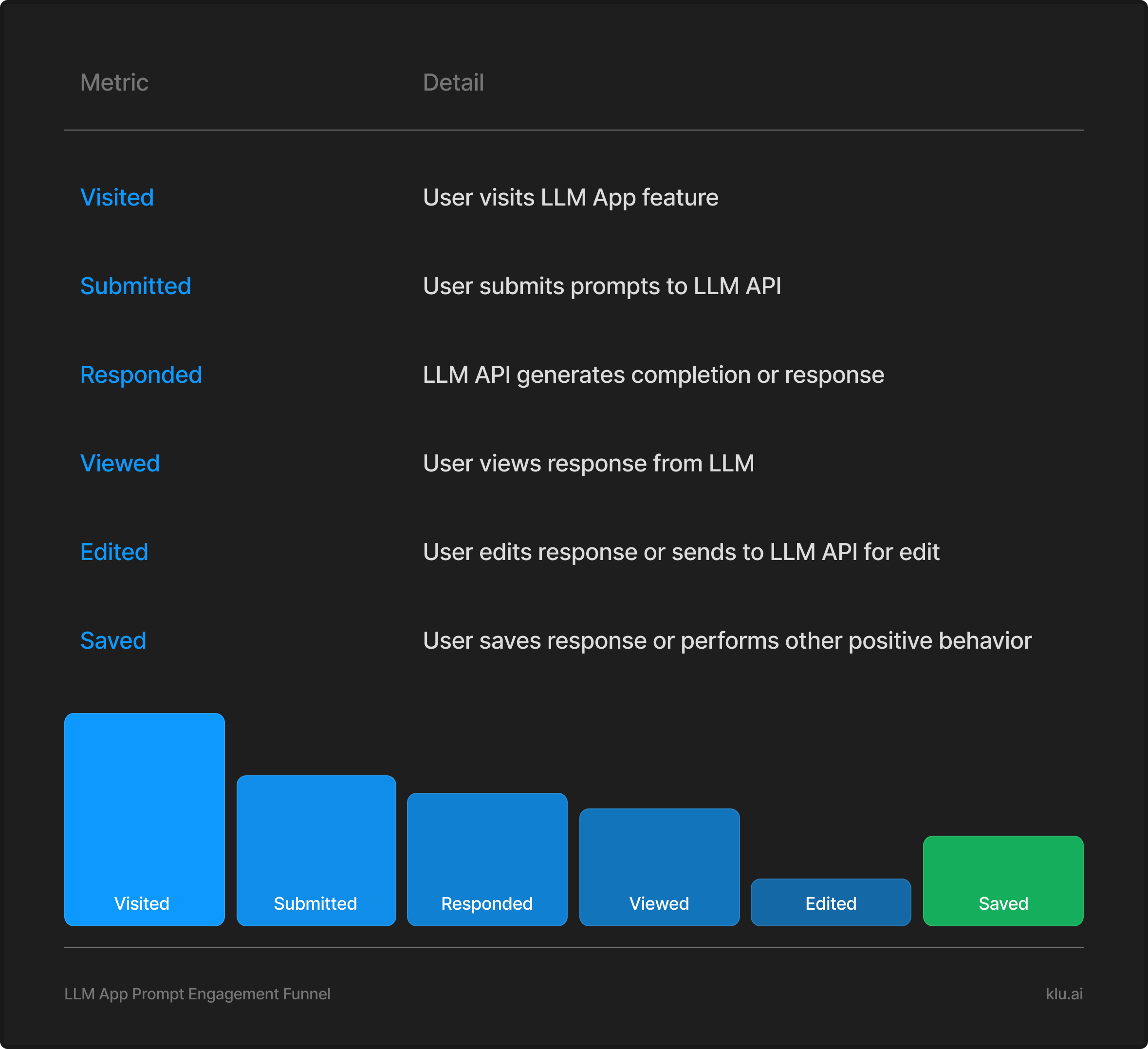
Prompt and Response Funnel
We analyze user interaction stages with the LLM, from prompt submission to response acceptance or rejection. This helps us understand the response's usefulness and the user's application of it in their task.
Prompt and Response Quality
Engagement quality is crucial. We evaluate successful interactions by examining prompt and response lengths, the average edit distance between prompts, and user ratings (Thumbs Up/Thumbs Down) to gauge response quality. Detailed metrics descriptions are available in the appendix.
Retention Metrics
We measure feature retention to identify any novelty effects where engagement drops after initial use. Product-specific retention metrics can be adapted for LLM features. See the appendix for our retention metrics.
Productivity in Collaborative Scenarios
In collaborative settings where AI-generated content is shared, we assess productivity improvements on both creation and consumption sides. These metrics help quantify the collaborative value added by the AI content.
How do you evaluate API Utilization?
To assess LLM cost-efficiency, we measure API Utilization based on token usage. Tokens represent pieces of words and are the basic units for natural language processing.
With OpenAI models, a token approximates 4 characters or 0.75 words of English text. The tokenization process converts prompts into prompt tokens and the generated output into completion tokens. Each forward pass of an LLM produces one token, thus the total forward passes equal the number of completion tokens.
Key API Utilization Metrics
We track the following key metrics for API Utilization:
- 429 Error Responses — The count of 429 errors indicates service overload. For peak performance assessment, focus on the 95th or 90th percentile of these errors.
- Total Token Count — Sum of prompt and completion tokens, serving as the primary metric for API Utilization. OpenAI's billing is based on this total token count.
API Utilization Metrics
Token Metrics
-
Total Token Count — Sum of prompt and completion tokens, the primary metric for API Utilization. Billing is based on this count.
-
Prompt Tokens — Tokens from the prompt input. These are less expensive and can be optimized.
-
Completion Tokens — Tokens generated as responses. These are the main cost factor and can be controlled via the Max_Tokens parameter.
Inefficiencies
-
Wasted Utilization — Track completion tokens from non-actionable responses to minimize waste.
-
Truncated Responses — Monitor responses with finish_reason : length to identify potential truncation due to reaching the max_tokens limit.
How do you evaluate AI Alignment & Safety?
Responsible AI ensures the ethical, safe, and trustworthy use of AI systems. It focuses on positive empowerment and fair societal impact.
Responsible AI is essential as LLMs scale up. OpenAI offers tools to assess LLM features and applications across quality, safety, and performance. These tools are crucial for minimizing user risks and ensuring a positive experience throughout the deployment lifecycle.
Content Filtering Metrics
The Azure OpenAI Content Filtering system identifies and mitigates prompts and responses that violate Responsible AI principles. It provides annotations and properties in the OpenAI API, which inform the following metrics:
- HTTP 400 Errors — The percentage of prompts classified within a specific filtered category and severity level.
- Content Filter Terminations — The percentage of responses halted by the content filter, indicated by the “finish_reason”: “content_filter”.
These annotations also enable detailed statistics for each filtering category, shedding light on the extent of specific filtrations.
How do you evaluate LLM API performance?
Performance Metrics
Evaluating LLM API performance involves measuring latency and throughput to ensure efficient user interactions. It's important to track latency at each layer of the LLM interaction and for any additional components in the workflow.
Latency Metrics
- Time to first token — Measures the duration from user prompt submission to the first token's appearance, assessed at various percentiles.
Throughput Metrics
- Requests Per Second (RPS) — Tracks the number of requests processed by the LLM per second.
- Tokens per second — Counts the tokens rendered per second during LLM response streaming.
What data is needed for evaluating human preferences and metrics?
For LLM applications without Klu, manually collect human feedback and system telemetry data.
Data Collection for Metrics
To calculate metrics, it's necessary to gather relevant data from the OpenAI API response. Additionally, capturing the end user's identifier from the product telemetry is crucial for passing it to the API. Klu automatically provides data.
Telemetry for User and LLM Edits
For features where the LLM directly modifies user text, telemetry should distinguish between user and LLM edits. This distinction is vital to accurately measure any reduction in user-generated content when the LLM provides auto-completions. Klu provides methods for capturing both.
How do you evaluate LLM App success?
A/B Testing for LLM Features
A/B testing is essential for measuring the impact of LLM features. It helps in making informed decisions about product changes by using the metrics discussed previously.
Launching an LLM Feature
It's crucial to ensure the feature is performant and reliable at launch, optimizing for productivity while considering cost-benefit tradeoffs.
Dark Feature Flag Experiment
Before making the feature visible to users, conduct a dark flag experiment. This involves loading the feature's components without user visibility to confirm performance and reliability. We recommend setting the feature flag on for internal users for dog fooding.
Zero to One Experiment
In a Zero to One experiment, the treatment group has the LLM feature, while the control group does not. Implement a controlled rollout to monitor GPU capacity and ensure product metrics remain stable, while looking for improvements in productivity. We recommend starting with an optimal test group that enables you to learn, but mitigates any potential risks. Once metric stability is confirmed, gradually increase the rollout to additional segments until dialing up to 100%.
Post-Launch Optimization
Post-launch, continue refining the feature to meet customer needs. This includes prompt optimization, integrating newer models, and enhancing the user experience.
Shadow Experiment
Shadow experiments measure the impact of changes without user exposure. They involve generating both treatment and control responses from user input but only displaying the control. This allows for sensitive metric comparison without affecting user experience. Metrics like GPU utilization, performance, latency, and prompt metrics can be measured, but those requiring user interaction cannot.
1-N Experiment
Regular A/B testing, or 1-N experiments, assess changes to the product, including LLM features. For best practices, refer to our guides on trustworthy experimentation throughout the experiment lifecycle.
What is a typical LLM Eval workflow?
LLM evaluation systematically assesses an LLM's performance, reliability, and effectiveness across applications. This process includes benchmarking, metric computation, and human evaluation.
-
Establish a Benchmark — The first step in LLM evaluation is to establish a benchmark for your LLM evaluation metric. This involves creating a dedicated LLM-based evaluation system whose task is to label data as effectively as a human labeled your "golden dataset".
-
Choose an LLM for Evaluation — Decide which LLM you want to use for evaluation. This could be a different LLM from the one you are using for your application. The choice is often influenced by factors such as cost and accuracy.
-
Test the LLM Eval — At this point, you should have both your model and your tested LLM evaluation system. You have proven to yourself that the evaluation system works and have a quantifiable understanding of its performance against the ground truth.
-
Run the LLM Eval on Your Application — Now you can actually use your evaluation system on your application. This will help you measure how well your LLM application is doing and figure out how to improve it.
-
Continuous Improvement — Regular LLM-based evaluations foster continuous improvement, as developers can identify performance trends and track improvements over time.
For a thorough LLM evaluation, use diverse datasets and real-world application evaluations. Regularly update benchmarks, correct biases, and provide continuous feedback.
What are some best practices for LLM Evaluation?
For effective LLM evaluation, adopt a thorough and precise approach to ensure reliability, trustworthiness, and impact.
-
LLMs as Judges — Use advanced LLMs like GPT-4 to evaluate other LLMs' outputs. Platforms like Klu.ai offer this capability for AI teams to easily get human-preference level feedback.
-
Factor Consideration — Evaluate LLMs by considering a wide range of factors, from technical traits to ethical nuances, to ensure high-quality outputs and societal alignment.
-
System Evaluation — Evaluate controllable system components like the prompt and context. The evaluation metric depends on the specific aspect being assessed.
-
Human Evaluation — Despite potential bias, human evaluation is crucial for capturing nuances that automated metrics may miss, offering a comprehensive performance assessment.
-
Multiple Metrics — Use various evaluation metrics like BLEU or ROUGE for a holistic assessment of LLM performance.
-
Elo Rating System — Use the Elo rating system for "A vs B" comparisons. However, due to the volatility of individual Elo computations, steps should be taken to ensure the robustness of the ranking system.
-
Component-specific Datasets — Create an evaluation dataset for each LLM system component for the most reliable evaluation.
A holistic LLM assessment requires diverse datasets and evaluations that mirror real-world applications. Updated benchmarks, bias correction, and continuous feedback are essential components.
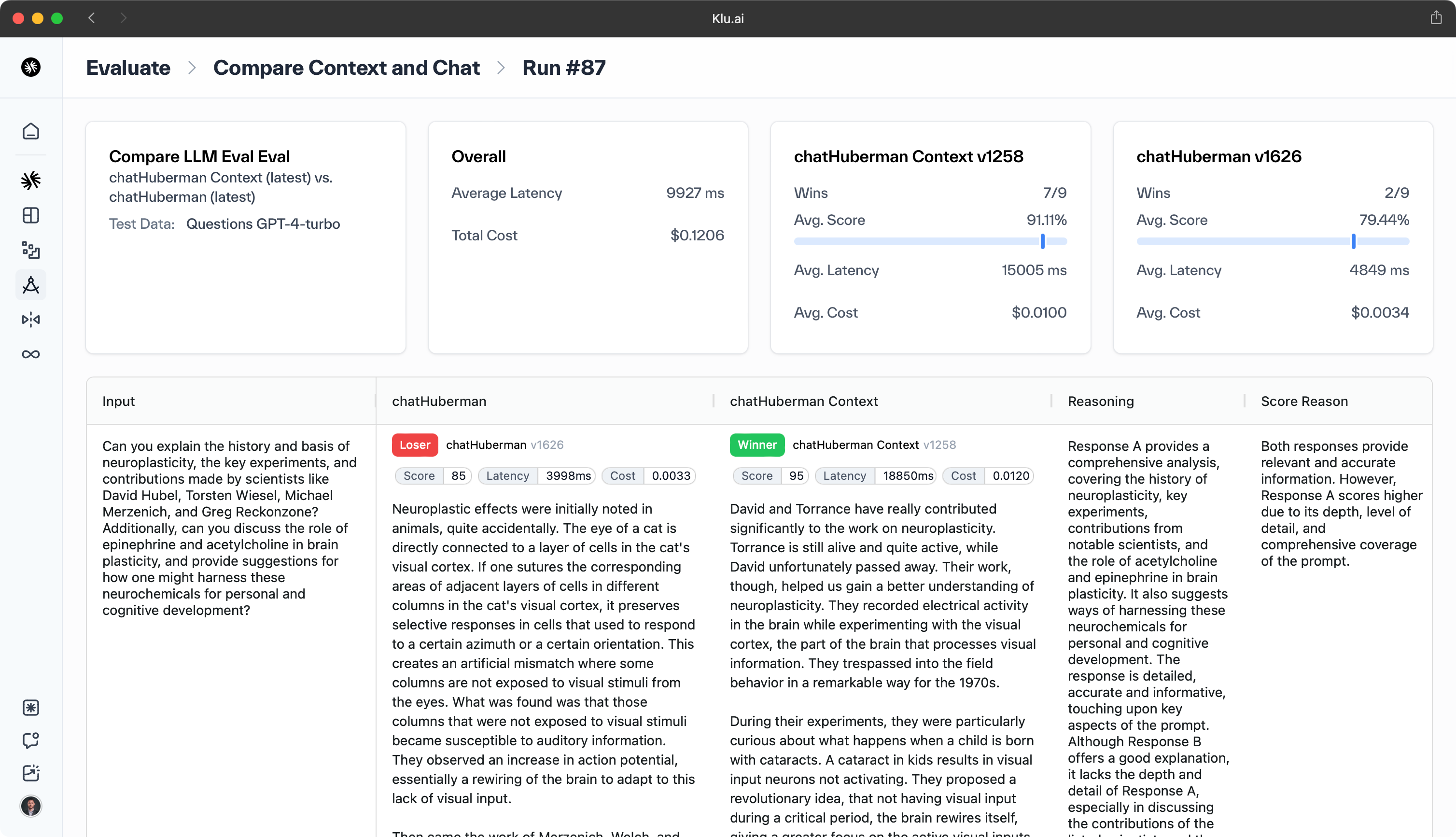
How do you evaluate prompts?
Prompt evaluation is crucial for Large Language Models (LLMs) as it significantly influences the output. This evaluation is divided into LLM Model Evaluation and LLM App Evaluation.
Platforms like Klu.ai streamline LLM App Evaluation with features for prompt engineering, semantic search, version control, testing, and performance monitoring. These systems utilize various tools and methods for evaluation, fine-tuning, and deployment.
The evaluation of LLM prompts involves two steps. First, create an LLM evaluation metric benchmark by establishing a dedicated LLM-based eval to label data as effectively as a human-labeled "golden dataset." Benchmark your metric against this eval. Then, run this LLM evaluation metric against your LLM application results.
Tools like Klu.ai assist in LLM Prompt Evaluation. We suggest using a representative user input sample to reduce subjectivity in prompt tuning. Klu.ai provides a web platform to analyze test case improvements or declines.
Due to the unpredictability of LLM-generated prompt quality, ensuring the quality of these prompts is essential for reliable outputs.
What are the applications of LLM Evaluation?
Large Language Models (LLMs) have various applications in different domains, and evaluating their performance is crucial for building robust applications. Some applications of LLM evaluation include:
-
Performance assessment — Evaluating LLMs based on metrics like accuracy, fluency, coherence, and subject relevance is essential for understanding their capabilities and limitations.
-
Model comparison — Comparing the performance of different LLMs on specific tasks helps researchers and practitioners identify the state-of-the-art models and track progress over time.
-
Bias detection and mitigation — Evaluating LLMs for fairness, transparency, and other dimensions helps ensure that they do not exhibit unwanted biases or behaviors.
-
User satisfaction and feedback — Collecting user feedback and evaluating LLM-generated responses based on creativity, brand tone, appropriateness, and other dimensions helps improve the user experience.
-
Continuous evaluation — Identifying unsatisfactory outputs, marking them for reproducibility, and adding them to the evaluation dataset helps build a robust LLM application.
To evaluate and optimize LLM-powered applications, it is essential to create an evaluation dataset, define passing criteria for each metric, and use appropriate evaluation frameworks.
Some innovative evaluation methods include RAGAS, which evaluates LLM retrieval based on various metrics like faithfulness, relevancy, and harmfulness, and Klu.ai, a platform for iterating, testing, evaluating, and monitoring LLM applications.
Auto-evaluation approaches, such as LLM-as-a-judge, can also be used to compare LLM performance with human grading.
How is LLM Evaluation impacting AI?
Large Language Models (LLMs) are significantly impacting the field of Artificial Intelligence (AI) and have the potential to transform various industries. Some of the key impacts of LLMs on AI include:
-
Enhancing conversational abilities — LLMs can improve the conversational capabilities of bots and assistants by incorporating generative AI techniques, resulting in more natural, human-like, and interactive conversations.
-
Generating original content — LLMs can produce original, contextually relevant creative content across domains such as images, music, and text, making them suitable for personalized recommendations and targeted product suggestions.
-
Increasing productivity — According to a study by the US National Bureau of Economic Research, LLMs can increase productivity by up to 34% for tasks like text drafting, performing repetitive and creative tasks, and generating new ideas during ideation sessions.
-
Transforming business operations — LLMs can help companies save money and improve their operations by automating customer service, conducting AI competitor analysis, and deploying autonomous agents within businesses.
-
Data engineering — LLMs and generative AI can play a pivotal role in shaping the data engineering landscape, helping with data cleaning, data quality management, and automation of policies, guidelines, and documentation.
-
Natural Language Understanding — LLMs have made significant strides in natural language understanding, enabling them to comprehend the context and intent behind human queries and responses, revolutionizing user experience and making interactions with AI systems feel less robotic.