What is AlpacaEval?
AlpacaEval, along with MT-Bench, is one of the best LLM evaluations for understanding the relative ranking of LLMs compared to their peers. While not perfect, it provides an automated comparison.
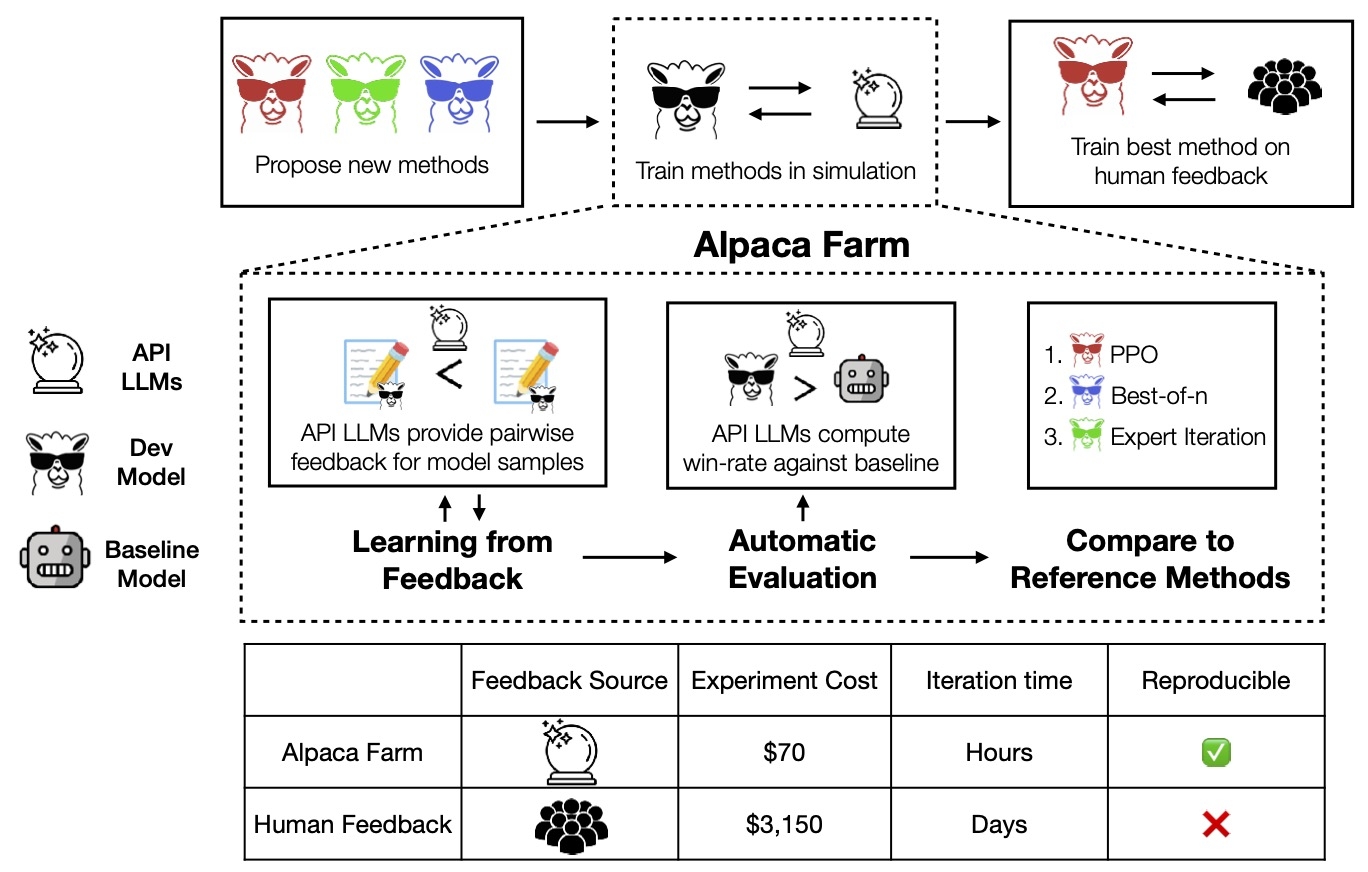
AlpacaEval is an automated tool for evaluating instruction-following language models against the AlpacaFarm dataset. It stands out for its human-validated, high-quality assessments that are both cost-effective and rapid.
The evaluator is specifically designed for chat-based large language models (LLMs) and features a leaderboard to benchmark model performance.
AlpacaEval calculates win-rates for models across a variety of tasks, including traditional NLP and instruction-tuning datasets, providing a comprehensive measure of model capabilities.
AlpacaEval is a single-turn benchmark, which means it evaluates models based on their responses to single-turn prompts. It has been used to assess models like OpenAI GPT-4, Mistral Mixtral, Anthropic Claude 2, and others.
Current Leaderboard
As of July 22, 2024, the current leaderboard is led by GPT-4 Omni, mirroring the human preference results of MT-Bench. LC Win Rate is length controlled.
| Model Name | LC Win Rate | Win Rate | License |
|---|
| GPT-4 Omni (05/13) | 57.5% | 51.3% | Proprietary |
| GPT-4 Turbo (04/09) | 55.0% | 46.1% | Proprietary |
| Yi-Large Preview | 51.9% | 57.5% | Proprietary |
| GPT-4 Preview (11/06) | 50.0% | 50.0% | Proprietary |
| Claude 3 Opus (02/29) | 40.5% | 29.1% | Proprietary |
| GPT-4 | 38.1% | 23.6% | Proprietary |
| Qwen1.5 72B Chat | 36.6% | 26.5% | Open Source |
| GPT-4 (03/14) | 35.3% | 22.1% | Proprietary |
| Claude 3 Sonnet (02/29) | 34.9% | 25.6% | Proprietary |
| Llama 3 70B Instruct | 34.4% | 33.2% | Open Source |
| Mistral Large (24/02) | 32.7% | 21.4% | Proprietary |
| Mixtral 8x22B v0.1 | 30.9% | 22.2% | Open Source |
| GPT-4 (06/13) | 30.2% | 15.8% | Proprietary |
| Contextual AI (KTO-Mistral-PairRM) | 29.7% | 33.2% | Open Source |
| Mistral Medium | 28.6% | 21.9% | Proprietary |
| Claude 2 | 28.2% | 17.2% | Proprietary |
| Claude | 27.3% | 17.0% | Proprietary |
| Yi 34B Chat | 27.2% | 29.7% | Open Source |
| DBRX Instruct | 25.4% | 18.4% | Open Source |
| Claude 2.1 | 25.3% | 15.7% | Proprietary |
| Gemini Pro | 24.4% | 18.2% | Proprietary |
| Qwen1.5 14B Chat | 23.9% | 18.6% | Open Source |
| Mixtral 8x7B v0.1 | 23.7% | 18.3% | Open Source |
| Llama 3 8B Instruct | 22.9% | 22.6% | Open Source |
| GPT-3.5 Turbo (06/13) | 22.7% | 14.1% | Proprietary |
| Tulu 2+DPO 70B | 21.2% | 16.0% | Open Source |
| GPT-3.5 Turbo (11/06) | 19.3% | 9.2% | Proprietary |
| GPT-3.5 Turbo (03/01) | 18.1% | 9.6% | Proprietary |
| Vicuna 33B v1.3 | 17.6% | 12.7% | Open Source |
| Mistral 7B v0.2 | 17.1% | 14.7% | Open Source |
| OpenHermes-2.5-Mistral (7B) | 16.2% | 10.3% | Open Source |
| Qwen1.5 7B Chat | 14.7% | 11.8% | Open Source |
| LLaMA2 Chat 70B | 14.7% | 13.9% | Open Source |
| Cohere Command | 10.9% | 12.9% | Proprietary |
| Vicuna 13B v1.3 | 10.8% | 7.1% | Open Source |
| Gemma Instruct (7B) | 10.4% | 6.9% | Open Source |
| LLaMA 33B OASST SFT | 9.9% | 4.8% | Open Source |
| WizardLM 13B | 9.8% | 5.9% | Open Source |
| Nous Hermes 13B | 9.7% | 5.4% | Open Source |
| Vicuna 13B | 9.2% | 5.8% | Open Source |
| Davinci001 | 9.0% | 2.8% | Proprietary |
How does AlpacaEval work?
AlpacaEval is an automatic evaluation system for instruction-following language models. The original eval system version benchmarked against OpenAI's Davinci003 and used GPT-4 as the auto-annotator.
A recent upgrade replaces both models with GPT-4 Turbo instead, signaling the new SOTA model since its original creation.
AlpacaEval is designed to be fast, cost-effective, and replicable, and it has been validated against 20,000 human annotations. The evaluation is based on the AlpacaFarm evaluation set, which tests the ability of models to follow general user instructions.
The responses generated by the models are then compared to reference responses, and the comparison is performed by GPT-4 based auto-annotators.
AlpacaEval automates the evaluation of instruction-following language models, such as ChatGPT, which traditionally relies on time-consuming and costly human interaction. Validated against 20,000 human annotations, AlpacaEval offers a fast, cost-effective, and replicable solution for model development.
Despite advancements, it's important to note limitations such as a bias towards longer outputs and models similar to the evaluator's base model (GPT-4 Turbo).
The system includes a leaderboard that ranks common models based on their performance on the AlpacaEval set. It features an automatic evaluator with high human agreement, capable of comparing model outputs to those of a reference model. The evaluator supports caching and output randomization to enhance reliability.
AlpacaEval also provides a toolkit for creating sophisticated automatic evaluators with features like caching, batching, and multi-annotator support. This toolkit allows for comprehensive analysis of evaluator performance, including quality, cost, speed, and statistical measures such as bias and variance.
Additionally, AlpacaEval offers access to a dataset of 20,000 human preferences, including 2,500 cross-annotations, to facilitate comparison between model and reference outputs. The AlpacaEval dataset simplifies the AlpacaFarm evaluation set by combining "instructions" and "inputs" into a single field and providing longer reference outputs.
AlpacaEval 2
AlpacaEval2 is an upgraded version of the original AlpacaEval. The improvements in AlpacaEval2 include being seven times faster and three times cheaper than its predecessor. The upgraded version of AlpacaEval, brings several significant improvements over the original version.
- Speed: AlpacaEval2 is seven times faster than its predecessor.
- Cost: The new version is three times cheaper, making it more accessible for a wider range of users.
- Baseline: AlpacaEval2 uses GPT-4 Turbo as its baseline, which is a more advanced language model compared to the ones used in the original version.
- Length Bias: The updated version has less length bias, which means it's more fair in evaluating responses of different lengths.
- New Models: AlpacaEval2 supports new models such as Mixtral and Gemini, expanding its utility and versatility.
These improvements make AlpacaEval2 a more efficient, cost-effective, and versatile tool for evaluating instruction-following language models.
Evaluation Dataset
Our evaluation of automatic annotators on the AlpacaEval set is based on a comparison with 2.5K human annotations. The evaluators range from those provided by Alpaca Farm and Aviary to LMSys, with human annotations serving as a reference. Metrics for all available evaluators and their configurations can be found in the AlpacaEval Github repository.
| Model | Human agreement | Price ($/1k) | Time (seconds/1k) | Bias |
|---|
| alpaca_eval_gpt4 | 69.2 | 13.6 | 1455 | 28.4 |
| alpaca_eval_cot_gpt4_turbo_fn | 68.6 | 6.3 | 1989 | 29.3 |
| alpaca_eval_gpt4_turbo_fn | 68.1 | 5.5 | 864 | 30.2 |
| gpt4 | 66.9 | 12.5 | 1037 | 31.5 |
| alpaca_farm_greedy_gpt4 | 66.4 | 15.3 | 878 | 30.2 |
| alpaca_eval_cot_gpt4_turbo_fn | 65.7 | 4.3 | 228 | 33.9 |
| humans | 65.7 | 300.0 | 36800 | 0.0 |
| claude | 65.3 | 3.3 | 173 | 32.4 |
| lmsys_gpt4 | 65.3 | 13.9 | 17982 | 31.6 |
| text_davinci_003 | 64.1 | 8.7 | 121 | 33.8 |
| longest | 62.2 | 0.0 | 0 | 37.8 |
| chatgpt | 57.3 | 0.8 | 285 | 39.4 |
Human agreement
Calculated by comparing an annotator's preferences to the majority of human annotations from our dataset of ~650 instructions, each with 4 human annotations. For automatic annotators, the same method is applied, ensuring comparability.
Price $/1000 examples
Reflects the average cost for 1000 annotations. For human annotations, it's based on the payment to Mechanical Turkers. If the cost is machine-dependent, it's left blank.
Time seconds/1000 examples
Represents the average time to annotate 1000 examples. For humans, it's the median time taken by Mechanical Turkers. For automatic annotators, it's the average time taken in our runs, subject to API limits and cluster load.
Spearman and Pearson correlations
These measure the correlation between leaderboards generated by auto-annotator preferences and human preferences, using method-level agreement from AlpacaFarm annotations. Due to a small sample size of 9 models, these correlations may not be highly reliable.
Bias
Assesses the agreement between the most likely human label and the automatic one, estimated by sampling 4 different annotations per example. A low bias indicates that the annotator's preferences align with humans on average.
Variance
Indicates the consistency of an annotator's preferences, estimated similarly to human agreement. Lower variance means more consistent results across different samples.
Proba. prefer longer
The likelihood that an annotator favors a longer output when there's a significant length difference between two outputs.
Automating Evaluations
The AlpacaEval system is particularly useful for evaluating large language models (LLMs) like GPT-4 and Vicuna-80. It provides a leaderboard that ranks models based on their performance, and this ranking is highly correlated with rankings based on human annotations. The leaderboard is open to contributions from the community, and new models can be added by running the model on the evaluation set, auto-annotating the outputs, and submitting a pull request with the model configuration and leaderboard results.
AlpacaEval is a single-turn benchmark, meaning it evaluates a model's ability to generate a response to a single instruction or prompt. It's part of a broader toolkit for building advanced automatic evaluators, which can include features like caching, batching, and multi-annotator analysis.
However, it's important to note that while AlpacaEval provides a useful comparison of model capabilities in following instructions, it's not a comprehensive measure of a model's overall performance or capabilities.
When to use AlpacaEval
AlpacaEval serves as a rapid and cost-effective proxy for human evaluation in simple instruction-following tasks, ideal for frequent assessments during model development.
However, it should not be used as a sole evaluation method in critical decision-making processes, such as determining model releases. AlpacaEval's limitations include a potential lack of representativeness in its instruction set for advanced LLM applications, a possible bias towards stylistic elements over factual accuracy, and an inability to assess the risks associated with model deployment.
Limitations of AlpacaEval
AlpacaEval's evaluation pipeline, like other evaluators, has significant limitations and is not a substitute for human evaluation in critical settings, such as determining model deployment readiness. The limitations include:
The instruction set may not reflect real-world usage: AlpacaEval's dataset, sourced from various collections (self-instruct, open-assistant, vicuna, koala, hh-rlhf), may not accurately represent the diverse applications and usage of advanced models like GPT-4.
Consequently, the performance of proprietary models (GPT-4, Claude, Mistral Medium, etc.) may appear closer to open models than they actually are. While AlpacaFarm's evaluation set shows a high correlation with user interaction win-rates, and the AlpacaEval leaderboard indicates a larger performance gap between open models and OpenAI models compared to other leaderboards, these findings are preliminary and should be interpreted with caution.
The AlpacaEval analysis indicates that automatic annotators have a tendency to favor longer outputs and those containing lists. This bias is also observed in human annotations, but it may reflect limitations in the annotation process rather than true human preferences. Moreover, automatic annotators often prioritize style over content, such as factuality, and show a preference for outputs from models trained on similar data, as evidenced by disparities in leaderboard rankings.
AlpacaEval focuses solely on instruction-following capabilities and does not assess potential harms, such as toxicity or bias. Therefore, the narrow performance gap between ChatGPT and top open-source models should not be misconstrued as an endorsement for deployment readiness.