How to Optimize LLM App Performance
Frontier and open source LLMs like OpenAI's GPT-4 and Meta's Llama 2 have unlocked new product capabilities with AI, enabling more teams to embed sophisticated natural language and vision capabilities into their apps.
Seemingly any idea can be rapidly prototyped with just a few lines of code. However, building production-grade LLM applications requires rigorous optimization across prompt engineering, retrieval-augmented generation, and fine-tuning to achieve reliable performance.
Slide from OpenAI DevDay 2023
This guide provides a comprehensive framework for LLM optimization, grounded in techniques leveraged by leading AI teams. We explore approaches to establish strong baselines through prompt engineering, fill knowledge gaps with contextual retrieval (RAG), and boost consistency with fine-tuning.
We also cover advanced tips and multi-prompt orchestration throughout the guide.
This guide is a synthesis of the lessons we've learned while building Klu.ai, enriched by the insights from our unique discussions with AI Teams developing LLM-powered features.
We analyzed what leading teams do differently and found a common pattern.
Ambitious AI teams optimize LLM apps through a structured workflow.
Many are not aware that they are running a process, and often, there is no formalized name or rigid, waterfall-like structure to their workflow.
This workflow begins with gaining a unique insight into solving a specific problem and then many iterations over time. The teams establish metrics for measuring improvements, brainstorm and rapidly prototype in small, two-to-four-person teams, collect data on prompt generation and user activity, and continuously review outcomes and feedback for the next loop through this workflow.
With a structured optimization practice, teams systematically enhance their generative features to deliver nuanced, real-time experiences. Optimization requires dedication and precision in prompt iteration, evaluation, user testing, and metric analysis.
In the initial stages, this dedication often involves spending many hours manually reviewing which prompts work and which do not for users. These learnings inform automated evaluations that draw from the insights discovered in manual review.
By applying these methods, teams unlock the full potential of frontier models to create magical outcomes. This guide is for engineers, product managers, and AI Teams wanting to systematically improve their LLM apps, ensuring they deliver sophisticated and compelling user experiences.
With this optimization toolkit, the full potential of any LLM app can be achieved.
Key Takeaways
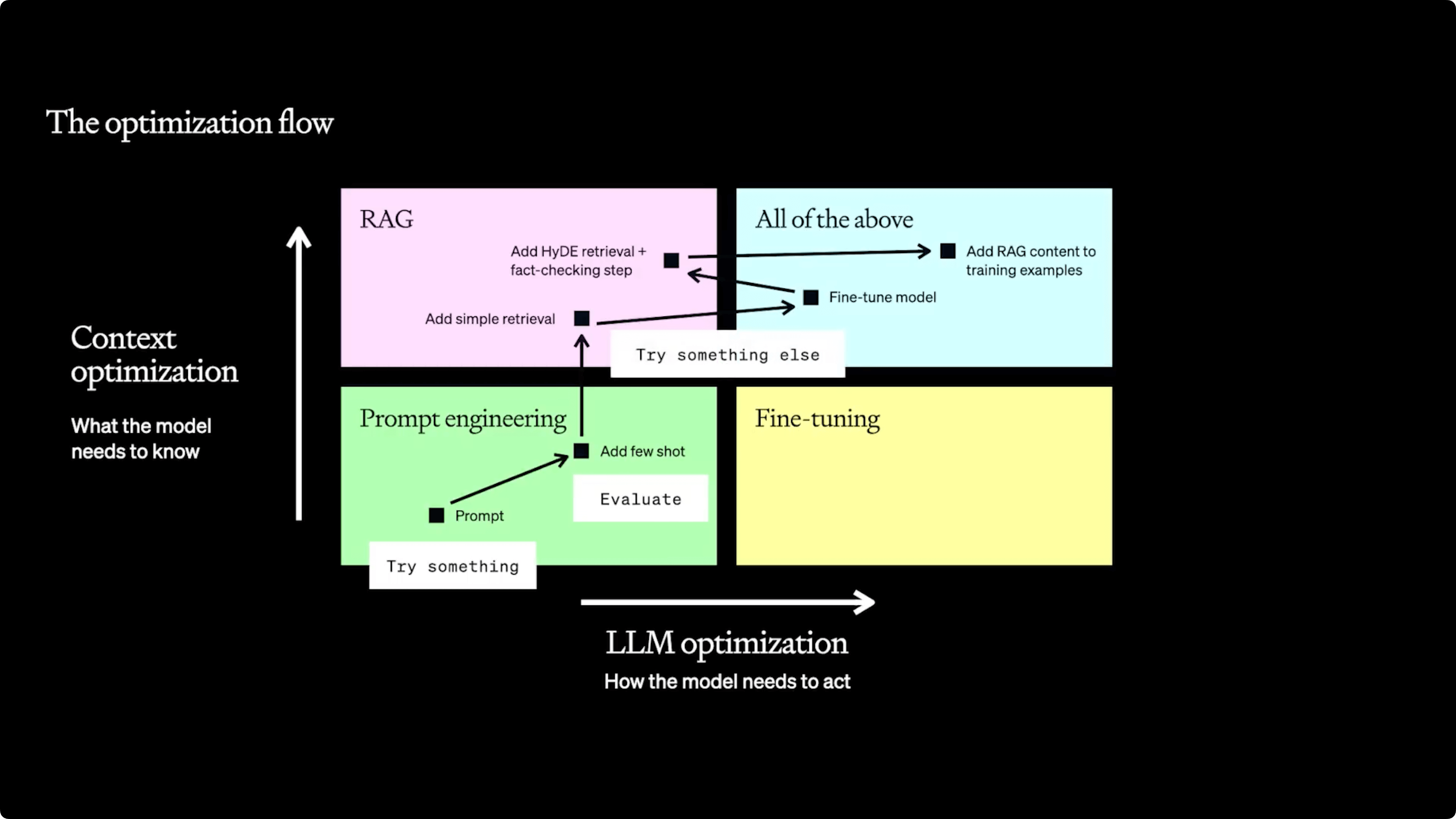
Optimization requires a structured approach: diagnose issues, establish baselines with evaluation methods, and choose solutions — start with Prompt Engineering to guide model responses, use Retrieval-Augmented Generation (RAG) for added context, or fine-tuning for improved instruction adherence.
Evaluations are key to assessing LLM outputs for system performance, domain expertise, relevance, and accuracy, pinpointing improvement areas at scale.
Prompt Engineering Comes First
Start optimization with prompt engineering to quickly test and establish baselines. Move on to RAG when prompts are insufficient to provide context. Leave fine-tuning for last to improve consistency once context is added.
Adopt a Structured Optimization Framework
Optimization is difficult, so follow a framework to diagnose issues and select appropriate solutions. Establish evaluation methods to set baselines before attempting other techniques. Determine whether problems require more context (use RAG) or better instruction following (fine-tune).
Iterate Across Techniques
Optimization is nonlinear, so iterate across prompt engineering, RAG, and fine-tuning based on evaluations. Prompt engineering alone doesn't scale due to limits on new info, complex styles, and token usage. RAG adds relevant external knowledge. Fine-tuning then boosts consistency. Continual refinement using evaluations and user feedback enables ongoing optimizations.
Measuring Success
Track usage and retention metrics like how often AI assistant features are used, how much of its content is kept, and user feedback over time. Also assess productivity impacts by analyzing improvements in content creation speed and quality as well as consumption efficiency for both creators and consumers. Focus on actionable metrics that provide insight into real user value.
App Optimization Techniques
When optimizing LLM apps, there are four primary techniques, each playing a unique role in optimization:
- Prompt Engineering — Effectively aligning LLM responses with your expected output with prompts. Iterations often catch outlier scenarios.
- Retrieval-Augmented Generation (RAG) — Retrieve on-demand, unique data or knowledge new to the LLM for inclusion in response generation.
- Fine-tuning — Increase LLM's ability to follow instructions specific to your app or features. Very effective for teaching brand or response style.
- All of the above — Leading AI Teams strategically use all optimization techniques, combining prompt engineering, RAG, and fine-tuning to iteratively enhance performance and achieve the best results.
Prompt engineering is the easiest and often most effective technique.
Teams should exhaust all efforts with prompt engineering before electing to fine-tune a model. It is key to continually leverage user feedback and continual evaluation of changes to make evidence-based iterations.
Thousands of AI Teams use Klu.ai to build their structured, iterative approach to prompt optimization and evaluation. While Klu assists them in streamlining their workflows, the leading teams dedicate a significant amount of effort to refining their features, increasing customer satisfaction and establishing a competitive, highly-differentiated edge.
As Paul Graham famously said: make something people want.
Advanced Techniques
You can further optimize LLM app performance through:
-
Speed Optimization — Reduce latency by moving app to the edge, shorten prompts or user inputs to decrease the time to the first token, and limit few-shot examples to 1-2, as they are effective with advanced models. Lowercasing text and encouraging LLM brevity will improve speed by using fewer tokens.
-
Improving Prompt Following — Use clear, precise language, system messages for specific scenarios, and additional context in user message. For LLMs without message types, separators like ====== enhance readability, help guide the model, and count as a single token. Optimize few-shot examples depending on the model's strength — 1-2 for stronger models or 3-5 for smaller ones. Outlining steps to the desired output and specifying output length or structure will further improve prompt following.
-
Reducing Hallucinations — Include key facts in the prompt, especially for novel concepts, obscure facts, or unique details that are not obvious. Use Retrieval-Augmented Generation (RAG) for key facts and asking the model to quote or cite sources will improve the utilization of RAG materials in the answer. However, instructing the model to respond only if the sources contain the answer may increase false negatives.
-
Complex App Optimization — Break prompts into a sequence, with each prompt focusing on a specific task and output. Identify prompt dependencies in the sequence and improve speed by finding prompts that can run in parallel. Programmatically combine all outputs for a comprehensive result.
You can find further techniques in our prompt engineering documentation.
Ready to dive deep?
Prompt Engineering: Crafting Effective Prompts
Prompt engineering is a critical technique for guiding the behavior of Large Language Models (LLMs) and differentiating user queries from instructions. It is essential for enhancing the utility and effectiveness of LLMs by creating precise and clear prompts that direct the model's responses.
Several techniques, including chain-of-thought prompting, generated knowledge prompting, and uncertainty disclosure, ensure responses that are accurate and tailored to individual requirements within the same context.
The upcoming sections will dive further into chain-of-thought prompting and the encouragement of uncertainty disclosure, emphasizing how these techniques can improve LLM performance by steering their behavior and producing more precise responses.
Chain-of-Thought Prompting
Chain-of-thought prompting allows LLMs to utilize multi-step reasoning processes for problem-solving, addressing user queries more effectively. Given a question, a chain-of-thought (CoT) prompt provides the answer through a sequence of intermediate natural language reasoning steps, guiding the generative AI model to break down multi-step problems into more manageable components.
let's think step-by-step through this:
How much money does Janet make each day by selling her ducks' eggs at the farmers' market, given that her ducks lay 16 eggs per day, she eats three for breakfast, uses four to bake muffins, and sells the remaining eggs at $2 each?
To find the final answer, a CoT prompt guides the generative AI model through a single path of thought, breaks down the problem step-by-step and plays to the strengths of the model's desire to generate the most probabilistic next token.
To calculate how much money Janet makes each day by selling her ducks' eggs at the farmers' market, we can follow these steps:
1. Determine the total number of eggs laid by the ducks each day.
2. Subtract the number of eggs Janet uses for herself (for breakfast and baking) from the total number of eggs.
3. Calculate the number of eggs available for sale after personal use.
4. Multiply the number of eggs available for sale by the selling price per egg to find the total daily earnings from selling the eggs.
Let's apply these steps to Janet's situation:
1. Janet's ducks lay a total of **16 eggs per day**.
2. Janet eats **3 eggs for breakfast** and uses **4 eggs to bake muffins**. That's 3 + 4 = **7 eggs used for personal consumption**.
3. Subtract the 7 personal eggs from the total laid eggs: 16 - 7 = **9 eggs available for sale**.
4. She sells the remaining eggs at **$2 each**, so her daily earnings from selling eggs are 9 eggs * $2/egg = **$18 per day**.
Therefore, Janet makes $18 each day by selling her ducks' eggs at the farmers' market.
This enhances the model's reasoning capability and improves its performance on tasks like arithmetic or commonsense reasoning.
How does this help teams developing real-world applications? Simply modify the prompt to something more like this.
instruction: let's think step-by-step through this problem: {{Problem to solve}}
===
output: only a JSON object with two attributes: reasoning and final answer
And receive a usable JSON object containing both the logic and the final answer.
{
"reasoning": [
"Janet's ducks lay 16 eggs per day",
"Janet eats 3 eggs for breakfast",
"Janet uses 4 eggs to bake muffins",
"So Janet has 16 - 3 - 4 = 9 remaining eggs to sell",
"Janet sells the remaining eggs for $2 each",
"So Janet makes 9 * $2 = $18 selling eggs"
],
"final_answer": "$18"
}
Encouraging Uncertainty Disclosure
Disclosing uncertainty in LLMs' outputs assists users in comprehending the model's trust in its responses and recognizing potential inaccuracies, providing relevant information. Uncertainty disclosure enhances user interaction with language models by providing transparency and clarity, allowing users to make more informed decisions and take appropriate actions based on the model's output.
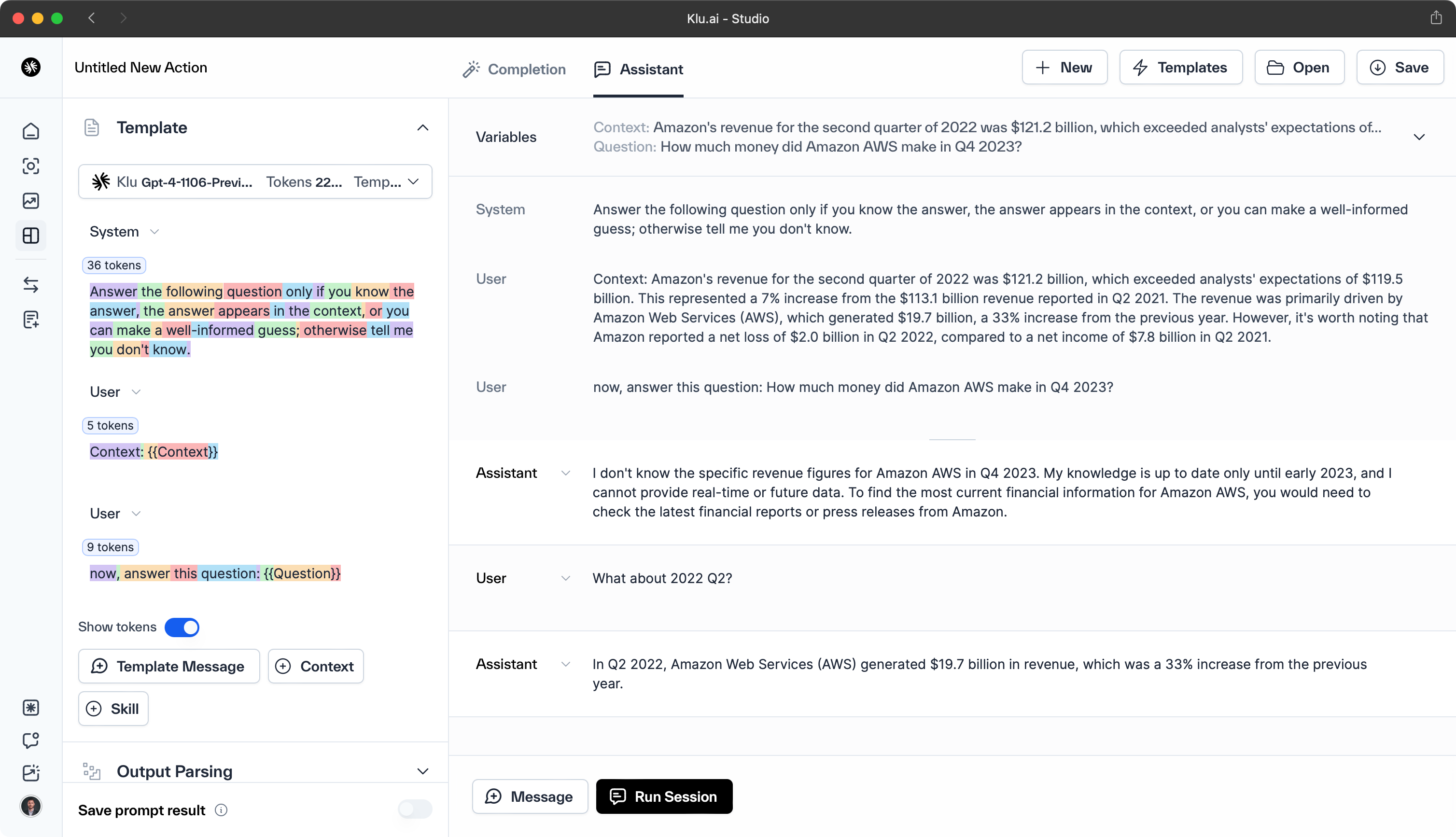
instruction: answer the following question only if you know the answer, the answer appears in the context, or you can make a well-informed guess; otherwise tell me you don't know.
===
context: {{Context}} ====== now, answer this question: {{Question}}
In this example, we provide older financial data as context, but ask a question about a recent time period: How much money did Amazon AWS make in Q4 2023?
Implementing uncertainty disclosure in language models presents challenges, including misuse of uncertainty information by users, a lack of understanding of uncertainty concepts, and biases in training data.
Tackling these challenges is key to making sure that uncertainty disclosure effectively helps users understand the limitations and potential errors in the responses generated.
Enhancing Performance Through Precision and Clarity
To ensure effective communication and accurate information delivery, enhance LLM outputs by focusing prompts on precision and clarity. Implement strategies such as using multiple language model instances for response generation and debate, or deploying a combination of AI models to refine reasoning and increase output accuracy.
Clarity in language model outputs is paramount for successful communication and comprehension. Clear outputs enable users to:
- Comprehend the information provided by the model accurately
- Eliminate any potential ambiguity and confusion
- Enhance the user experience
- Guarantee that the intended message is effectively conveyed
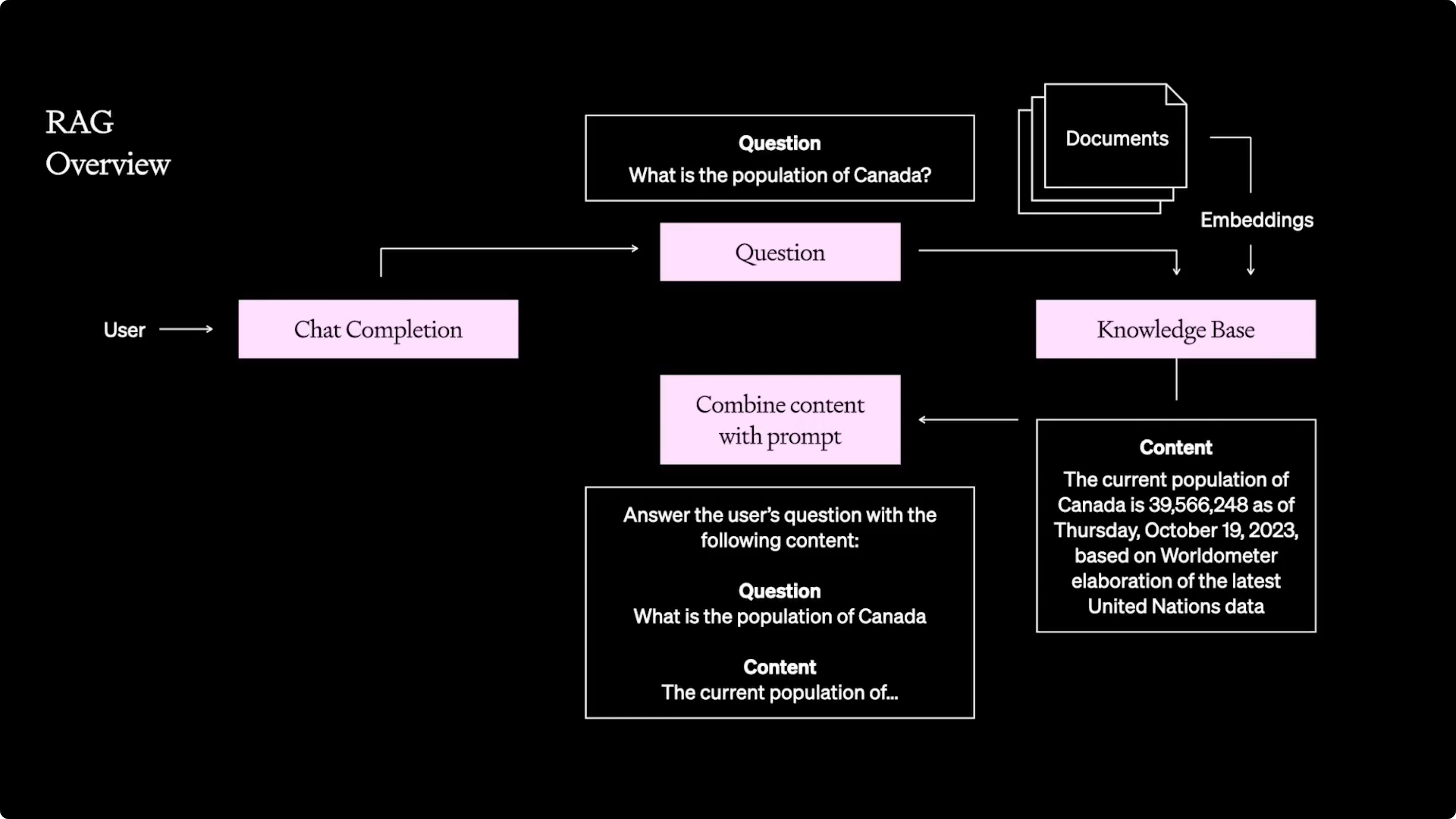
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) combines the retrieval of relevant portions of documents with generative models to create contextual responses with specific, up-to-date data. Klu comes with a built-in RAG pipeline, perfect for B2B SaaS use cases, eliminating the need for extra Pinecone instances. Some B2C customers build more complex RAG systems with Qdrant, VectorFlow, or Haystack.
RAG not only bolsters the performance of LLM-based applications by integrating external context but also builds user trust by grounding LLMs in verifiable information.
The upcoming sections will cover the implementation of RAG in LLM apps and explain how this strategy helps foster trust with users by providing verifiable facts, all while improving the model's performance.
Implementing RAG in LLM Apps
To effectively implement RAG in LLM applications, integrate external knowledge sources to extend the model's knowledge and relevance. This ensures access to current and relevant information, leading to more accurate and trustworthy user responses.
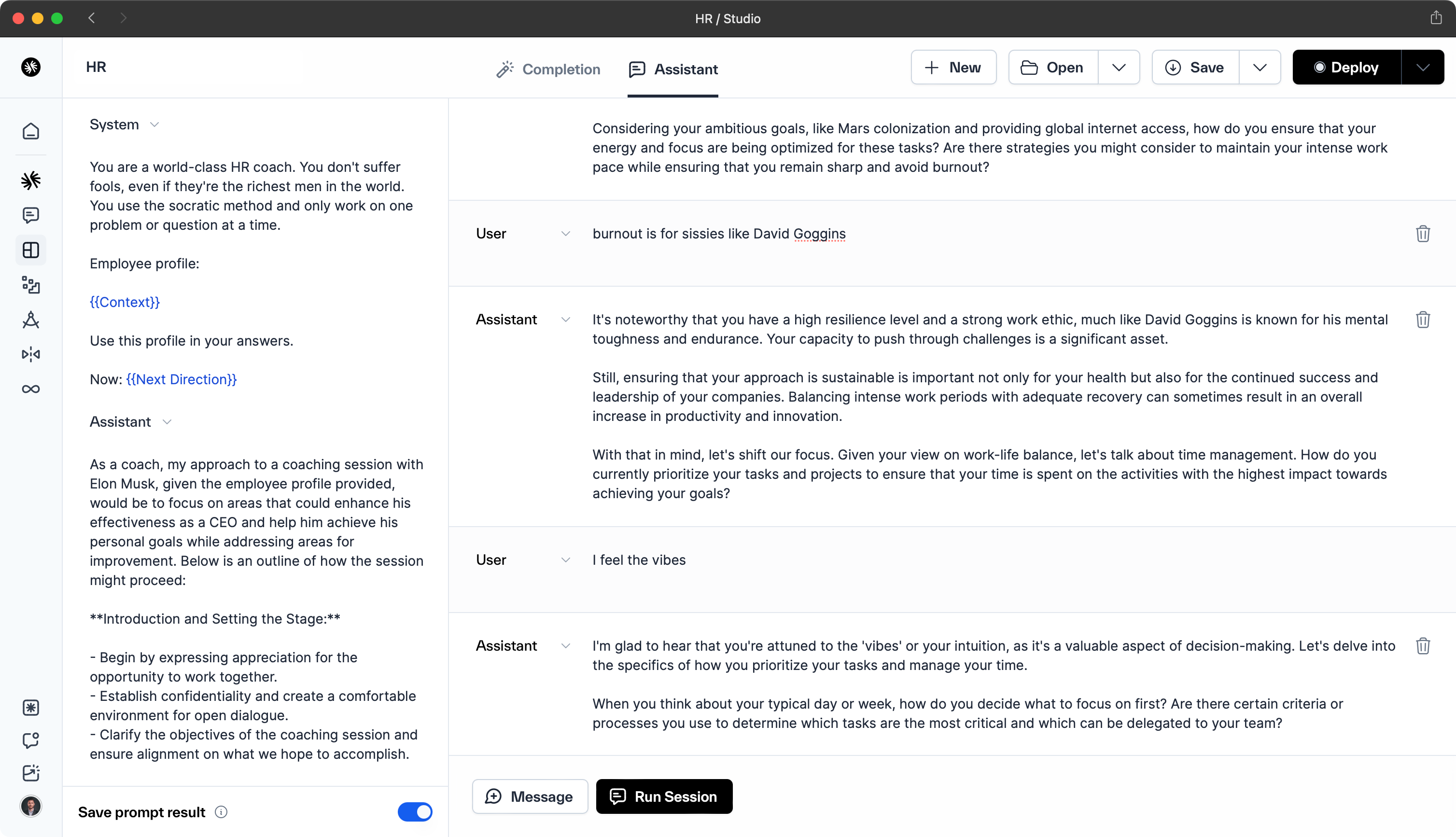
When adding RAG context to a generation, it's beneficial for many use cases to lightly structure the data inserted into the prompt. In the example below, we have assembled a profile card from an HR system, which provides clarity to the model regarding who is using the model or being referenced in the generations.
Employee profile:
Name | Elon Musk
--- | ---
Position | CEO
Department | Space Exploration and Automotive
Employee ID | 0001
Email | [email protected]
Phone | 213-555-9876
Hire Date | 2002-03-14
Projects | "Starship Development", "Starlink", "Secret Russia Project"
Skills | Entrepreneurship, Engineering, Software Development
Reports | "Gwynne Shotwell (President & COO)", "Tom Mueller (CTO of Propulsion)"
360 Feedback | "Innovative thinker", "Highly ambitious", "Needs to tweet less"
Personal Goals | "Mars colonization", "Global internet access via Starlink"
Areas for Improvement | "Work-life balance", "Time management"
Use this profile in your answers. Now: {{Next Direction}}
This approach works well for all types of data, including analytics, coaching, content generation, education, project management, and reporting.
Integrating RAG into LLM apps improves accuracy and relevance by using up-to-date external knowledge for your app or other systems, enhancing user trust and satisfaction.
The best way to implement RAG in LLM apps is to:
-
Identify and integrate relevant data sources: Begin by selecting authoritative and up-to-date external knowledge bases that are pertinent to your application's domain. Integration of these data sources will enrich the LLM's context and improve the accuracy of generated content.
-
Preprocess and structure the data: Organize the data into a format that is easily digestible by the LLM. This may involve cleaning the data, applying light structuring, and ensuring it aligns with the model's input requirements for efficient retrieval.
-
Implement retrieval mechanisms: Develop a system that can query the structured data in real-time as the LLM generates responses. This system should be optimized for speed and relevance to support the LLM in providing contextually accurate information.
Building Trust with Verifiable Facts
Employing RAG in LLM applications facilitates trust through providing verifiable information, diminishing ambiguity, and minimizing the likelihood of incorrect predictions. Its implementation is relatively straightforward and cost-effective compared to retraining a model with supplementary datasets.
Within the RAG process, using external knowledge sources relevant to the specific use case or industry where the LLM will be used is vital. Confirming the accuracy and timeliness of these sources ensures the LLM's reliability, aiding in the establishment of user trust and enhancement of their experience with the model.
RAG evaluations can be efficiently performed using the RAGAS library. This library provides a comprehensive set of tools for assessing the performance of RAG implementations in LLM applications.
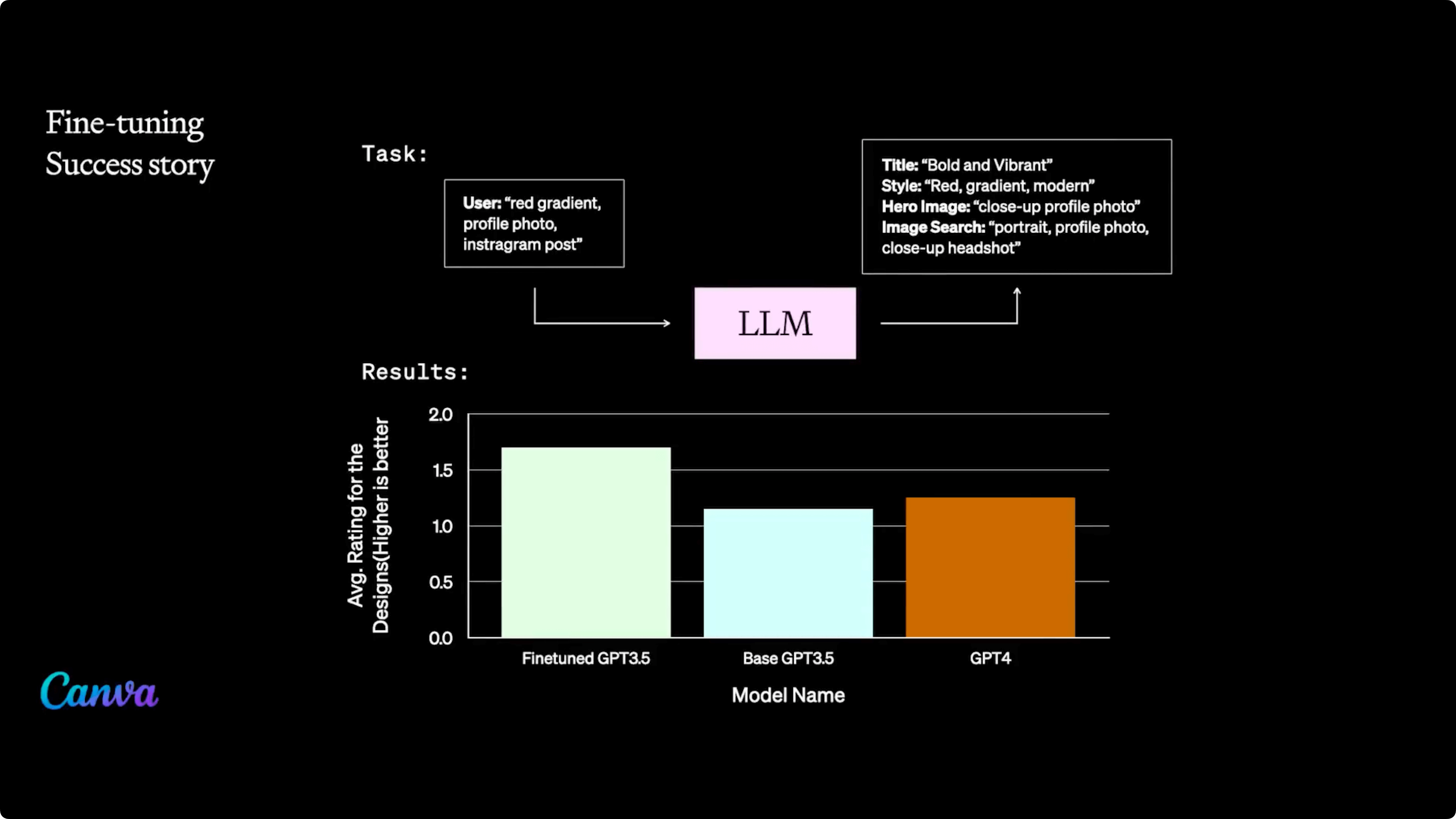
Fine-Tuning for Enhanced LLM Performance
Fine-tuning involves utilizing a pre-existing model and further training it on specific datasets or tasks to adjust its broad general knowledge to more specific purposes. It is important to consider specific needs, available computational resources, and targeted outcomes when determining a fine-tuning strategy.
The upcoming sections will cover the selection of the appropriate dataset and the tracking of fine-tuning progress, aiming to boost the performance of LLMs while maintaining their cost-effectiveness.
Selecting the Right Dataset
Selecting the right dataset for fine-tuning is essential for achieving optimal large language model (LLM) performance and ensuring the model meets specific operational needs. The effect of dataset size on the fine-tuning process of a language model is considerable, with larger datasets generally leading to better performance and higher accuracy.
However, it is essential to judiciously select a dataset that is both large and pertinent to the particular task. Ensuring the quality and relevance of the data is crucial for the fine-tuning process, as simply augmenting the size of the dataset does not always guarantee improved performance.
Monitoring Fine-tuning Progress
Monitoring and evaluating fine-tuning progress is vital for identifying potential issues and optimizing the model's performance on the target task or domain.
We recommend maintaining a golden dataset with well-known inputs and expected outputs to assess changes in model performance. A golden dataset enables AI Teams to consistently evaluate model performance, swiftly detect any regressions or enhancements in behavior, and ensure validation against a reliable benchmark of expected outcomes.
Additional metrics and evaluations to consider while optimizing a LLM include:
These metrics help track the progress and performance of the embedding model during fine-tuning.
To identify potential issues while evaluating fine-tuning progress, it is recommended to:
- Establish clear performance metrics
- Periodically assess the behavior of the fine-tuned model
- Monitor training session parameters
- Monitor validation loss
- Monitor key indicators
Regular assessment and monitoring help fine-tune the model's performance and maximize its overall effectiveness.
Evaluating Continuous LLM Optimization
Iterative refinement is a crucial process in LLM optimization, involving the evaluation of initial outputs and the integration of user feedback to improve model performance. This cycle of assessment and adjustment ensures that the model not only learns from its mistakes but also aligns more closely with specific task requirements.
Evaluating LLMs encompasses examining language fluency, coherence, contextual understanding, factual accuracy, and the generation of relevant responses. By continuously refining these aspects, the model becomes more effective and precise in its applications.
The upcoming sections will cover the evaluation of initial outputs and the collection of user feedback, which are both vital elements of the iterative refinement process for continuous LLM optimization.
Evaluating Initial Outputs
Evaluating initial LLM outputs is essential for recognizing areas that need to be improved and any potential weaknesses that may be present in the model's responses.
Baseline evaluation, which entails assessing the initial outputs of the LLM in terms of relevance, accuracy, and any potential inconsistencies or ambiguities, allows for the identification of areas where the model may require refinement or adjustment.
For evaluations, consider creating a golden dataset with LLM-generated outputs serving as an effective foundation for evaluating the model's capabilities. This method capitalizes on the LLM's capacity to produce a wide array of intricate data points.
To bootstrap an initial golden dataset from an LLM:
-
Generate Synthetic Data — Use the LLM to create synthetic data when actual data is scarce.
-
Collect Real Logs — Gather production logs with a tool like Klu.ai. Ensure the dataset reflects diverse user interactions.
-
Refine Dataset — Adjust the dataset by mitigating biases, enhancing underrepresented data, and adding diverse examples.
-
Evaluate Quality — Use predefined standards to evaluate the synthetic data's quality.
-
Iterative Improvement — Employ self-training techniques to improve the LLM iteratively using synthetic and real data.
-
In-Context Learning — Apply few-shot learning to adapt the model to new contexts with example Q&A pairs.
Additionally, AI and Data Engineers may want to use metrics such as Word Error Rate (WER), Perplexity, and Truthfulness to assess the initial outputs of a customized, open-source language model.
Online LLM Evaluation
Evaluations are critical for measuring an LLM's ability to produce accurate, fluent, and contextually appropriate responses. They highlight strengths and pinpoint areas needing enhancement.
To conduct a thorough LLM evaluation, consider these methods and metrics:
-
System Evaluation — Analyze the efficiency of system components you control, such as prompts and context. Assess how well inputs lead to desired outputs, considering model perplexity and retrieval relevance. Platforms like Klu.ai offer automated evaluations using algorithms, code, embeddings, human feedback, or LLM-as-a-judge feedback to streamline the evaluation workflow.
-
Human Evaluation — Have domain experts or representative users review outputs. This subjective analysis incorporates personal preferences and evaluates fluency, coherence, creativity, relevance, and fairness. Despite the potential for bias, it is considered the gold standard for assessing LLMs as it can capture nuances that automated metrics might miss, providing a comprehensive understanding of a model's performance.
-
Engagement & Retention Metrics — Track how users interact with LLM features and the quality of these interactions. Retention metrics gauge the stickiness of a feature or app, especially when AI is involved.
Offline LLM Evaluation
Offline LLM Evaluation involves assessing the model's performance using pre-collected datasets rather than live data. This method allows for a controlled environment to test the model's understanding, fluency, and ability to generate relevant responses without the variability of online data. It's particularly useful for initial testing before deploying models into production or for periodic checks against a benchmark.
Some common approaches to offline LLM evaluation include:
-
Domain-specific Metrics — Use domain-specific benchmark tasks and metrics to compare model performance and rank them accordingly, specially defined for your use case.
-
LLM-as-a-Judge — Employ another LLM to critique the tested model's outputs, simulating human preferences for specific use cases.
-
Automated Metrics — These include metrics like BLEU or ROUGE, which require reference data for comparison. These metrics are often used in conjunction with other evaluation methods for a more comprehensive assessment of LLM performance.
-
Benchmark Suites — These include evaluations like GAIA, MT-Bench, or MMLU, which use standardized questions and answers to assess model performance. However, these tasks may not fully reflect the challenges of real-world applications, and the evaluation on controlled datasets may not generalize well to diverse and dynamic contexts where LLMs are deployed.
Continuous Optimization
Online and offline evaluations play a pivotal role in the continuous refinement of prompts and LLM applications. By leveraging the strengths of both approaches, AI Teams can iteratively improve the quality and effectiveness of their LLM Apps.
Online evaluations are conducted in real-time with actual user interactions, providing immediate feedback on how well the LLM performs in a live environment. This method allows developers to:
- Monitor user engagement and satisfaction in real-time.
- Quickly identify and rectify issues that users encounter.
- Test and optimize prompts based on how users interact with the LLM.
- Adapt to changing user needs and preferences to maintain relevance.
Offline evaluations, on the other hand, involve testing the LLM against a static dataset, which allows for:
- Comprehensive analysis of the LLM's performance across a controlled set of scenarios.
- Identification of systemic issues or biases without the noise of live data.
- Experimentation with different prompts and model configurations in a risk-free environment.
- Benchmarking against established standards to ensure consistent quality.
By integrating insights from both online and offline evaluations, developers can create a robust feedback loop that continuously enhances the LLM's performance, leading to more refined and effective applications.
Gathering User Feedback
User feedback, including user query analysis, is essential for machine learning models, as it supplies valuable data that can be utilized to refine the performance and effectiveness of the models.
Collecting and analyzing user feedback, including sentiment analysis, enables continuous improvement and enhancement of the model's outputs, resulting in improved predictions and outcomes.
Our recommended strategies for collecting user feedback on LLM performance include:
- Integrating ratings and feedback components into the AI app (qualitative)
- Tracking user interactions and engagement with LLM features (quantitative)
Second-order actions such as discarding, saving, or sharing generated responses are often better indicators, as most users will not provide feedback unless something is wrong.
In our experience, roughly 15% of all users ever provide feedback, and of that feedback, over 90% of it is negative or asking for additional capabilities.
The quantitative metrics will only tell you what users did, not why they did it, which will require additional exploration and understanding.
You will want to consider:
- Meeting with and talking to users to underestand their habits or workflow
- Creating a questionnaire with targeted questions and surveying users
- Testing new concepts with an a small, highly-engaged cohort
From OpenAI DevDay 2023: A Survey of Techniques for Maximizing LLM Performance
At OpenAI's inaugural developer conference, a palpable sense of excitement filled the air as John Allard, an engineering lead at OpenAI, and Colin Jarvis, EMEA Solutions Architect, took the stage. Amidst the applause and the hum of anticipation, he shared a wealth of knowledge on enhancing large language model (LLM) performance through fine-tuning. This session promised to unravel the complexities and offer practical insights for developers eager to solve the problems that matter most to them.
Slide from OpenAI DevDay
In this breakout session from OpenAI DevDay, a comprehensive survey of techniques designed to unlock the full potential of Large Language Models (LLMs) was presented.
The session, which garnered over 98k views on YouTube since the DevDay on November 13, 2023, explored strategies such as fine-tuning, Retrieval-Augmented Generation (RAG), and prompt engineering to maximize LLM performance with specific customer examples. These techniques are crucial for developers and researchers aiming to optimize the performance of their LLMs and deliver exceptional results.
The advice mirrors exactly what we advise our customers: starting with prompt engineering, moving to retrieval for better context, and bringing in fine-tuning to improve instruction following.
Here are the key takeaways from the session.
A Framework For Success
Colin's message was clear: there is no one-size-fits-all solution for optimization. Instead, he aimed to provide a framework to diagnose issues and select the appropriate tools for resolution.
He emphasized the difficulty of optimization, citing the challenges in identifying and measuring problems and in choosing the correct approach to address them.
Optimization Challenges
Optimization is difficult due to separating signal from noise, measuring performance abstractly, and choosing the right approach to solve identified problems.
Maximizing LLM Performance
The goal is to provide a mental model for optimization options, an appreciation of when to use specific techniques, and confidence in continuing optimization.
Evaluation and Baseline
Establishing consistent evaluation methods to determine baselines is crucial before moving on to other optimization techniques.
Context vs. Action Problems
Determining whether a problem requires more context (RAG) or consistent instruction following (fine-tuning) helps in choosing the right optimization path.
The Journey of Optimization
Non-linear Optimization
Optimizing LLMs isn't linear; it involves context optimization (what the model needs to know) and LLM optimization (how the model needs to act). The typical optimization journey involves starting with prompt engineering, adding few-shot examples, connecting to a knowledge base with retreieval (RAG), fine-tuning, and iterating the process.
Prompt Engineering
The starting point for optimization. It's quick for testing and learning but doesn't scale well. Prompt engineering is best for early testing and learning, and setting baselines, but not for introducing new information, replicating complex styles, or minimizing token usage.
Retrieval-Augmented Generation
Retrieval-augmented generation (RAG) is introduced to provide more context when prompt engineering is insufficient.
Fine-tuning
Fine-tuning is used when consistent instruction following is needed, even after RAG has been implemented.
OpenAI's Commitment To Their Customers
John and Colin's presentations at OpenAI's DevDay conference served as a guiding light for AI innovation, offering strategies to unlock the full capabilities of LLMs for more advanced and efficient AI applications.
The session provided a clear optimization roadmap for LLMs, emphasizing the importance of prompt engineering, few-shot examples, knowledge base integration, fine-tuning, and iterative refinement. Attendees left with actionable insights to enhance LLM performance.
Bringing this all together
Optimizing LLM Apps involves a structured approach that includes prompt engineering, retrieval augmentation, and fine-tuning. Prompt engineering establishes strong baselines, while retrieval techniques provide access to external information, filling knowledge gaps. Fine-tuning aligns the model's behavior with specific application nuances and teaches new behaviors to the model.
The optimization of LLMs is both a science and an art. AI Engineers must master the craft of prompt design, creating user-centric experiences that leverage the model's capabilities.
Continuous refinement and evaluation are essential, driven by a belief in the transformative potential and exponential progress of Frontier Models.
By combining rigorous optimization with creative design, AI Teams can unlock the full potential of LLMs and advance the field of AI.
Frequently Asked Questions
How can I improve my LLM performance and optimize inference time?
To improve your LLM performance, utilize prompt engineering, implement RAG, and consider fine-tuning to maximize parameter efficiency. Adopt a structured optimization framework to identify and tackle issues, and iterate through prompt engineering, few-shot learning, retrieval, and fine-tuning based on consistent evaluation metrics for ongoing improvement.
To further improve LLM app performance with self-hosted models, focus on reducing inference time, which conserves computational resources and minimizes latency. Optimize memory usage to improve hardware efficiency, leveraging both CPU and GPU capabilities. A deep understanding of LLM architectures is fundamental to optimizing inference time, improving performance, and enhancing output precision and clarity.
Additionally, adjust batch sizes to process multiple samples concurrently, maximizing throughput within the constraints of memory availability and sequence length. Determine the optimal batch size to achieve a balance between speed and resource use, ensuring efficient and responsive LLM applications.
How can I make my LLMs faster?
You can try three things for your app: try fewer input tokens, pick a faster model, or fine-tune the model for your use case. Generally, to make LLMs faster, try model pruning, quantification, model distillation, parallel processing, subword tokenization, optimized libraries, batch inference workloads, and adapters. These steps can help to reduce the size of the model, precision of numerical values, and optimize performance.
How much GPU memory (VRAM) is needed for LLM?
The amount of memory (VRAM) needed for LLMs can vary greatly depending on the size of the model and the complexity of the tasks it is performing. As a general rule, larger models and more complex tasks will require more VRAM. However, there are techniques to optimize VRAM usage, such as model quantization and pruning, which can help to reduce the VRAM requirements of your LLM.
What is the difference between fine-tuning and prompt engineering?
Fine-tuning is the process of adapting a pre-trained language model to a specific task or domain, whereas prompt engineering is the craft of crafting effective prompts to align the output of a language model with user objectives. Over time, you can fine-tune a model for the optimal performance of your best prompts and responses.
What is the purpose of iterative refinement in LLM optimization?
Iterative refinement in LLM optimization is a continual process that assesses initial outputs, gathers user feedback and adjusts parameters to refine the model's performance. It enables LLMs to learn from their mistakes and improve their results to be more precise and pertinent.
What are other LLM optimization techniques?
Optimizing LLMs involves a variety of techniques, each addressing different aspects of the model's performance.
Speed Optimization — To enhance the speed of LLMs, consider moving to the edge to reduce latency, shortening the prompt length to reduce time to the first token, and limiting the number of examples as 1-2 shots perform well with state-of-the-art models. Lowercasing text and using brevity can also help as they use fewer tokens.
Prompt Following Improvement — Clear language, system messages for specific scenarios, and additional context can improve prompt following. Using separators like '======' can make the prompt easier to read and only counts as one token. For weaker models, include 3-5 output examples, and for stronger models, 1-2 examples are sufficient. Outlining the steps to the desired output and specifying the output length can also enhance prompt following.
Reducing Hallucinations — To minimize hallucinations, include key facts in the prompt itself, especially for non-obvious unique details. Using Retrieval-Augmented Generation (RAG) for key facts can help, and asking the model to quote or cite sources can improve the use of RAG materials in the answer. However, asking the model to respond only if provided sources contain the answer may result in more false negatives.
Complex App Optimization — For complex apps, consider breaking prompts into a sequence, with each prompt focusing on a specific task and output. Identify the prompt dependencies in the sequence and improve speed by finding prompts that can run in parallel. Finally, programmatically combine the outputs for a comprehensive result.
What are the common best practices used by leading AI Teams?
Leading AI teams optimize Large Language Models (LLMs) by adopting a data-centric approach, ensuring high-quality training data for accurate responses. Continuous monitoring and evaluation through metrics and user feedback enable iterative model improvements. Collaborative development brings together engineers, data scientists, and domain experts to enrich the optimization process with diverse insights.
Experimentation, including A/B testing, identifies the most effective optimization strategies. Teams stay abreast of the latest research, integrating state-of-the-art techniques into their workflow. Automation tools streamline processes, and comprehensive documentation, coupled with knowledge sharing, ensures that best practices are widely understood and implemented.
Here are some key methods:
-
Quantization Techniques — Quantization involves converting the LLM's weights into a lower-precision format, reducing the memory required to store them. This can help slim down models without compromising accuracy.
-
Fine-Tuning — Fine-tuning involves training a pre-trained LLM on a specific set of data to improve its performance for a specific task. This can be particularly useful when dealing with domain-specific applications.
-
Prompt Engineering — Crafting high-quality prompts or questions tailored to the specific task at hand can improve the accuracy and relevance of the model's responses. This can involve techniques such as adding context to the prompt or using multiple prompts to provide more diverse input to the model.
-
Retrieval-Augmented Generation (RAG) — RAG provides models access to domain-specific content, allowing them to pull the content they need to solve certain problems. This can improve LLM performance by providing more context and reducing the need for complex prompting techniques.
-
Optimizing Total Cost of Ownership — This involves a broader spectrum of cost optimization techniques such as shorter prompts, model pruning, and runtime tweaks. These can help reduce expenses associated with running the model.
-
Hardware Choices and Setup — Ensuring your hardware setup is correctly configured to meet the requirements of your LLM app can improve performance. This includes considering factors like CPU, GPU, and memory requirements.
-
Benchmarking — Testing and benchmarking your LLM app against predefined metrics can help evaluate its performance, track progress, and identify areas for improvement.
-
Iterative Refinement — This involves continuous evaluation and improvement of your LLM app based on feedback and performance metrics.
-
Memory Optimization — Techniques such as gradient accumulation, tensor sharding, and using lower precision formats can help reduce the memory consumption of your models.
-
Inference Speed Optimization — Techniques for accelerating LLM inference include developing more efficient models, pipeline orchestration, and using optimization libraries like Infery.
It's also important to continuously evaluate and iterate on your model's performance to ensure optimal results.
What metrics are used to measure successful LLM Apps?
To ensure the utility of LLM features outweighs their cost, we employ an Overall Evaluation Criteria (OEC) for assessing product-level utility alongside specific usage and engagement metrics to analyze the direct impact of these features.
AI Teams building with Klu.ai use Feedback to log user preference and behaviors to generations. Klu's ML automatically labels helpfulness, sentiment, and more.
Opportunities and Visibility
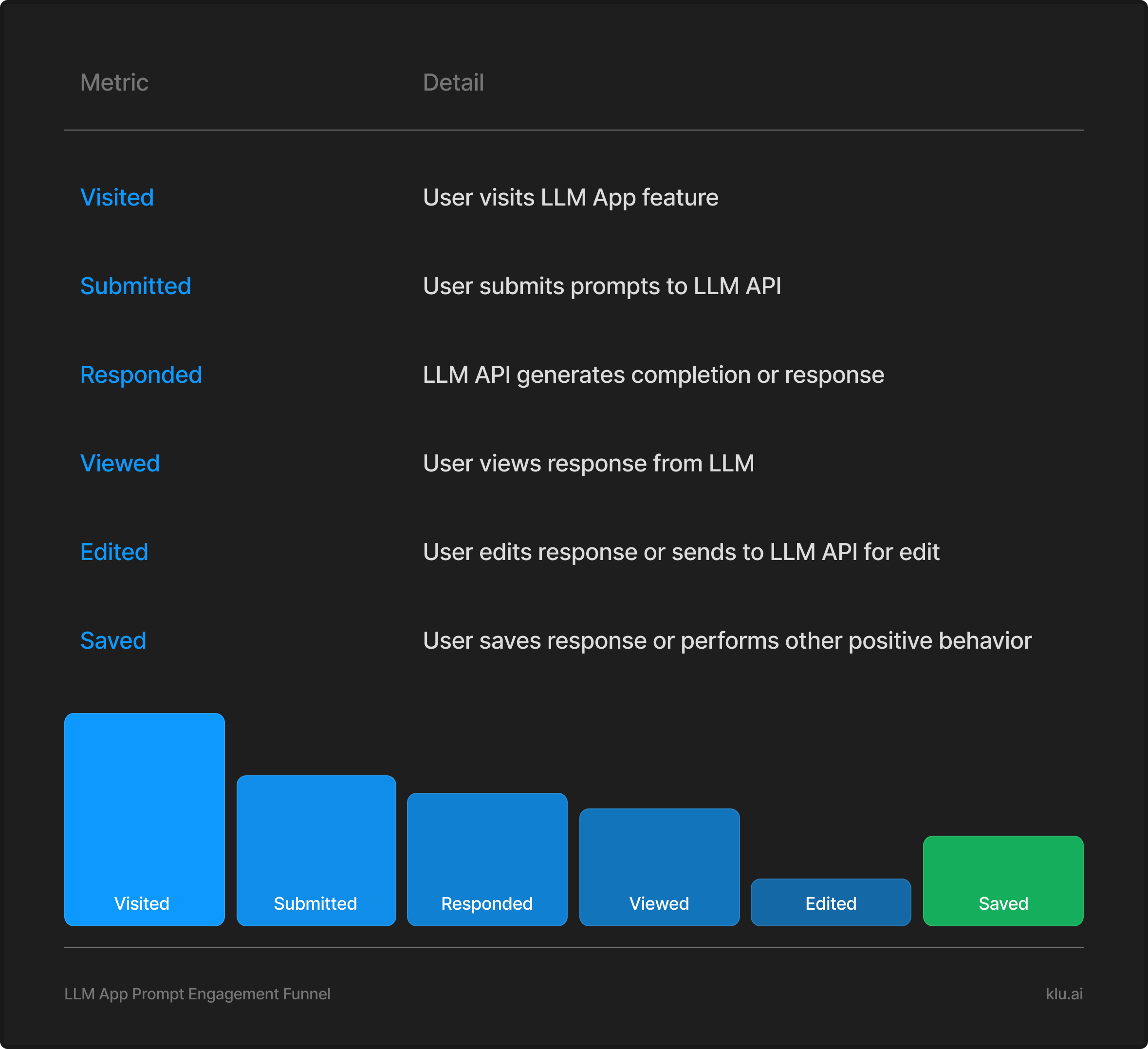
To gauge the interaction with the LLM, we track the number of times it's invoked (Opportunities for Content Suggestions), the volume and frequency of prompts sent (LLM Prompt Instances), and the responses generated (LLM Response Instances). Importantly, we also measure the responses that users actually view (Responses Viewed by Users), which are filtered for moderation and relevance.
User Interaction Metrics
To understand how users interact with the LLM, we measure the User Acceptance Rate, which reflects how often users choose to use the content suggested by the LLM. This rate varies by context, such as whether the content is included in the text or if it receives positive feedback in conversational scenarios. Additionally, we track Content Retention, which indicates the amount and frequency of LLM-generated content that users keep over time, providing insight into the value and relevance of the LLM's contributions.
Quality of Interaction Metrics
To assess interaction quality, we measure the average lengths of prompts and responses, the time between prompt issuance and response receipt, and user engagement duration. Additionally, we calculate the mean edit distance between user prompts and between LLM responses and retained content, indicating the extent of prompt refinement and content personalization.
Feedback and Retention Metrics
We measure the effectiveness of LLM interactions through user feedback volume, noting the count of Thumbs Up/Down responses, while being aware of potential bias from low response rates. Conversation metrics provide insights into the average length and duration of interactions, the frequency of conversations, and user engagement over time. Additionally, user retention is tracked through daily active users, retention rates for new users, and the adoption of features during initial sessions.
Creator Productivity Metrics
Evaluating creator productivity involves assessing the efficiency of content creation and editing with LLM assistance, measuring the reach and impact of such content, and quantifying the editing effort. We analyze the speed and quality improvements in content creation, track the number of users and sessions per document, and count the documents edited with LLM help. Additionally, we consider the retention of characters from LLM interactions, the volume of user and LLM edits, and the use of enriched content elements. The average time spent by users in editing mode is also a key metric.
Consumer Productivity Metrics
Evaluating consumer productivity involves assessing the efficiency and impact of content consumption for LLM-edited documents. Metrics include the number of users and sessions per document, the volume of documents read, and the frequency of interactions such as sharing and commenting. Additionally, we measure the average time users spend consuming content per document to understand consumption effort.
The optimization process for LLM apps is not a linear process but rather involves a solid evaluation framework that includes code-based evaluation, where custom heuristics defined in code assess specific aspects of the model's output.
Many teams implement automated, code-based evaluations instead of implementing custom heuristics defined by hand. Nearly all these techniques contribute to refining the optimization strategy, which may involve specific task fine-tuning to enhance the model's performance for particular applications.
Additionally, the use of a vector database can improve the efficiency of RAG with which the model generates responses. An internal human review is also a critical component, ensuring that the model's outputs align with expected standards and contribute to the overall effectiveness of the optimization strategy.