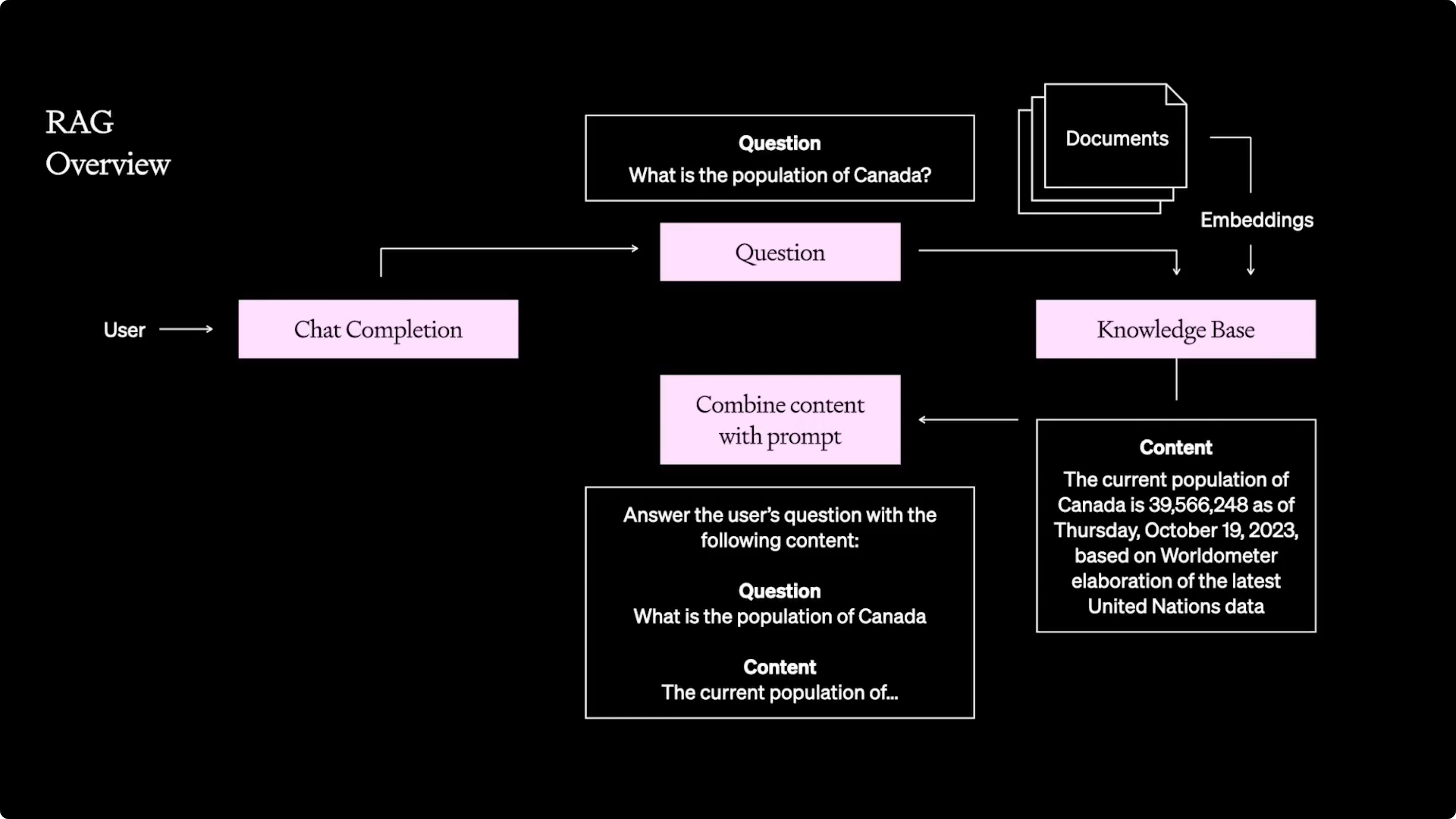
What is Retrieval-augmented Generation?
Retrieval-Augmented Generation (RAG) is a natural language processing technique that enhances the output of Large Language Models (LLMs) by integrating external knowledge sources. This method improves the precision and dependability of AI-generated text by ensuring access to current and pertinent information. By combining a retrieval system with a generative model, RAG efficiently references a vast array of information and remains adaptable to new data, leading to more accurate and contextually relevant responses.
Benefits of RAG include:
- More accurate responses — RAG provides more accurate results to queries by incorporating relevant and timely context from external sources.
- Improved reliability — By grounding an LLM on a set of external knowledge sources, RAG improves the reliability of the generated responses and helps mitigate the problem of "hallucination".
- Domain-specific knowledge — RAG enables more factual consistency and contextually appropriate answers for domain-specific tasks.
- Citation of sources — RAG allows generative AI systems to provide citations for their sources, improving auditability and trust.
RAG, short for Retrieval-augmented Generation, is a method that makes computer-generated answers more accurate and trustworthy by using additional information from outside sources. It's like having a smart assistant that quickly looks up facts in a library to make sure the answers it gives are right on target. This is especially useful for answering questions or creating content where being correct and relevant really matters.
How does Retrieval-augmented Generation work?
Retrieval-Augmented Generation (RAG) is a technique in artificial intelligence that enhances the capabilities of large language models (LLMs) by incorporating external information into the generation process.
This approach allows the AI to provide more accurate, contextually appropriate, and up-to-date responses to prompts.
RAG works by combining a retrieval model, which searches large datasets or knowledge bases, with a generation model, such as an LLM. The retrieval model takes an input query and retrieves relevant information from the knowledge base. This information is then used by the generation model to generate a text response.
The retrieved information can come from various sources, such as relational databases, unstructured document repositories, internet data streams, media newsfeeds, audio transcripts, and transaction logs.
The process of RAG can be broken down into two main steps: retrieval and generation. In the retrieval step, the model takes an input query and uses it to search through a knowledge base, database, or external sources. The retrieved information is then converted into vectors in a high-dimensional space and ranked based on its relevance to the input query. In the generation step, an LLM uses the retrieved information to generate text responses.
These responses are more accurate and contextually relevant because they have been shaped by the supplemental information the retrieval model has provided.
RAG was first proposed in a 2020 paper published by Patrick Lewis and a team at Facebook AI Research and has since been embraced by many academic and industry researchers.
It is particularly valuable for tasks like question-answering and content generation because it enables generative AI systems to use external information sources to produce responses that are more accurate and context-aware.
What are some common methods for implementing Retrieval-augmented Generation?
Retrieval-Augmented Generation (RAG) is a technique that enhances the capabilities of Large Language Models (LLMs) by incorporating external knowledge sources. This approach allows the model to provide more accurate and up-to-date responses.
There are several common methods for implementing RAG and maximizing LLM performance:
-
Naive RAG — This is the most common implementation of RAG. It involves retrieving relevant information from an external data source, augmenting the input prompt with this additional source knowledge, and feeding that information into the LLM. This approach is simple, efficient, and effective.
-
Agent-Powered RAG — In this approach, an agent formulates a better search query based on the user's question, its parametric knowledge, and conversational history. However, this method can be slower and more expensive as every reasoning step taken by an agent is a call to an LLM.
-
Guardrails — These are classifiers of user intent. They can identify queries that indicate someone is asking a question, triggering the RAG pipeline. This approach can significantly speed up the decision-making process.
-
Semantic Search — This technique helps the AI system narrow down the meaning of a query by seeking a deep understanding of the specific words and phrases in the prompt. It can be used in conjunction with RAG to improve the accuracy of LLM-based generative AI.
-
Vector Databases — RAG depends on the ability to enrich prompts with relevant information contained in vectors, which are mathematical representations of data. Vector databases can efficiently index, store, and retrieve information for things like recommendation engines and chatbots.
-
Reranking — This strategy involves retrieving the top nodes for context as usual and then re-ranking them based on relevance. It can help address the discrepancy between similarity and relevance.
-
HyDE — This strategy takes a query, generates a hypothetical response, and then uses both for embedding look up. It can dramatically improve performance.
-
Sub-queries — This involves breaking down complex queries into multiple questions, which can improve the performance of the RAG system.
-
Fine-tuning the Embedding Model — The standard retrieval mechanism for RAG is embedding-based similarity. Fine-tuning the embedding model can improve the performance of the RAG system.
The choice of retrieval method depends on the specific requirements of your application, including factors like speed, cost, and the complexity of the queries you expect to handle.
What are some benefits of Retrieval-augmented Generation?
Retrieval-Augmented Generation (RAG) significantly enhances the performance of AI models by leveraging external knowledge to generate more accurate and contextually appropriate responses. This approach is particularly effective in handling out-of-distribution queries, reducing the dependency on resource-intensive fine-tuning data.
RAG also improves efficiency by minimizing the need for continuous model training on new data, thereby lowering computational and financial costs. It ensures data security by keeping the data isolated from language models like GPT, and allows for dynamic, real-time updates, a feature not typically found in traditional Large Language Models (LLMs).
One of the key advantages of RAG is its ability to combat hallucination, a common issue in AI models, by compelling the language model to draw upon external data instead of relying solely on web-scraped information. This not only enhances the accuracy of the generated content but also promotes transparency by providing the specific source of data cited in its answer.
Finally, RAG offers scalability, making it a suitable solution for businesses of all sizes. It can adapt to increased data and user interactions without compromising performance or accuracy. These benefits collectively make RAG a powerful tool for enhancing the quality of generated content across various applications.
What are some challenges associated with Retrieval-augmented Generation?
Retrieval-augmented Generation (RAG) is a powerful approach that combines the capabilities of large-scale neural language models with external retrieval mechanisms. However, it comes with several challenges:
-
Latency — The two-step process of RAG, which involves retrieval followed by generation, can introduce latency. This is especially true when dealing with vast external datasets. The retrieval step can be time-consuming, which can slow down the overall response time of the system.
-
Relevance — Ensuring that the retrieved information is relevant to the task at hand is a significant challenge. The effectiveness of RAG in mitigating hallucinations or generating accurate responses largely depends on the quality and accuracy of the external dataset used for retrieval. If this dataset contains inaccuracies or biases, the RAG model might still produce misleading outputs.
-
Data Preparation and Indexing — Document data needs to be gathered, preprocessed, and chunked into appropriate lengths for use in RAG applications. Producing document embeddings and hydrating a Vector Search index with this data can be a complex and resource-intensive process.
-
Updatability — While the external knowledge source can be updated without needing to retrain the entire model, recreating the whole knowledge base can be time-consuming and inefficient. If you expect to update your source documents regularly, creating a document indexing process is necessary, which adds to the complexity.
-
Integration Complexity — The integration of external knowledge introduces increased computational complexity. This can be a challenge, especially when dealing with large-scale applications or when computational resources are limited.
-
Evaluation Metrics — The choice of metrics plays a pivotal role in evaluating the performance of a RAG system. Metrics such as Retrieval_Score and Quality_Score are used, but defining and calculating these metrics can be challenging.
Despite these challenges, RAG remains a promising approach for improving the performance of generative AI applications, as it allows models to tap into up-to-date, relevant, and domain-specific information.
What are common RAG frameworks?
RAG frameworks are particularly useful in applications such as chatbots, question-answering systems, content generation, real-time news summarization, and automated customer service. Common RAG frameworks include:
- Klu.ai Context — Built-in Context retrieval for all RAG needs with advanced filtering capabilities for multi-tenant scenarios.
- Vectorflow — High-throughput, fault-tolerant vector embedding pipeline designed for handling unstructured data at scale.
- Haystack — An end-to-end RAG framework for document search provided by Deepset.
- Langhcain — Integration frameworks that simplify the development of context-aware and reasoning-enabled applications.
- LLamaIndex — A data framework that helps create flexible data pipelines according to your domain, supporting applications based on LLMs.
- Unstructured — Open-source RAG frameworks that focus on ETL pipelines, providing data source connectors and data processing capabilities.
RAG frameworks enhance user trust, reduce AI hallucinations, and cut computational and financial costs by providing up-to-date information. However, challenges arise in selecting appropriate knowledge sources, fine-tuning the LLM for specific domains, and integrating the RAG framework with the LLM.
LlamaIndex
LlamaIndex, formerly known as GPT Index, is a data framework that enhances Large Language Models (LLMs) like OpenAI GPT-4 and Google Gemini by integrating them with external data. This integration, often referred to as Retrieval-Augmented Generation (RAG), unlocks new capabilities and use cases for LLMs.
LlamaIndex ingests data from diverse sources and formats, including APIs, PDFs, and SQL databases, and structures it into intermediate representations for efficient consumption by LLMs. It also provides a data retrieval and query interface for developers to input any LLM prompt and receive context and knowledge-augmented output.
The framework is technology-agnostic, compatible with evolving LLM technologies, and offers both high-level and low-level APIs for varying user expertise. The open-source LlamaIndex project has gained significant traction and has evolved into a company with venture capital backing, aiming to build an enterprise solution.
For practical usage, LlamaIndex can be installed via pip in Python. It supports natural language querying and conversation with data through query engines, chat interfaces, and LLM-powered data agents. It is also compatible with the latest OpenAI function calling API.
How do you evaluate Retrieval systems and RAG pipelines?
To evaluate RAG pipelines, you can follow these steps:
-
Choose evaluation frameworks — There are several frameworks available for evaluating RAG systems, such as ARES or RAGAs. Each framework focuses on different dimensions of evaluation, like context relevance, answer faithfulness, and answer relevance.
-
Tune RAG parameters — Optimizing RAG performance requires fine-tuning various interdependent parameters, such as chunk size, overlap, top K retrieved documents, embedding models, and LLM selection. You can use evaluation methods to determine the best combination of these parameters for your specific use case.
-
Perform retrieval and generation — Retrieval is the first step in an RAG pipeline, and its performance is crucial for obtaining relevant context passages. Generation, on the other hand, involves leveraging LLMs to generate responses based on the retrieved context. You can use reference-free evaluation methods, like RAGAs, to assess the quality of the generation process.
-
Iterate and improve — Evaluation should be an ongoing process, as it helps you identify areas for improvement and optimize your RAG pipeline's performance. By regularly evaluating your RAG system, you can ensure that it provides accurate and relevant results for your users.
Remember that the key to evaluating RAG pipelines is to consider multiple dimensions of performance, such as context relevance, answer faithfulness, and answer relevance. By following these steps and using appropriate evaluation frameworks, you can effectively assess and improve your RAG system's performance.
If you have a large context window, do you need RAG?
While having a larger context window in Large Language Models (LLMs) can improve their performance and usefulness across various applications, it does not necessarily eliminate the need for Retrieval-Augmented Generation (RAG). A larger context window allows LLMs to process more tokens as input, enabling them to give better answers based on a more comprehensive understanding of the input. However, LLMs can still struggle to extract relevant information when given very large contexts, especially when the information is buried inside the middle portion of the context.
RAG, on the other hand, combines a retrieval model with a generation model, allowing the AI to search large datasets or knowledge bases for relevant information and then generate a text response based on that information. This approach can help LLMs provide more accurate and contextually appropriate responses, even when dealing with vast external datasets.
While a larger context window can improve LLM performance, it does not necessarily replace the need for RAG. RAG can still provide valuable benefits in terms of accuracy and contextual relevance, especially when dealing with complex queries and large external knowledge sources.
What are some future directions for Retrieval-augmented Generation research?
Retrieval-Augmented Generation (RAG) merges pre-trained language models with retrieval mechanisms to generate responses that are contextually relevant and precise, drawing from vast knowledge sources and structured databases. The field is advancing towards enhancing the synergy between retrieval and generation for more accurate and context-aware AI outputs.
-
Active Retrieval Augmented Generation — This approach involves continually gathering information throughout the generation of long texts, which is essential in more general scenarios. One method proposed is Forward-Looking Active REtrieval augmented generation (FLARE), which iteratively uses a prediction of the upcoming sentence to anticipate future content, which is then utilized as a query to retrieve relevant documents to regenerate the sentence if it contains low-confidence tokens.
-
Multimodal Retrieval — Current research lacks a unified perception of at which stage and how to incorporate different modalities. Future research could focus on developing methods for retrieving multimodal information to augment generation.
-
Personalized Results and Context Windows — As users move from their initial search to subsequent follow-up searches, the consideration set of pages narrows based on the contextual relevance created by the preceding results and queries. This could lead to more personalized results and "Choose Your Own Adventure"-style search journeys.
-
Improved Accuracy and Relevance — Future research could focus on further improving the accuracy and relevance of generated responses. By retrieving relevant documents from its non-parametric memory and using them as context for the generation process, RAG can produce responses that are not only contextually accurate but also factually correct.
-
Content Generation — RAG's capabilities could be extended to content generation, assisting businesses in crafting blog posts, articles, product catalogs, and other forms of content. By amalgamating its generative prowess with information retrieved from dependable sources, both external and internal, RAG could facilitate the creation of high-quality, informative content.
-
Performance Gain with RAG — Future research could focus on determining the performance gain with RAG on various datasets. For example, both the performance of commercial and open source LLMs can be significantly improved when knowledge can be retrieved from Wikipedia using a vector database.
The envisioned advancements in Retrieval-augmented Generation (RAG) research promise to refine its utility across diverse domains, including search engines and content creation. These enhancements aim to enable RAG to deliver more precise, contextually relevant responses and facilitate the generation of high-quality, informative content by leveraging extensive knowledge bases and structured databases.