Reinforcement Learning from Human Feedback (RLHF)?
Reinforcement Learning from Human Feedback (RLHF) is like teaching a robot by giving it a thumbs up or thumbs down, helping it learn what to do in complex situations. It's a way to train AI by rewarding good behaviors and discouraging bad ones, without needing to write out every rule.
The reason we use this method of feedback is that humans are generally better at providing valuable feedback when they choose between two or more options and select the best one.
The most well-known, real-world application of RLHF is ChatGPT. This AI assistant was developed through significant efforts in creating example outputs and labeling model outputs to further fine-tune the models.
Reinforcement Learning from Human Feedback (RLHF) is a machine learning technique that combines reinforcement learning with human feedback to train AI agents, particularly in tasks where defining a reward function is challenging, such as human preference in natural language processing.
In RLHF, a reward model is trained directly from human feedback, which is then used as a reward function to optimize the agent's policy using reinforcement learning algorithms like Proximal Policy Optimization.
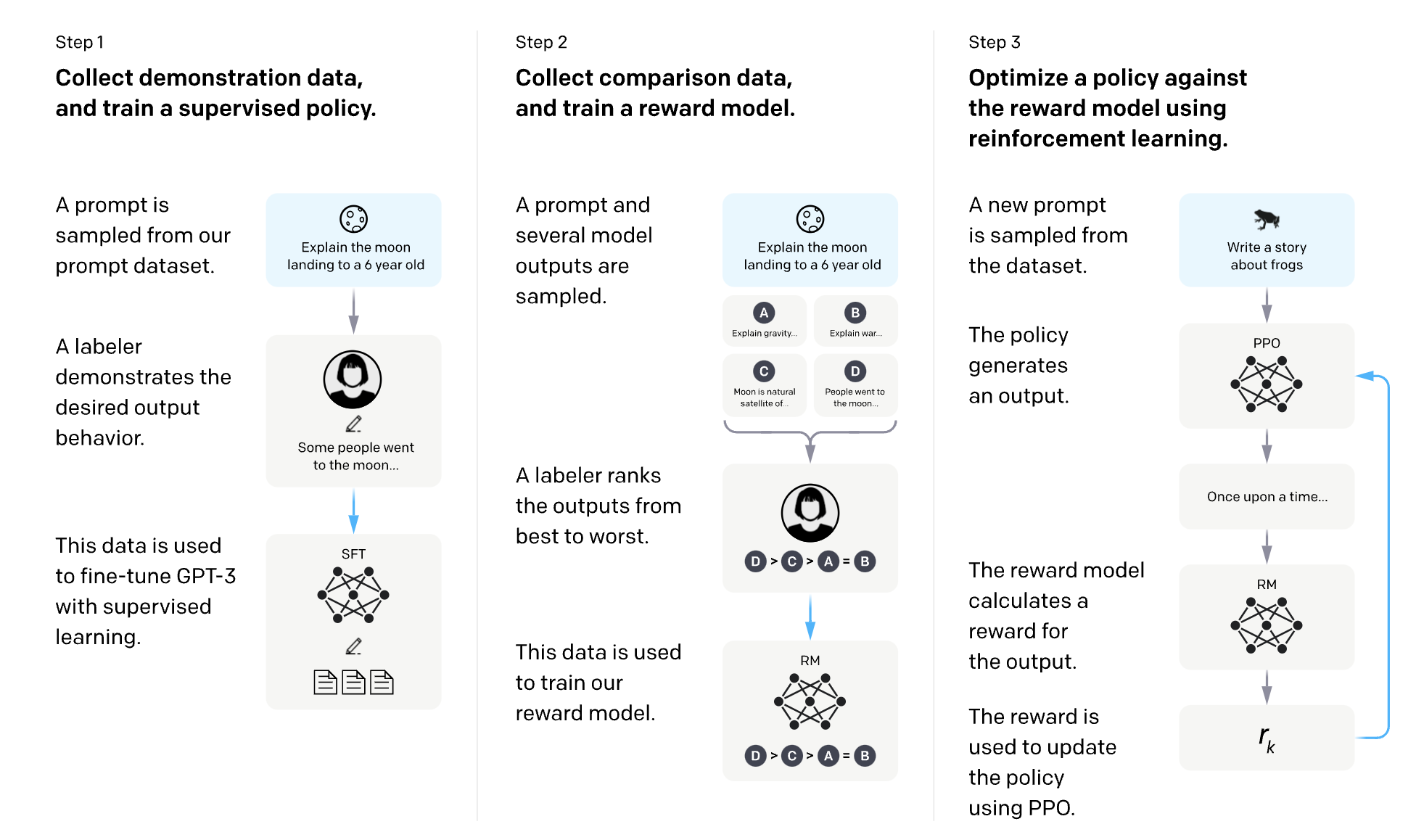
The process typically involves three core steps:
- Pretraining a language model (LM) or AI agent.
- Gathering data and training a reward model based on human feedback, often by asking humans to rank instances of the agent's behavior.
- Fine-tuning the LM or AI agent with reinforcement learning, using the reward model to guide optimization.
RLHF has been applied to various domains, including conversational agents, text summarization, and natural language understanding. It helps improve the robustness and exploration of reinforcement-learning agents, especially when the reward function is sparse or noisy.
The History and Evolution of RLHF
Reinforcement Learning from Human Feedback (RLHF) leverages reward models based on human preferences, rewards, and costs to guide AI behavior.
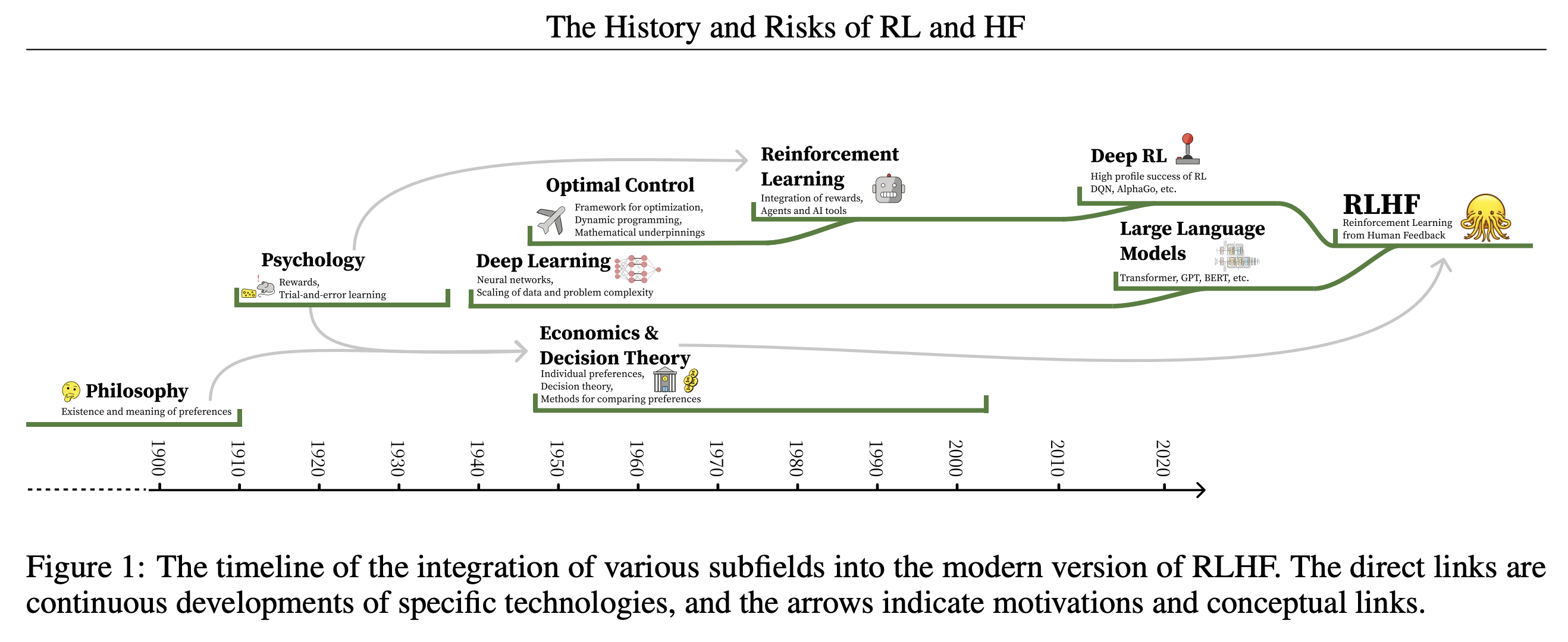
The concept of evaluating actions and states based on their relative goodness has evolved from early decision theory, such as The Port Royal Logic's 1662 principles of decision-making quality, to Bentham's 1823 utilitarian Hedonic Calculus, and Ramsey's 1931 work on Truth and Probability.
GPT 2018
GPT, also known as GPT-1, was a significant milestone in the evolution of language models, featuring 117 million parameters. This model was distinct from its predecessors in that it was trained using a technique called unsupervised learning, which allowed it to learn patterns in language data without explicit guidance on the desired output.
The training of GPT 2018 diverged from previous models by focusing on a transformer-based architecture, which was a departure from the recurrent neural networks commonly used at the time. This shift enabled the model to better capture the complexities of language through attention mechanisms and to process data more efficiently.
GPT-2 2019
GPT-2 expanded upon its predecessor by increasing the model size to 1.5 billion parameters, a tenfold increase from the original GPT's 117 million. This expansion allowed for more complex and nuanced understanding of language patterns.
Unlike GPT, which was trained to predict the next word in a sentence, GPT-2's training involved unsupervised learning on a diverse range of internet text. This approach enabled the model to generate more diverse and contextually rich text, capturing subtleties that were not possible with the smaller GPT model.
GPT-2, released in 2019 by OpenAI, represented a significant leap in the capabilities of language models. It was trained on a dataset of 8 million web pages and was capable of generating coherent and contextually relevant text passages, showcasing a remarkable understanding of language nuances.
The model's ability to generate news articles, stories, and even poetry highlighted its potential as a powerful tool for a wide range of natural language processing tasks.
GPT-3 2020
GPT-3's architecture is similar to that of its predecessors, but it's much larger, with 175 billion parameters. This scale allows it to have a broader understanding and generate more nuanced text. The training process also differed; it involved not just more data, but also more diverse datasets and more rigorous training methods, including novel techniques to improve the model's ability to generalize from the data it was trained on.
GPT-3, unveiled by OpenAI in 2020, was a groundbreaking advancement in the field of language models. With 175 billion parameters, it was the largest and most powerful model of its time, capable of producing text that was often indistinguishable from that written by humans.
InstructGPT 2021
InstructGPT, also known as Davcinci (models 001 to 003), is an intermediary model between GPT-3 and the next-generation GPT, featuring 175 billion parameters like its predecessor. The key difference in its training involves a more refined approach to incorporating human feedback. While GPT-3 was primarily trained on data and patterns found in its source material, InstructGPT's training process was augmented with human feedback to better understand and execute user instructions. This shift towards a more interactive training process with human-in-the-loop methodologies represents a significant evolution in the development of language models.
InstructGPT, introduced by OpenAI in 2021, was an evolution of the GPT-3 model, fine-tuned to follow user instructions more accurately. This model was trained using a combination of supervised learning and reinforcement learning from human feedback, resulting in improved task performance and alignment with user intentions.
GPT-3.5 2022
GPT-3.5, released in 2022, uilt upon the success of its predecessors by enhancing its understanding and generation of nuanced text. This iteration was particularly focused on improving the model's performance on more complex tasks, further blurring the line between AI-generated and human-generated content.
It uses the same pretraining datasets as GPT-3 but includes additional alignment layers to better comply with human values and policies.
This model is capable of understanding and generating natural language or code, and it has been recognized for its ability to deliver consistently accurate and relevant results.
Unlike its predecessors, GPT-3.5's training involved more targeted data, refined reward models, and a broader set of instructions to better capture nuances in human language and intent.
Reinforcement Learning
Modern reinforcement learning (RL) methods optimize reward-to-go estimates, a concept derived from operant conditioning and the Law of Effect, which assesses the value of an action based on its expected future rewards. In RL, rewards serve as signals to adjust behavior towards specific goals, with the underlying premise that an algorithm's performance is linked to expected fitness or utility.
This perspective views RL as agents acting within environments, a notion that has driven the advancement of RL technology. However, this singular reward function approach can oversimplify complex individual desires and preferences.
Historically, RL's success in adaptive control, where reward and cost functions define clear success metrics, such as minimal energy use in physical systems, has been notable. This success extends to achievements in gaming, managing dynamic systems like nuclear reactors, and robotic control. Yet, these reward or cost functions, unlike human preference models, typically yield a clear optimal behavior.
Reinforcement Learning from Human Feedback (RLHF) advances AI by using human feedback to train reward models, guiding AI towards desired behaviors. This technique is crucial for developing Large Language Models (LLMs) like ChatGPT, enhancing their relevance, engagement, and safety.
The process involves human feedback in the form of evaluations, which accelerates and refines the AI's learning. For example, in traditional Reinforcement Learning (RL), a robot learns to make coffee through trial and error. RLHF, however, allows a human to guide the robot, expediting and improving the learning process.
The Learning Loop
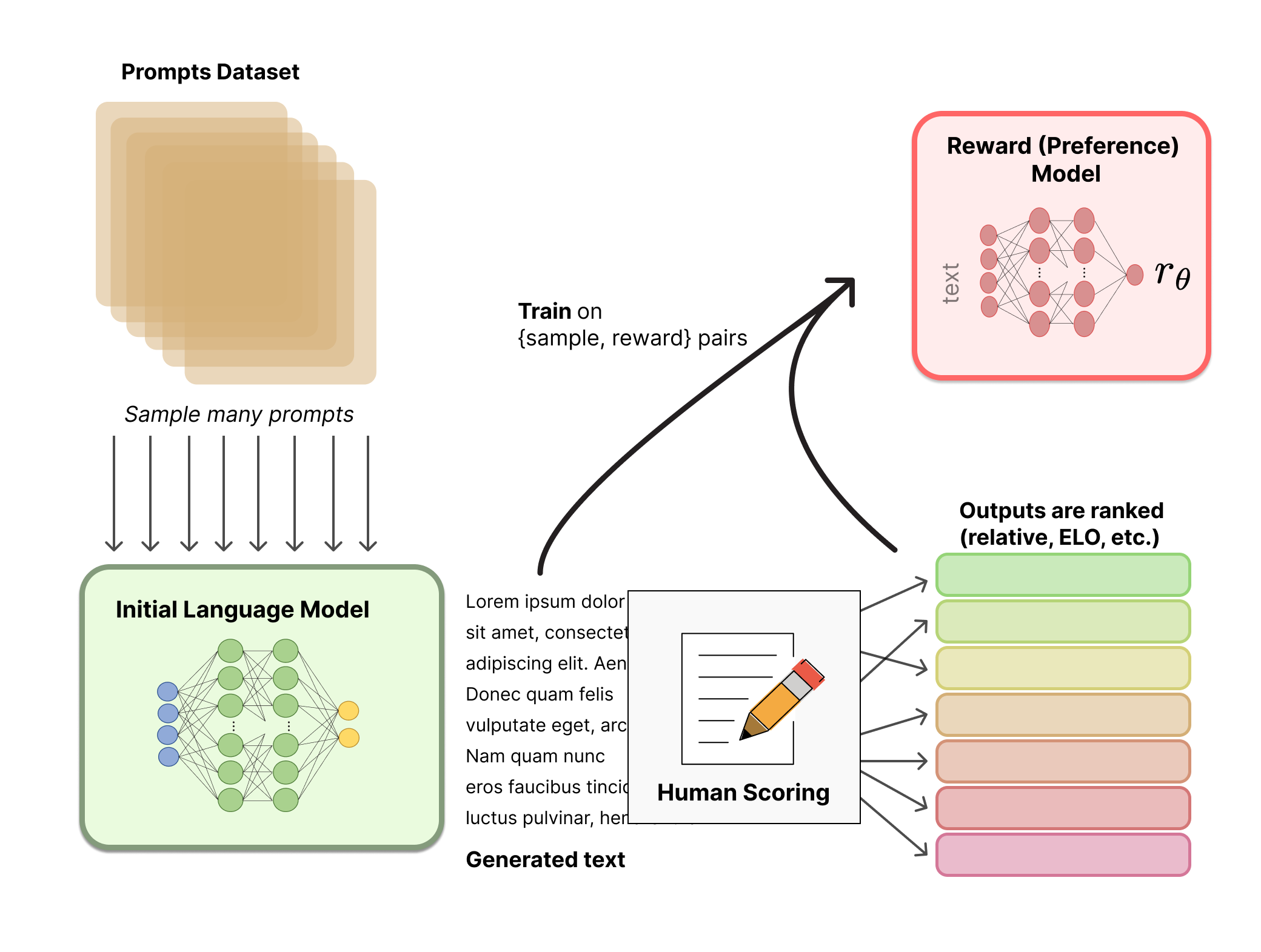
The Reinforcement Learning from Human Feedback (RLHF) loop is an ML technique that integrates human feedback into the reinforcement learning (RL) process. In traditional RL, an agent learns to perform tasks by maximizing a reward signal, which is typically predefined by the environment or the task itself.
HuggingFace RLHF Workflow
However, in RLHF, the reward signal is derived from human feedback, which allows the model to align more closely with human values, preferences, and goals.
The RLHF loop generally involves the following steps:
-
Pretraining: A model is pretrained to respond to diverse instructions. This model serves as the starting point for the RLHF process.
-
Reward Model Training: Human feedback is used to generate a reward model (RM). This involves collecting data where humans provide feedback on the outputs generated by the model. The feedback could be in the form of rankings, comparisons, or direct ratings. The reward model is then trained to predict the quality of outputs based on this feedback.
-
Policy Learning: With the reward model in place, the next step is to train a policy that maximizes the rewards as predicted by the RM. This involves using techniques like Proximal Policy Optimization (PPO) and ensuring that the policy does not deviate too much from the original pretrained model (to avoid overfitting to the reward model or learning undesirable behaviors).
-
Human-in-the-loop: Throughout the process, humans are involved in providing feedback, which is crucial for the reward model to accurately reflect human preferences. This feedback loop allows the model to continuously improve and align with human goals.
RLHF is particularly useful for tasks where defining a clear reward function is challenging, such as natural language processing, generative AI art, or other creative domains where human judgment is key to evaluating the quality of outputs. It has been used in various applications, including language models like OpenAI's ChatGPT and InstructGPT, and has shown promise in improving the alignment and robustness of AI systems.
The effectiveness of RLHF depends on the quality and consistency of human feedback. Biased or inconsistent feedback can lead to a biased model. Therefore, careful consideration is needed to ensure that the feedback collected is representative and reliable.
Reward Models and Safety
Reward models are typically evaluated by how well they predict outcomes on data they haven't seen before. To improve this, we need simple examples that challenge the model to recognize high-quality text across different situations.
Inspired by benchmarks for instruction- and chat-tuned LLMs, we should evaluate reward models in contexts that mirror their application.
For instance, benchmarks assessing consistency in reward model scores are valuable, but AI team needs better tools for the diverse RLHF use cases. Benchmarks should include representative examples across various categories (e.g., reasoning, generation ability, factuality) to test the reward signal.
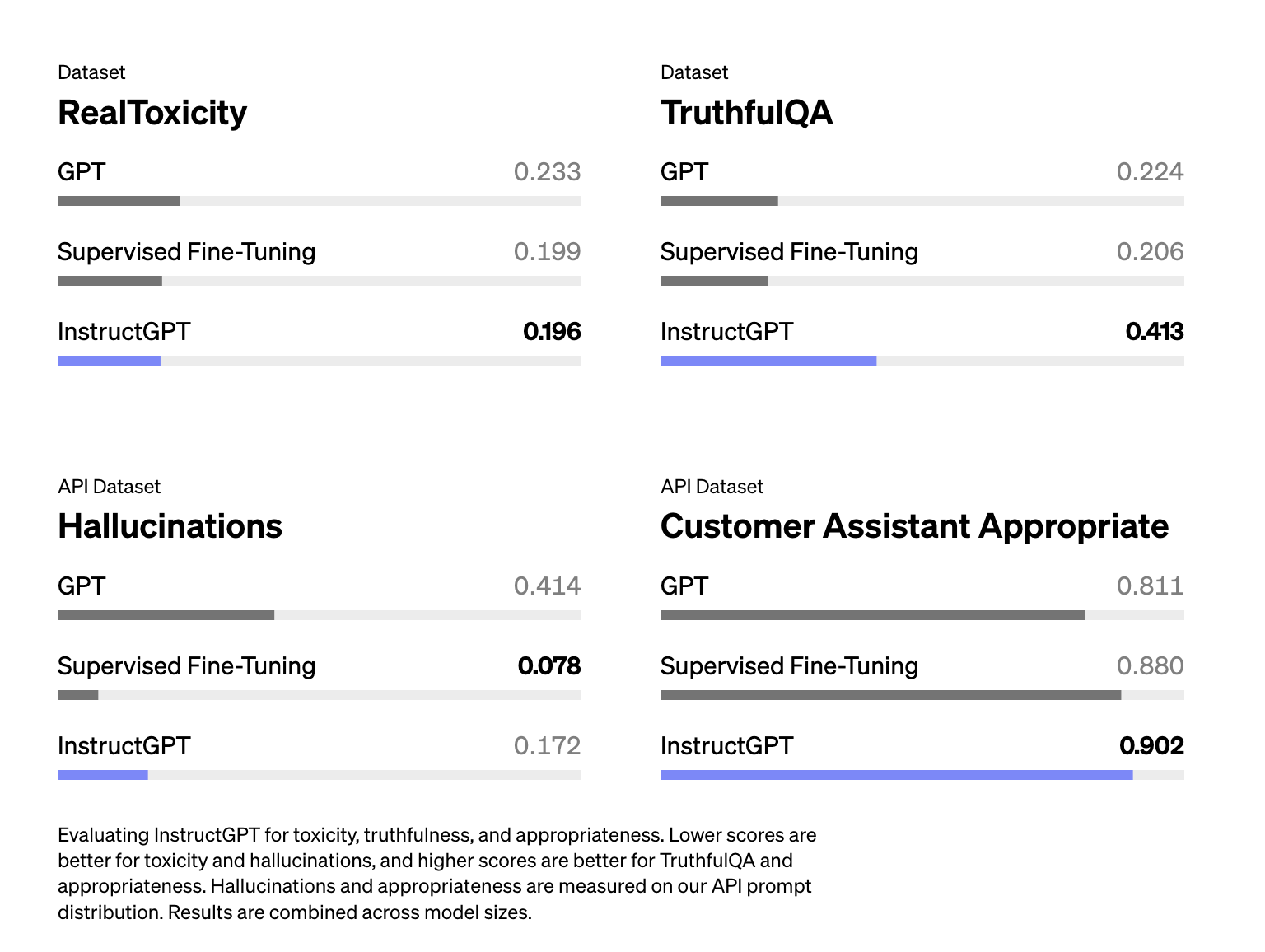
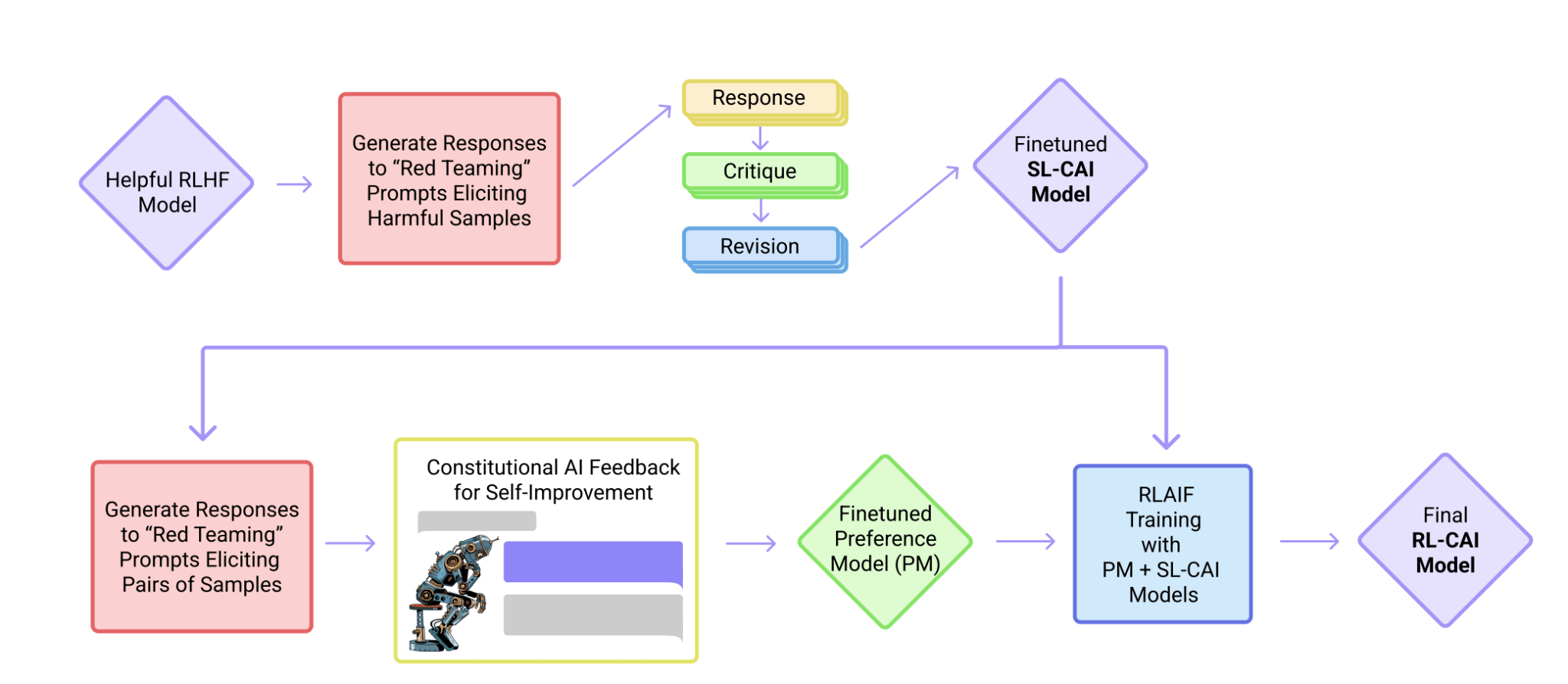
To ensure the safety and appropriateness of language models, a process called red-teaming is used. This involves testing the models to see if they can handle challenging scenarios without producing harmful or toxic content. Specifically for reward models, which guide AI behavior, red-teaming means checking if the model can distinguish between harmful and neutral content and making sure it's not easily tricked by misleading inputs.
Experts often use existing datasets, such as RealToxicityPrompts, to find tricky prompts that could lead to toxic responses. This helps in identifying weak points in the models. One challenge is that reward models used in training are not usually open for external testing, which raises concerns about how well they can be evaluated and improved over time.
The ultimate goal for reward models in the RLHF framework is to improve the tasks they are applied to, aligning with what humans consider good outcomes. It's important to decide what kind of human preferences these models should learn from.
While setting clear standards might limit the model's performance at first, it's a necessary step to ensure that the technology works well for everyone involved and avoids causing harm when used in language model development.
What is Reinforcement Learning from AI Feedback (RLAIF)?
RLAIF, or Reinforcement Learning with AI Feedback, is an advanced machine learning approach where an artificial intelligence system learns to make decisions based on feedback from its environment. It's a subfield of AI focused on action selection strategies. In this method, an AI system is trained to take certain actions with the goal of maximizing some type of reward.
Over time, through a process of trial and error, the AI improves its behavior based on the positive or negative feedback it receives from its actions, thus increasing the cumulative reward. The aim of RLAIF is to develop algorithms and techniques that allow computer systems and robots to learn optimal behaviours by interacting with their environment and learning from their mistakes.
Constitutional AI and RLAIF
Constitutional AI (CAI) trains AI systems to align with human values using a "constitution" of principles. It combines supervised learning, where an initial model is refined through self-critique, with reinforcement learning, where a preference model developed from AI's choices serves as a reward signal.
What are the key components of RLHF?
Reinforcement Learning from Human Feedback (RLHF) is a type of machine learning that combines reinforcement learning (RL) and supervised learning from human feedback. In RLHF, an AI system learns from both its own experiences in an environment (as in traditional RL) and from feedback provided by humans or other AI systems. This feedback can help the AI system to learn more quickly and to avoid making harmful or undesirable actions.
There are three key components to RLHF in AI:
-
A reinforcement learning algorithm: This is used to enable the AI system to learn from its own experiences in an environment.
-
Human feedback: This is used to provide additional guidance to the AI system, helping it to learn more quickly and to avoid making harmful or undesirable actions.
-
A method for combining the RL algorithm and human feedback: This is used to integrate the learning from the RL algorithm and the human feedback into a single, coherent learning process.
Gathering Human Feedback
Reinforcement Learning from Human Feedback (RLHF) is a technique that enhances AI models by combining traditional reinforcement learning with insights from human feedback. It's particularly useful for creating language models and other AI systems that need to exhibit human-like behavior.
The RLHF-Blender is a tool that provides a flexible interface for experimenting with different types of feedback, such as showing examples, ranking outcomes, comparing choices, or giving instructions in natural language. It also allows for the study of how human input can influence the effectiveness of AI training.
RLHF-Blender is a modular framework for researching diverse feedback types in AI model training. It standardizes the process of learning from human feedback, which is essential for RLHF applications.
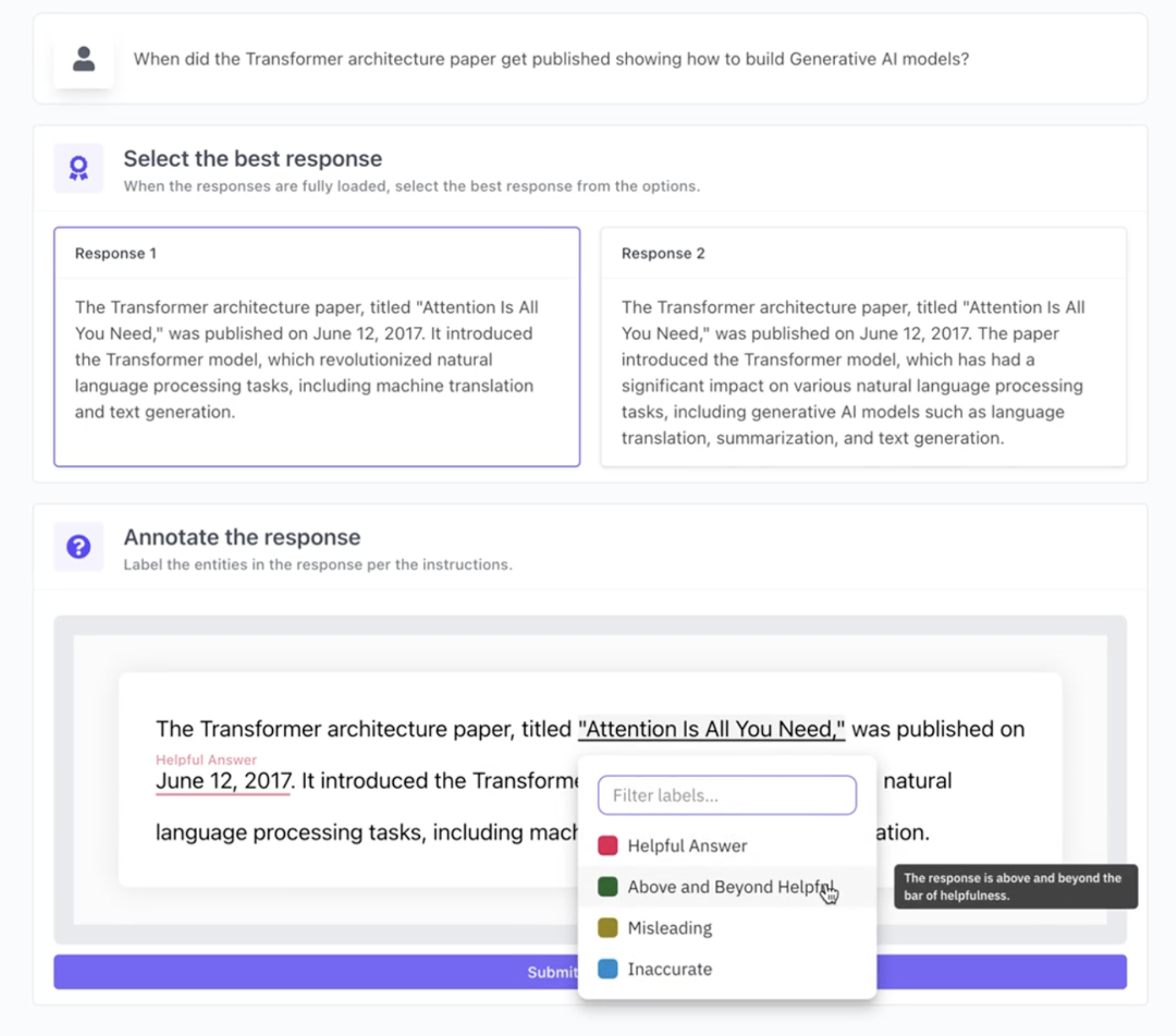
A reward model (RM) evaluates (prompt, response) pairs, scoring them to guide language models (LMs) towards human-preferred outputs. This method enhances text quality, minimizes biases, and aligns AI with user intent.
RLHF is crucial in robotics, gaming, and recommendation systems, overcoming RL's feedback limitations. Techniques like Inverse Reinforcement Learning (IRL) further enhance RLHF effectiveness.
Post-deployment feedback interfaces are vital, offering options such as upvote/downvote, selecting from multiple responses, or direct text edits for continuous model learning.
Despite its benefits, RLHF faces challenges like the cost of large-scale human feedback and feedback quality variability, which can affect model performance. Expert and novice feedback disparities and the resource intensity of models like ChatGPT are notable concerns.
What are some of the challenges in RLHF?
While powerful and among the best techniques for aligning LLM outputs with human preferences, RLHF faces several challenges and limitations, which can be categorized into three main areas:
Collecting quality human feedback
- Modeling human preferences is difficult due to their fluidity, context-dependence, and complexity.
- Selecting a representative sample of annotators who can provide consistent and accurate feedback is challenging.
Accurately learning a reward model from human feedback
- Evaluating reward models is difficult and expensive, especially when the true reward function is unknown.
- Reward hacking can occur, leading to unintended consequences and undesirable behavior.
Optimizing the AI policy using the imperfect reward model
- RLHF-trained models can suffer from issues such as hallucinations, bias, and susceptibility to adversarial attacks.
- Fine-tuning reduces the diversity of samples produced by a model, leading to "mode collapse".
To address these challenges, researchers emphasize the importance of recognizing the limitations of RLHF and integrating it into a broader technical framework that includes methods for safe and scalable human oversight, handling uncertainty in learned rewards, adversarial training, and transparency and auditing procedures.
What are some of the recent advances in RLHF?
Reinforcement Learning from Human Feedback (RLHF) is a cutting-edge field in AI that enhances AI models by integrating human insights into their learning journey. Imagine teaching a child by giving praise or constructive criticism; RLHF works similarly for AI, using human feedback to refine and elevate the AI's abilities.
Key recent developments in RLHF include:
- Enhanced integration of RL and human feedback, optimizing the benefits of both while addressing their limitations.
- New strategies to mitigate bias in human feedback, ensuring AI systems learn effectively and impartially.
- More efficient RL algorithms, accelerating the AI's learning from environmental interactions.
What are some potential applications of RLHF?
RLHF finds its utility across a spectrum of sectors, showcasing its versatility and impact.
-
Natural Language Processing (NLP): RLHF has been effective in diverse NLP domains, including crafting more contextually appropriate email responses, text summarization, and conversation agents. For instance, OpenAI's ChatGPT, which uses RLHF, is a compelling example of a language model trained to generate human-like responses.
-
Education, Business, Healthcare, and Entertainment: RLHF can generate solutions for math problems and coding, and has broad use cases across sectors like education, business, healthcare, and entertainment. In healthcare, RLHF can be used to train machine learning models to diagnose diseases, with the model improving its accuracy based on human feedback.
-
Video Game Development: In the gaming industry, RLHF has been employed to develop bots with superior performance, often surpassing human players. Agents trained by OpenAI and DeepMind to play Atari games based on human preferences are examples of this application.
-
Robotics and Autonomous Machines: RLHF is revolutionizing the capabilities of robots and autonomous systems. With human feedback, robots can efficiently and safely learn to perform tasks in real-world environments. Human trainers guide the robots’ actions, enabling them to navigate complex settings, manipulate objects, and execute tasks with enhanced precision.
-
Computer Vision: RLHF has several applications in computer vision, including training models for classification, object detection, and segmentation. It helps fine-tune models by randomly varying the outputs and comparing evaluation metrics.
-
Recommender Systems: RLHF proves valuable for enhancing recommendation accuracy and personalization in recommender systems.
-
Social Impact: RLHF has the potential to positively impact areas such as misinformation, AI value-alignment, bias, AI access, cross-cultural dialogue, industry, and workforce.
These applications demonstrate the transformative potential of RLHF in various fields, leveraging human expertise and feedback to guide AI agents in decision-making, leading to increased efficiency and effectiveness in learning.