While Claude and Llama 2 create LLM optionality for emerging use cases, the clear state of the art is still GPT-4.
Beyond benchmark evals, OpenAI's GPT-4 wins in subtle ways from its retention of details within input prompts, ability to follow instructions (especially for code or machine-readable JSON outputs), and the consistent quality of generations.
Most of our customers who initially avoided GPT-4 in production did so for two reasons: privacy and speed. Until recently, OpenAI was seemingly liberal with its analysis of API usage for studying behavior, and this monitoring confused many as the firm using this data for future model training. OpenAI has since clarified their privacy stance in late 2023.
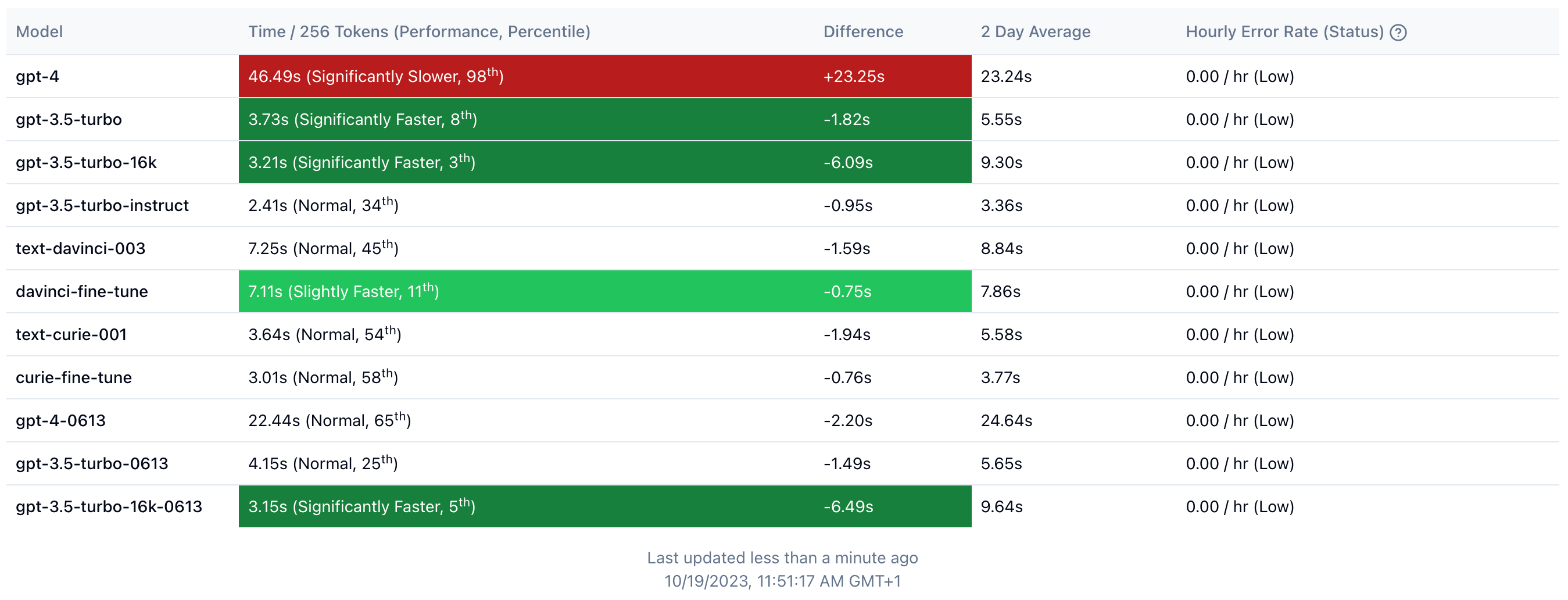
Additionally, the OpenAI API performance varies heavily by time of day with an average per-token speed of 100ms, but hovering around 200-300ms on a bad day.
Many startups, including Klu moved to Azure OpenAI services for various reasons, but there's a standout benefit: speed.
Azure deployments average a 2-3x token speed performance improvement over the public OpenAI API. These benefits come with an additional layer of considerations from API versions including prompt behavior to lower per-deployment token rate limits than OpenAI's.
What's different on Azure OpenAI
The biggest surprise when moving our services over to Azure was the collection of subtle differences – especially the API Version – which degraded or completely changed our prompts.
Here's what you need to know at a glance:
- OpenAI services deploy on a per-region basis
- Models deploy within those regions
- Each region and model has its own token and request rate limits
- Microsoft approves rate limit increases in 60-90 days
- Calling models requires an API version parameter
- Different API versions produce wildly different responses
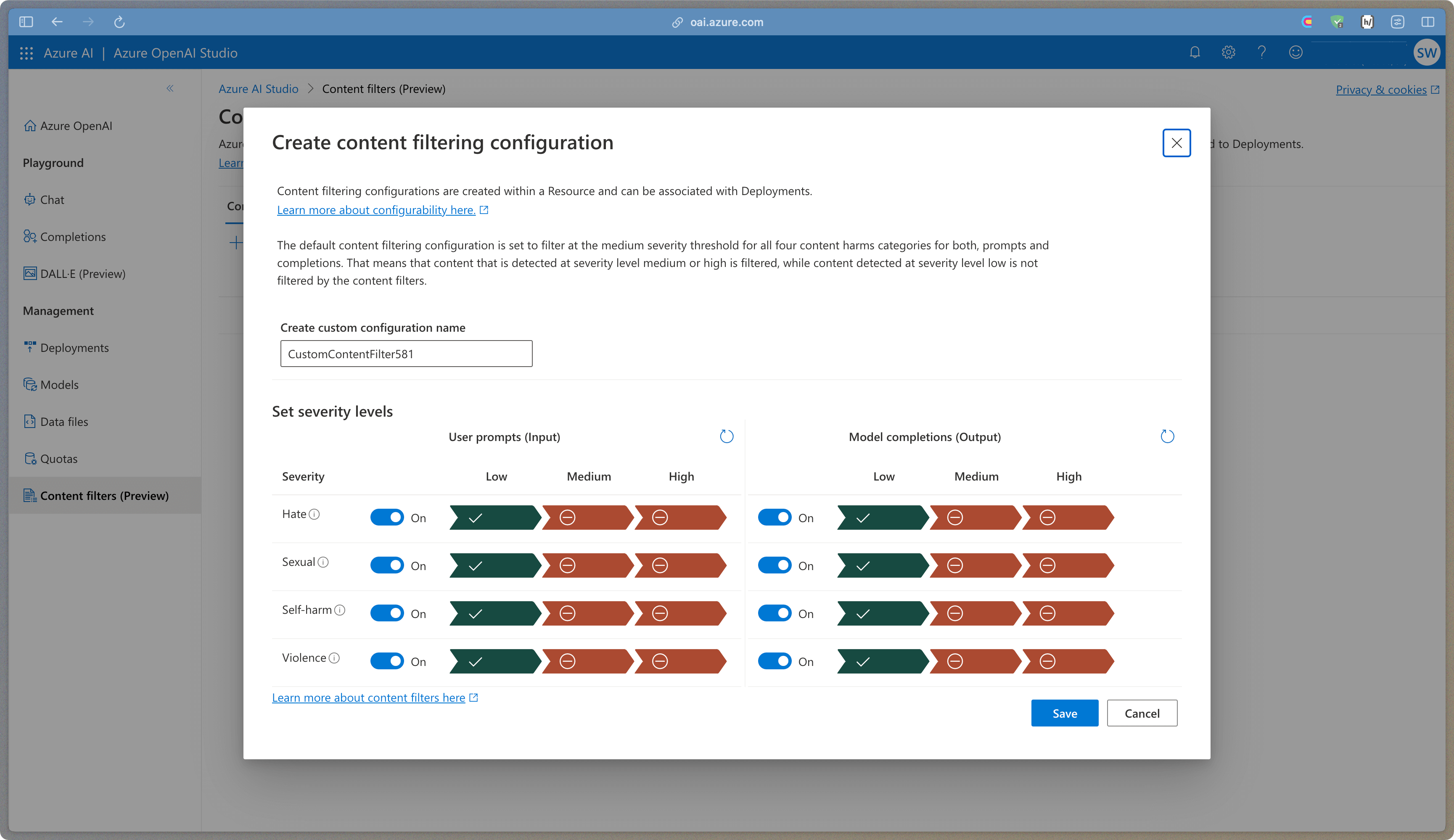
- Azure OpenAI comes with content filtering on by default
- Microsoft monitors all Azure OpenAI prompts and generations by default
On Azure, you will deploy OpenAI services on a per-region basis (US East, London, France, etc.) and then deploy the specific models (GPT-4, GPT-3.5-turbo, Whisper, etc) that you wish to use.
You may name both region and model endpoints anything you want. Choose wisely, this may come back to haunt you when you have a non-obvious naming structure. We tend to mirror the stock model name whenever possible.
Azure OpenAI token and request rate limits are lower than OpenAI's public APIs on a per-region basis – without a multi-region strategy, you will quickly hit token limits even with pilot projects. You can request increased limits, but expect to not hear back from anyone for months or longer.
Turned on by default, Azure comes with content filtering that will filter both incoming prompts and generative responses. You can create custom content filters and assign those to your model deployments.
Content filtering will incorrectly filter some requests with agentic-like behavior like summarizing the content of the scraped HTML from a website despite not containing any inappropriate content. My assumption is that this will improve over time, but we currently disable it and use our own monitoring service to prevent false positives.
API versions are a simple parameter in the OpenAI request scheme, however these have the single greatest impact on the generation. I found that a few of the API versions crippled the responses of GPT-3.5-turbo to something that felt like an early Davinci model. Whether a temporary bug or not, we quickly learned to pay attention to this setting as it will influence generations more than temperature, system message, or the prompt itself.
How to get started on Azure OpenAI
If you're reading this and you're just starting out with a new idea or project, Microsoft has the most generous startup credits offering on the market – the Pegasus program has around $300k in total credits on different platforms, including Azure. We used the credits to deploy 8xA100 servers for fine-tuning Llama models and experimenting with OpenAI GPT-4 – both of which you will struggle to do on any other cloud provider this year. Check out the startup program, it's free and there are many benefits.
You're going to need an Azure account and unfortunately I still have yet to figure out the best way of signing up. You can use your GitHub account, but then Microsoft treats you like a second-class citizen across their other properties and programs. My recommendation would be to start with a Microsoft account, but compared to AWS and GCP, it's fairly confusing if you don't participate in their ecosystem. If it's your first time using Azure, you might recognize the UI from other Microsoft hits like Windows Vista and the Whistler program.
Once you are set up, you need to get used to the following mental model. Unlike AWS that switches regions as part of the navigation, Azure region deployments will show up in a list similar to GCP. Azure changed how to deploy a new service instance a few times this year, but the method I always use is to head over to the Azure OpenAI Studio and follow the deploy link there.
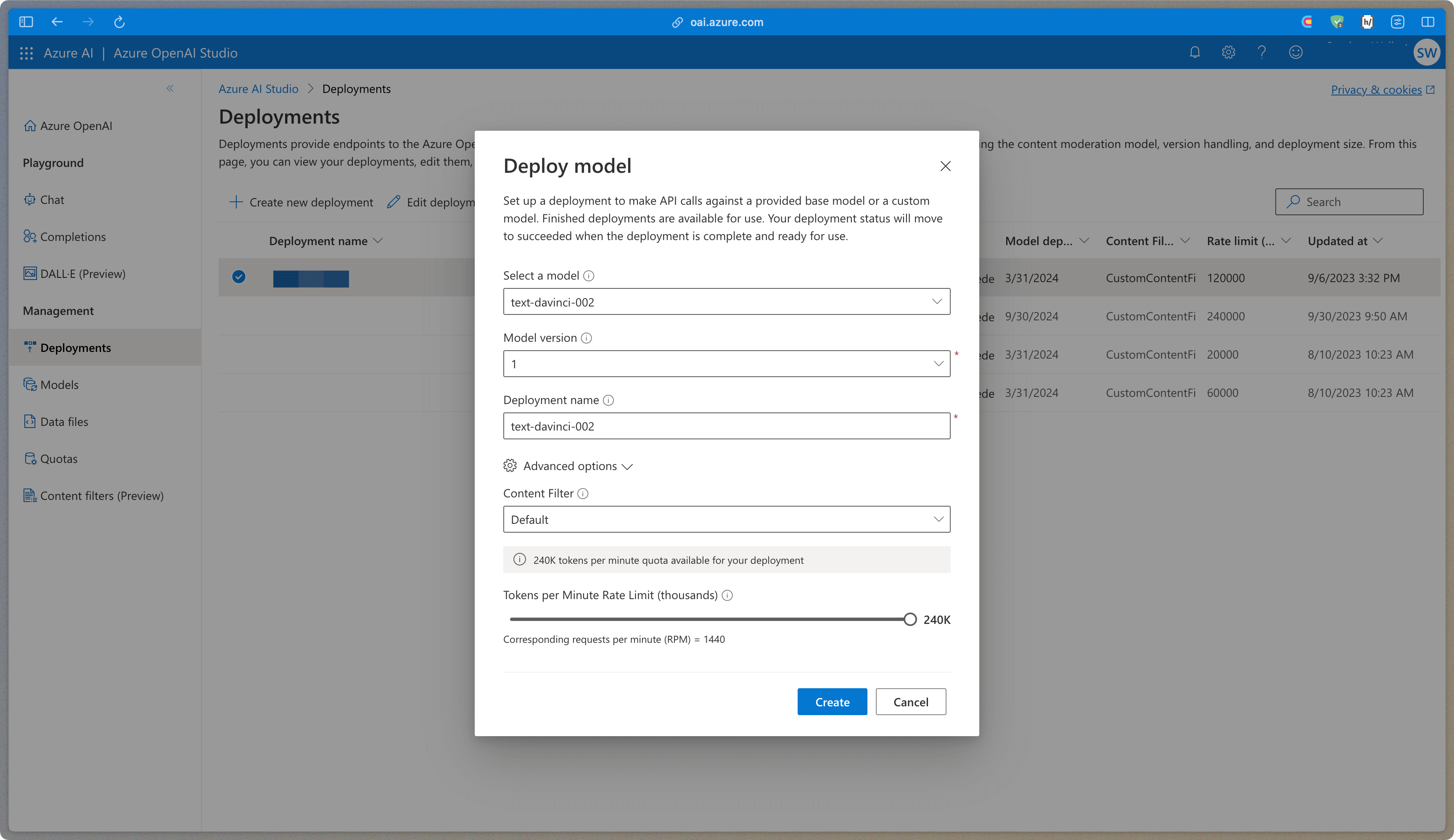
After you've deployed your service, you can now access that service in the Azure OpenAI portal. Get used to toggling back and forth, and think of it like this: Azure is for your instance deployment, Azure OAI Studio is for your instance config. When deploying (or editing a deployment) you have options for naming, rate limits, and content filtering.
To turn content filtering off, you will need to do the following. Create a new content filter, set all prompt and completion filtering parameters to off, and save it. Again, you can name it anything, I usually name it "Off" as it will display in the Deploy Model UI.
You can request GPT-3.5 and GPT-4 access and rate limit increases. You need to have your Azure Cognitive Services number (optional) and your Azure Subscription ID when filling these out. Access to GPT-4 applies to all regions, while rate limits are on a per-model, per-region basis – yes, you will be filling out many of these forms if you wish to increase your limits.
You can request an exemption from abuse monitoring and human review of your data using this form. Once approved by Microsoft, no prompts or completions are stored centrally by Microsoft for review.
Our takeaways from using Azure OpenAI
We replaced all OpenAI-powered Klu services with Azure OpenAI, with the exception of fine-tuning due to Azure platform limitations. To handle performance and rate limits, we built a multi-region router on Cloudflare that combines our OpenAI Azure deployments into one endpoint for platform services like automated evals and document embedding.
If we started Klu over today, we would continue to use Azure OpenAI over Google Vertex or AWS Bedrock despite their model selection. Edge platforms like Cloudflare and Vercel are likely not far from being competitive alternatives, especially for Llama 2. Outside of Llama 2 and Anthropic's Claude, we have not seen production adoption of other LLMs. Azure is a messy platform, but the ease of deploying and manging across regions is much easier than with the other cloud platforms.
Here are the clear upsides:
- Deploy in your private cloud
- 2-3x faster speeds than the OpenAI APIs
- The most free credits for startups
- The best UX for managing multi-region deployments
But they come at a cost:
- Waitlist for GPT-4 and rate limit increases
- Fine-tuning is non-existent for GPT-3.5 and Davinci
- Delays in getting the latest OpenAI updates (lags 2-4 weeks)
- Some Azure regions not receiving updates or investment (eg. West EU)
We operate Klu services in AWS, Azure and GCP, and each has their strengths. Unfortunately, both Bedrock and Vertex have awkward auth and API/SDK patterns, and I hope that the industry converges on OpenAI's innovations as the API standard for interacting with models. You can see the demand for this standard in the traction of developer projects like LiteLLM.
What is the Azure OpenAI rate limit?
The rate limits for Azure OpenAI GPT-3.5-Turbo and GPT-4 models are as follows:
| Model | Tokens Per Minute (TPM) | Requests Per Minute (RPM) |
|---|
| GPT-3.5-16k | 300,000 | 1800 |
| GPT-4 | 40,000 | 240 |
| GPT-4 Turbo | 150,000 | 900 |
Azure OpenAI does not currently accommodate requests for rate limit increases due to capacity constraints.
Please note that these are the default rate limits and they can vary based on the specific model version and the Azure region. For example, during the limited beta rollout of GPT-4, the default rate limits for gpt-4/gpt-4-0314 were 40k TPM and 200 RPM, and for gpt-4-32k/gpt-4-32k-0314 were 80k TPM and 400 RPM.
Also, Azure OpenAI evaluates the rate of incoming requests over a small period of time, typically 1 or 10 seconds, and then determines if the rate limits are being exceeded. If it estimates that the rate could exceed, error 429 is reported.
It's also important to note that Azure OpenAI has a dynamic rate limit system, which means the rate limit can change based on the load on the system and other factors.
Other Azure OpenAI limits vary depending on the specific model and resource.
| Limit Name | Limit Value |
|---|
| OpenAI resources per region per Azure subscription | 30 |
| Default DALL-E 2 quota limits | 2 concurrent requests |
| Default DALL-E 3 quota limits | 2 capacity units (6 requests per minute) |
| Maximum prompt tokens per request | Varies per model |
| Max fine-tuned model deployments | 5 |
| Total number of training jobs per resource | 100 |
| Max simultaneous running training jobs per resource | 1 |
| Max training jobs queued | 20 |
| Max Files per resource | 30 |
| Total size of all files per resource | 1 GB |
| Max training job time (job will fail if exceeded) | 720 hours |
| Rate Limit for ChatGPT model | 300 Requests per minute |
| Suggested rate limit | 5 calls / second, or 50 calls every 10 seconds |
Please note that these are the default limits and they can be increased by submitting a request from the Quotas page of Azure OpenAI Studio. The rate limit is enforced on a per-deployment basis, so each deployment of a model has its own separate rate limit. The rate limit expects that requests be evenly distributed over a one-minute period. If this average flow isn't maintained, then requests may receive a 429 response even though the limit isn't met when measured over the course of a minute.