What is LLMOps (Large Language Model Operations)?
LLMOps is a specialized area within Machine Learning Operations (MLOps) dedicated to managing large language models (LLMs) like OpenAI's GPT-4, Google's Palm, and Mistral's Mixtral in production environments.
LLMOps streamlines the deployment, ensures scalability, and mitigates risks associated with LLMs. It tackles the distinct challenges posed by LLMs, which leverage deep learning and vast datasets to comprehend, create, and anticipate text. The rise of LLMs has propelled the growth of businesses that develop and implement these advanced AI algorithms.
Key components of LLMOps include data management, prompt engineering, model fine-tuning, model deployment, model monitoring, and more. It requires collaboration across teams, from data engineering to data science to ML engineering, and stringent operational rigor to keep all these processes synchronous and working together.
After model deployment, LLM usage is part of LLMOps as it involves monitoring and updating the models to maintain their performance and address potential issues.
Key aspects of LLMOps for application developers include:
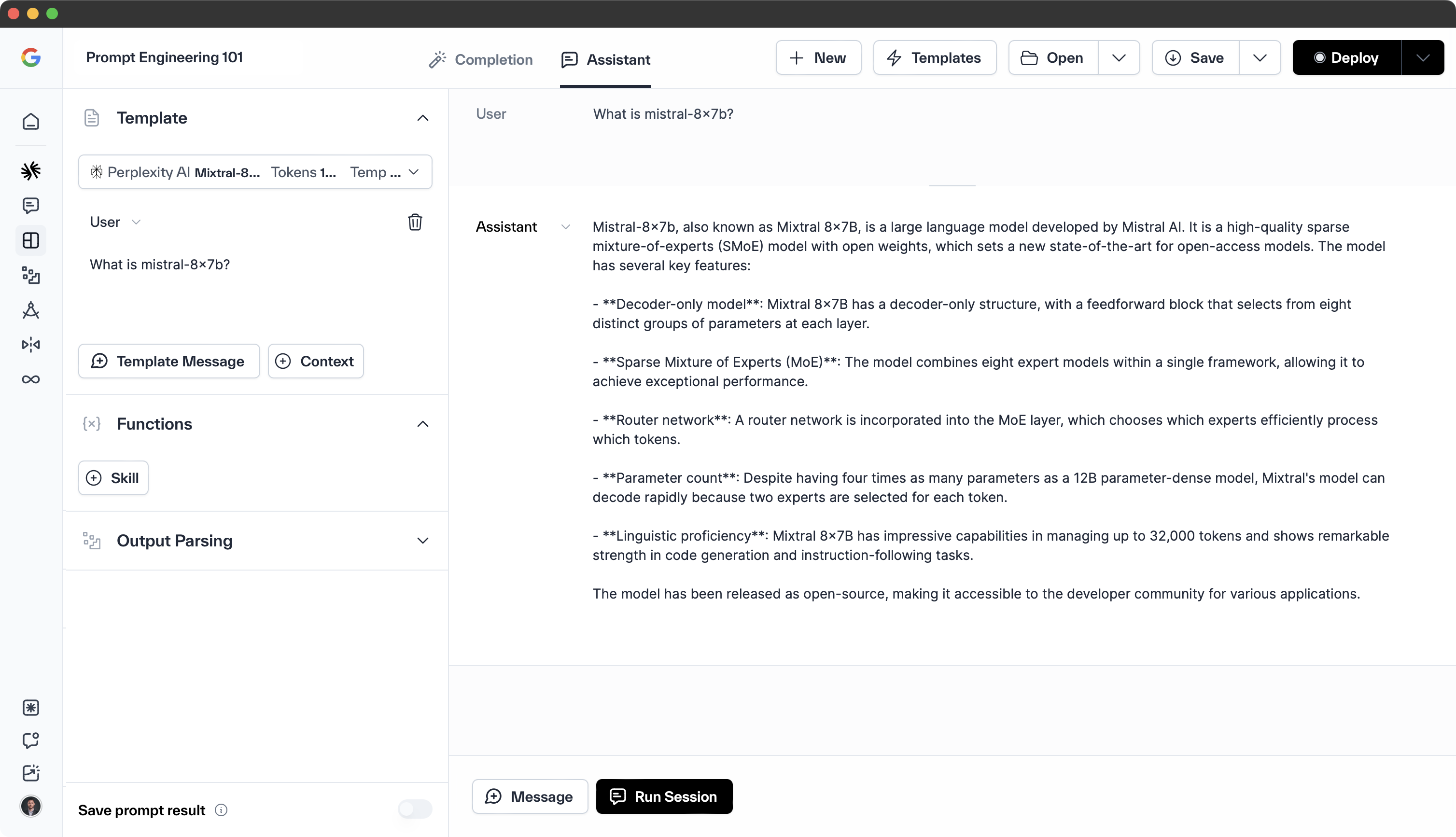
- Prompt Engineering — Crafting well-designed prompts that guide the language model's responses.
- Optimizing LLM App Performance — Integrating and optimizing generative prompts into an application, such as chatbots, programming assistants, or transformative prompts.
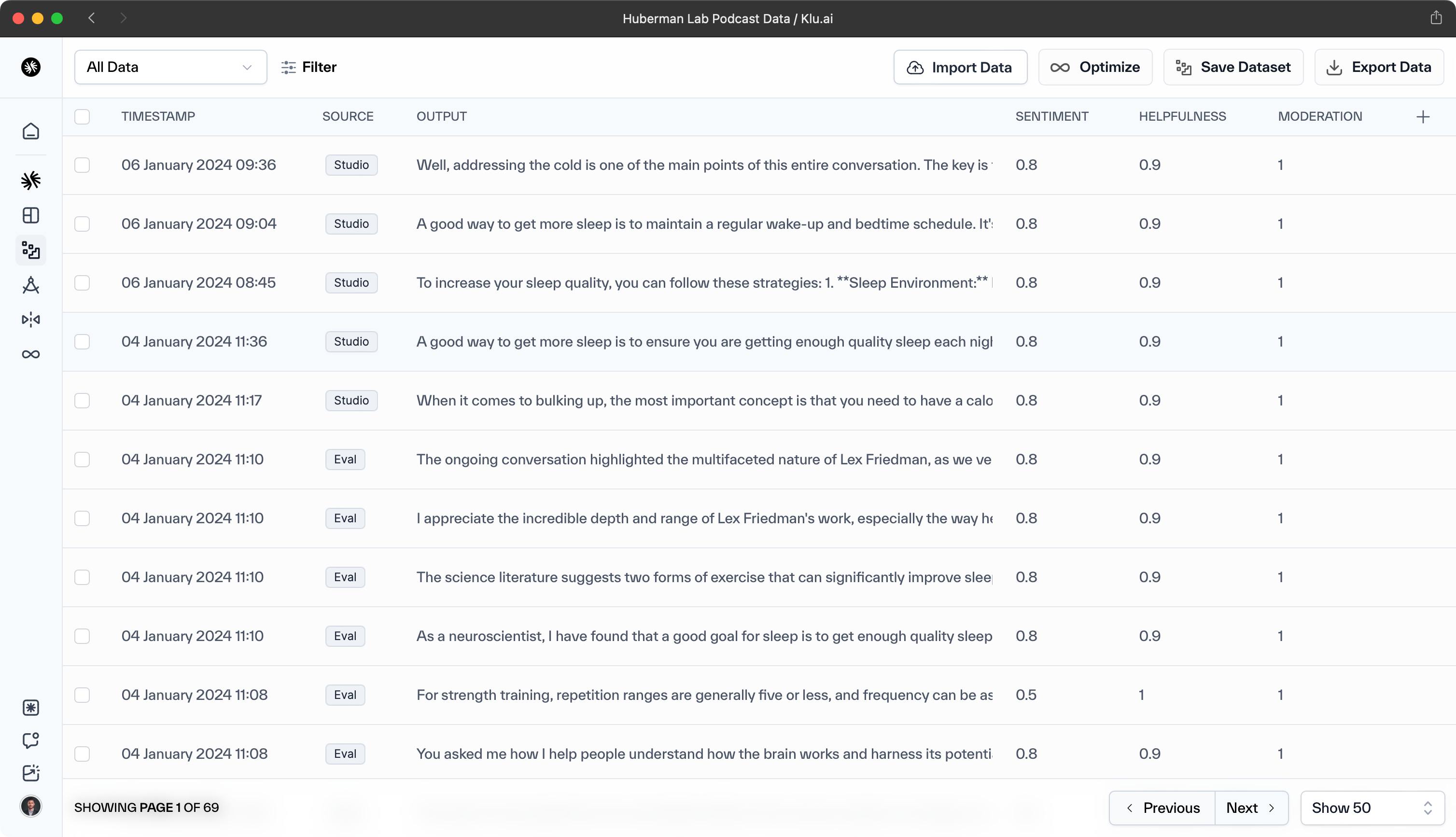
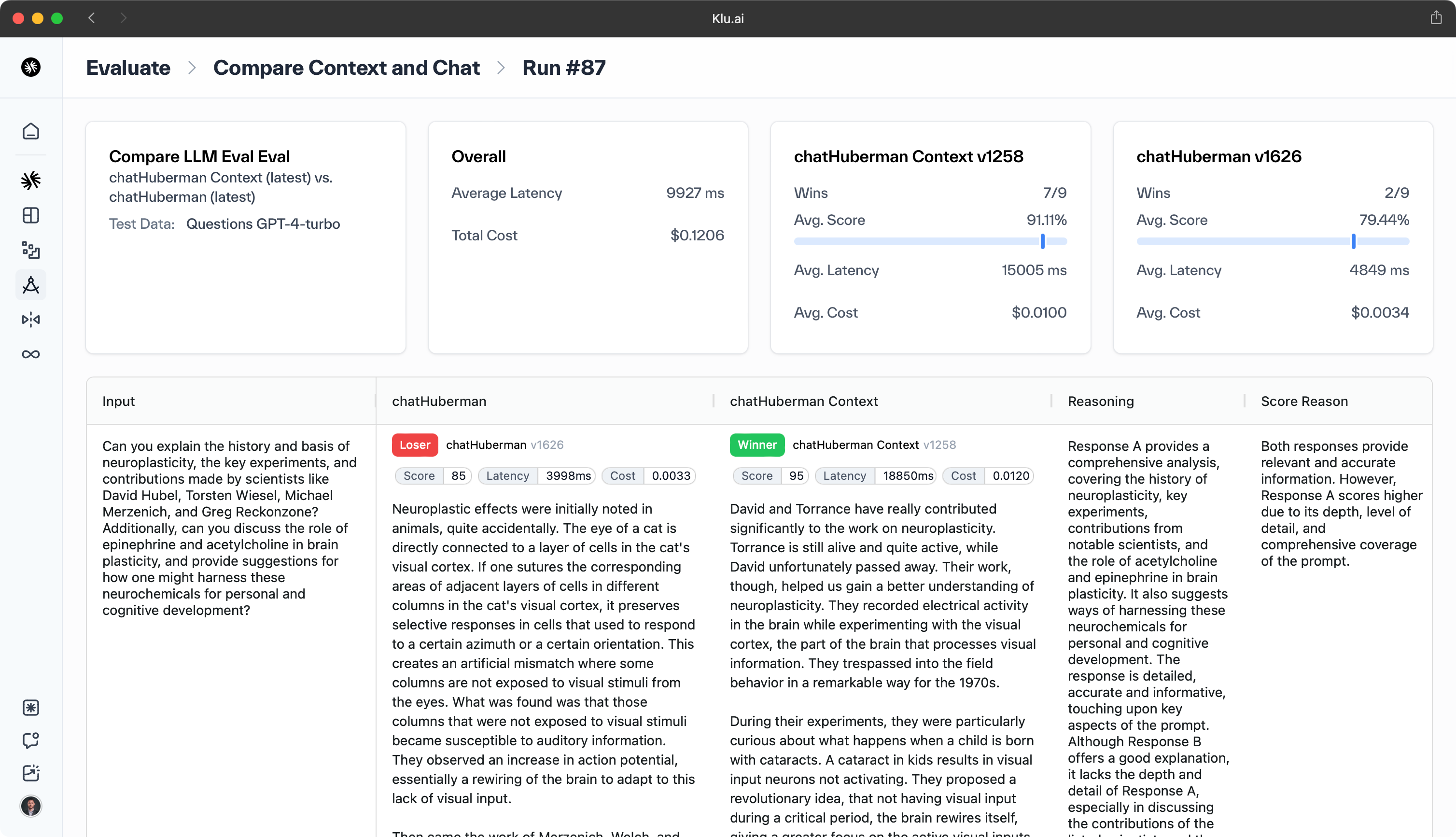
- LLM Evaluation — Regularly assessing model and app performance using metrics to ensure quality and address issues.
- LLM Observability — Gathering real-time data points after model deployment to detect potential degradation in model performance.
LLMOps for data and ML teams, which directly mirrors classic MLOps, includes:
- Monitoring — Continuously tracking model performance, groundedness, token consumptions, and infrastructure performance.
- Fine-tuning — Adjusting model weights and hyperparameters to improve performance and address specific use cases.
- Deployment — Integrating the model into the application, such as a web service or mobile app.
- Maintenance — Ensuring the model remains up-to-date and effective by updating it with fresh data and fine-tuning it as needed.
LLMOps is a crucial aspect of deploying and managing LLMs in production, as it enables efficient LLM deployment, monitoring, and maintenance to ensure optimal performance and user satisfaction.
In this guide, we dive into the practical aspects of LLMOps, exploring its key components, best practices, and real-world applications. We'll uncover how experts align outputs, enhance utility, and maintain consistent high performance of these powerful models.
Key Takeaways
-
Classic ML Workflows — Data management and preprocessing, model fine-tuning/adaptation, and monitoring/maintenance are the core components of an effective LLMOps workflow.
-
Optimization — Techniques like prompt engineering and retrieval augmented generation are best practices for adapting LLMs to tasks and bridging knowledge gaps.
-
Benchmarking — Regular model evaluation/benchmarking ensures optimal LLM performance over time. Adhering to privacy and compliance regulations is also critical.
-
Orchestration — Orchestration platforms, frameworks, libraries and observability tools facilitate efficient LLM development, deployment and maintenance at scale.
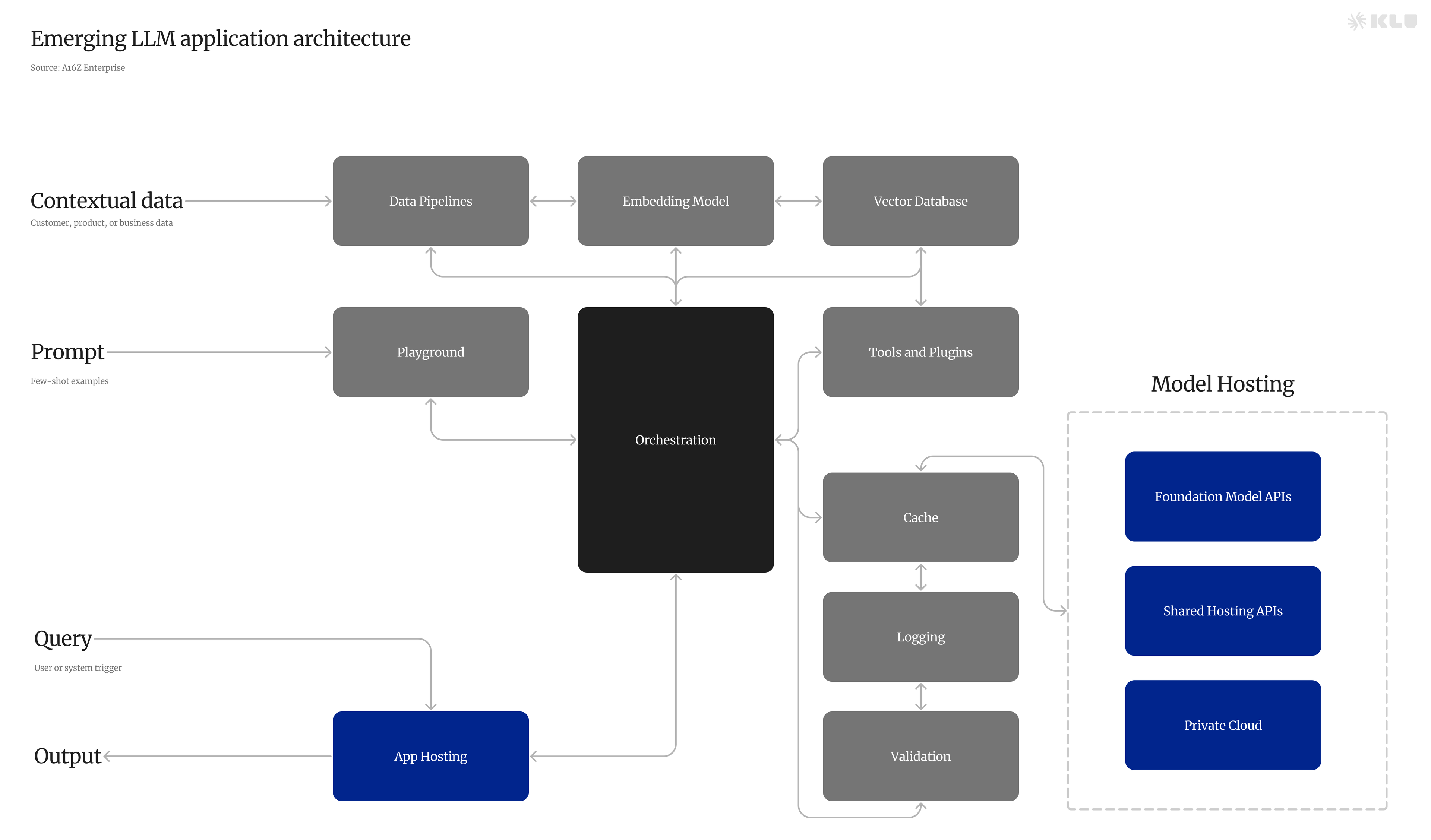
The Emergence of LLMOps
The increasing use of machine learning models, especially LLMs, has necessitated efficient management and deployment strategies. LLMs, or foundation models, use deep learning to train on large text datasets, learning grammar, semantics, and context. This ability to understand text relationships allows LLMs to predict the next word in a sentence, making them integral to modern AI systems.
However, managing their lifecycle and optimizing their performance across various tasks requires specialized techniques and tools, a role fulfilled by LLMOps.
LLMOps is a comprehensive approach that manages the lifecycle of LLMs, catering to the specific requirements of deploying and maintaining these models in production. It focuses on customizing pre-trained language models for specific tasks while ensuring data protection.
LLMOps facilitates a collaborative environment where users can:
Challenges of LLMs
Large Language Models (LLMs) are transformative in natural language processing, powering applications like chatbots, content generation, and machine translation. These models enhance human-machine interactions by providing more natural and intuitive communication capabilities.
However, LLMs face significant challenges that must be addressed to maximize their effectiveness.
-
Language Ambiguity — Ambiguity in natural language can lead to misinterpretations by LLMs, resulting in incorrect outputs. Addressing this requires LLMs to have a deep understanding of context and the ability to make accurate assumptions.
-
Hallucinations and Bias — LLMs may produce hallucinations—ungrounded outputs—or reflect biases from their training data. Mitigating these issues involves using balanced datasets and applying techniques like data augmentation and regularization.
-
Computational Costs and Latency — The computational demands of LLMs result in high costs and potential latency, which can affect user experience and the practical deployment of LLMs. Optimizing computational efficiency is therefore crucial.
-
Completion Alignment — Aligning LLM outputs with user intentions is challenging. It requires sophisticated algorithms and models, as well as a clear understanding of the task to ensure that the generated completions are relevant and accurate.
-
Task Proficiency — LLMs often require fine-tuning for specific tasks to perform optimally. This process can be complex and necessitates a thorough knowledge of both the model and the task.
-
Knowledge Gaps — LLMs may not have up-to-date knowledge or domain-specific expertise, leading to gaps in their outputs. Techniques like data augmentation, transfer learning, and retrieval-augmented generation models can help bridge these gaps.
Key Components of LLMOps
LLMOps encompasses five key components - data management and preprocessing, retrieval systems, model fine-tuning and adaptation, deployment and monitoring, prompt versioning and evaluation - to address the challenges LLMs face and to guarantee their optimal performance.
With effective implementation of these components, LLMOps can simplify the development, deployment, and maintenance of LLMs, enabling organizations to tap into the full potential of these formidable models.
Data Management and Preprocessing
Effective data management and preprocessing are crucial for LLM training, including data collection, cleaning, and organization. Ensuring data quality and integrity is essential, as it directly impacts the performance of the LLM. Techniques such as spell-checking, levenshtein distance calculation, deduplication, and outlier removal are commonly employed to refine the dataset.
Additionally, data storage and security measures, such as data encryption and access controls, must be implemented to protect sensitive information and ensure compliance with data protection regulations, especially when handling domain specific data.
Retrieval Systems
Retrieval systems play a crucial role in LLMOps, serving as the backbone for retrieval-augmented generation techniques. These systems are designed to fetch relevant information from a vast pool of data, acting as an external knowledge source for LLMs. By integrating retrieval systems, LLMs can access and incorporate additional information that may not be present in their training data, thereby enhancing their knowledge base and improving their output quality.
Vector databases play a pivotal role in LLMOps retrieval systems by enabling the efficient handling of high-dimensional data vectors that represent complex language features. These databases facilitate similarity searches at scale, balance accuracy with speed, providing LLMs with fast access to necessary information, thereby improving content quality without compromising on response time.
Model Fine-Tuning and Adaptation
The adaptation of pre-trained LLMs for particular tasks via fine-tuning and prompt engineering is indispensable for obtaining the desired outputs and enhancing task performance. Fine-tuning involves selecting the suitable model architecture, optimizing model training, and assessing model performance.
Prompt engineering, on the other hand, focuses on designing prompts that are specific to the task. By combining these approaches, LLMs can be tailored to generate accurate and relevant outputs for a wide variety of tasks.
Deployment and Monitoring
The deployment and surveillance of LLMs in production environments are vital for performance maintenance, issue resolution, and compliance assurance. Continuous integration and deployment (CI/CD) pipelines facilitate the model development process by automating testing and model deployment processes.
Regular model evaluation and benchmarking, using appropriate metrics like accuracy, F1-score, and BLEU, are crucial to evaluate model performance and detect and rectify any performance issues. Implementing model monitoring can further enhance this process.
In addition, maintaining data privacy and complying with data protection regulations, such as GDPR and CCPA, are essential aspects of responsible LLM deployment and monitoring.
Prompt Versioning and Evaluation
Prompt versioning involves creating and managing different versions of prompts for LLMs. This process allows data scientists to experiment with different prompts, test their effectiveness, and choose the best one for the task at hand.
Versioning prompts can lead to better LLM performance as it allows for continuous improvement and adaptation of prompts based on feedback and results. It also provides a historical record of prompts used, which can be beneficial for future reference and for understanding the evolution of model performance.
Evaluating the effectiveness of prompts is just as essential as creating them. Prompt evaluation involves assessing the performance of different prompts in guiding the LLM to generate the desired outputs.
This can be done through various methods, such as comparing the outputs generated by different prompts, using metrics like accuracy, F1-score, and BLEU, or through user feedback. Regular prompt evaluation ensures that the chosen prompts continue to yield the best results and allows for prompt refinement and improvement over time.
LLMOps Best Practices
Implementing best practices in LLMOps can significantly improve LLM performance and mitigate risks associated with their deployment. These practices include:
Organizations can unlock the full potential of these advanced AI models, ensuring not only their power but also their safety and responsibility, by adhering to these best practices.
Prompt Engineering
Crafting effective prompts is essential for guiding LLMs to produce desired outputs and improve task performance. A well-constructed prompt can direct the model to generate the desired output, whereas an inadequate prompt may lead to irrelevant or nonsensical results.
To create effective prompts, it is recommended to use concise language, eliminate ambiguity, and ensure adequate context is provided for the model to comprehend the task.
Retrieval-augmented Generation
Combining LLMs with external knowledge sources can enhance their capabilities and address missing knowledge issues. Retrieval-augmented generation is a technique that combines a retrieval model with a generative model to produce more precise and varied outputs.
This approach helps bridge the gaps in LLMs' knowledge and enables them to generate more accurate and relevant outputs for a wide variety of tasks.
Model Evaluation and Benchmarking
Regularly evaluating LLM performance using appropriate metrics and benchmarks is crucial for maintaining quality and addressing issues. Assessment of model performance against a set of metrics, such as accuracy, F1-score, and BLEU, can help detect and rectify any performance-related issues.
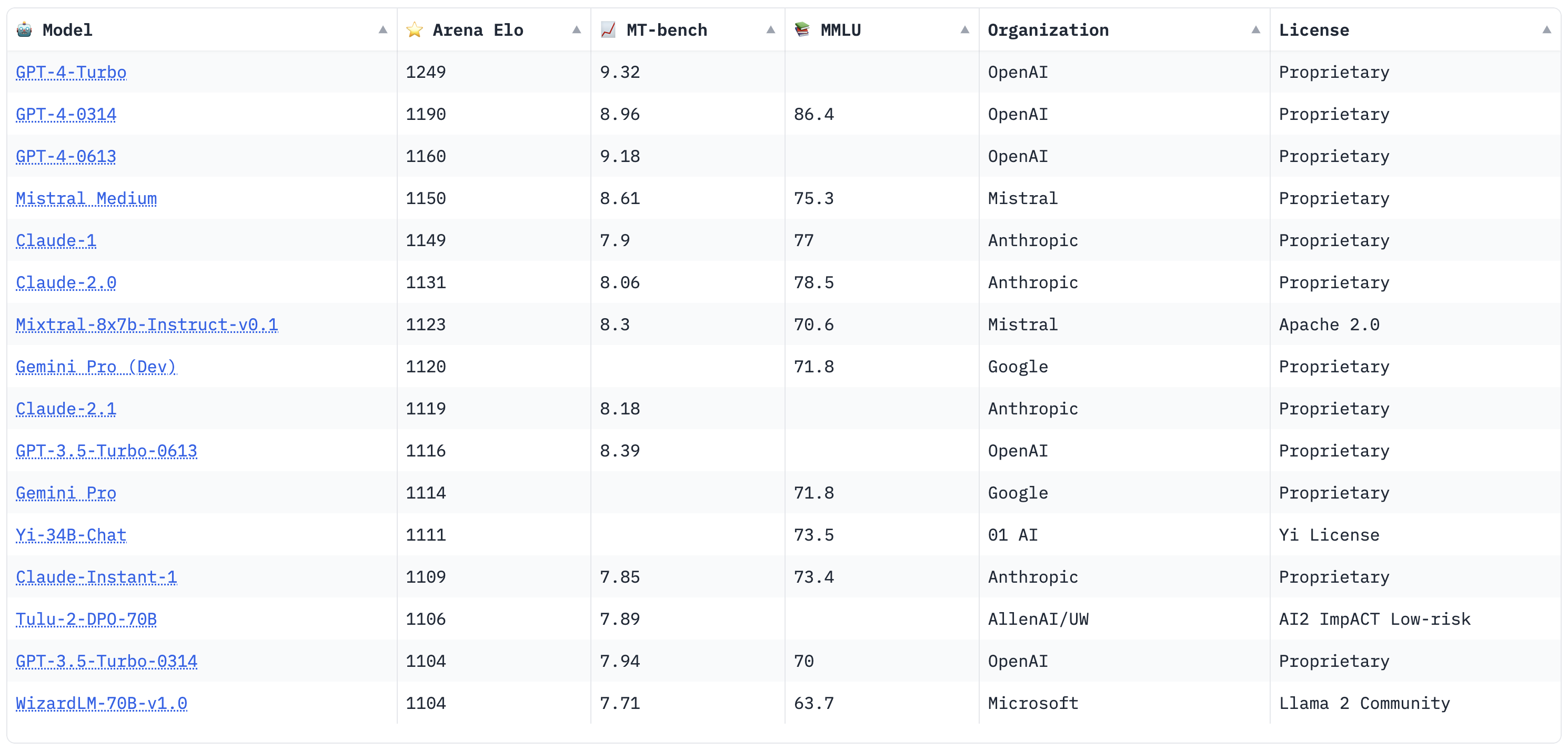
Comparing the model's performance to other models and industry benchmarks can provide valuable insights into areas to improve model performance and optimization.
Privacy and Compliance
Ensuring data privacy and regulatory compliance is critical in LLMOps. Some key steps to take include:
-
Implementing anonymization techniques to remove personally identifiable information (PII) from datasets
-
Adhering to data protection regulations, such as GDPR and CCPA
-
Safeguarding sensitive data and ensuring responsible LLM deployment
Regular audits and assessments are important to guarantee ongoing compliance and security. This ensures a high standard of data protection is maintained and a strong model management is upheld.
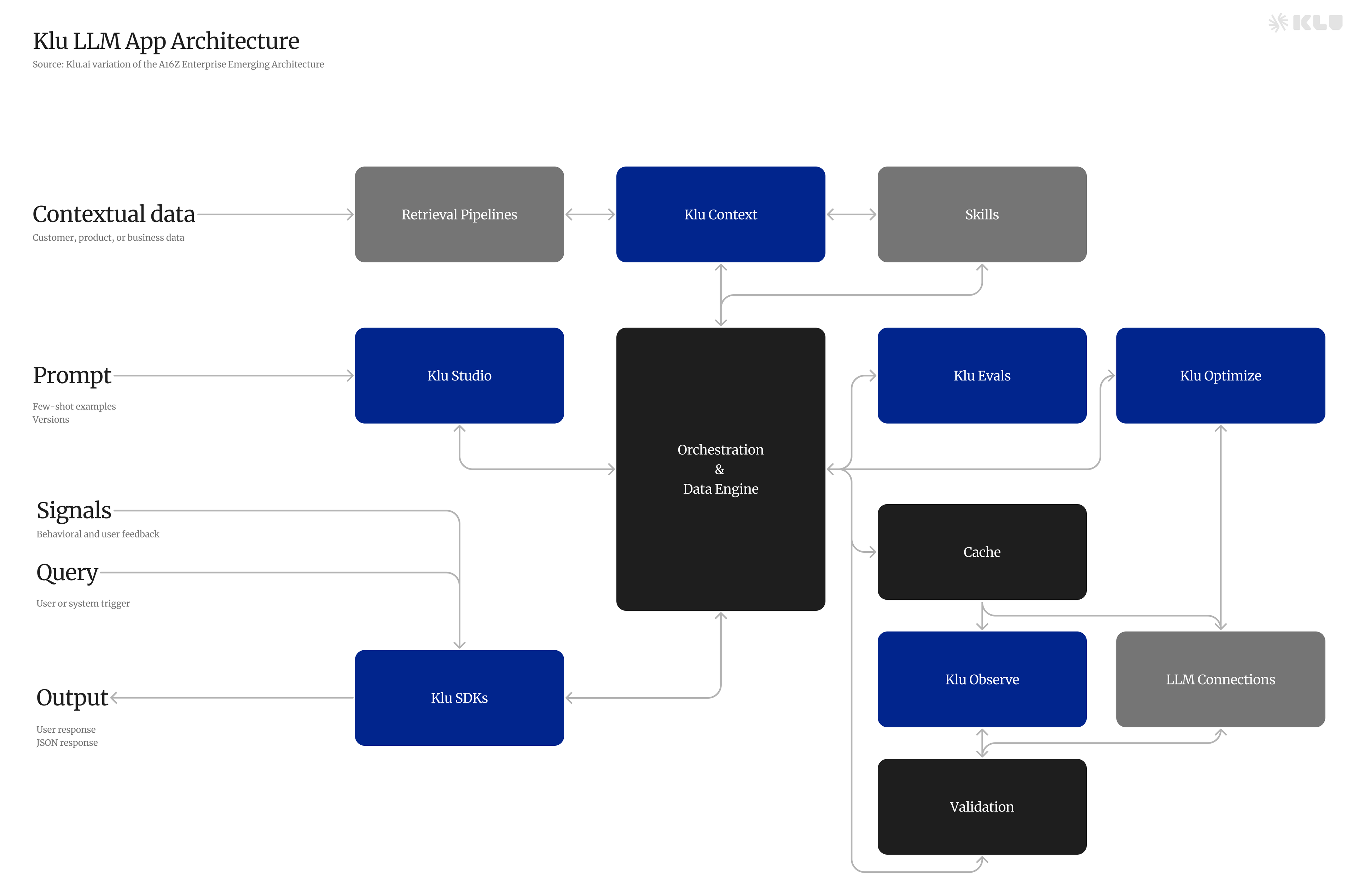
Tools and Platforms for LLMOps
A variety of orchestration platforms, frameworks, libraries, and observability tools support LLMOps by streamlining the development, deployment, and ongoing management of LLMs. These resources enable data scientists and engineers to effectively tackle the complexities of LLM deployment and maintain peak performance across diverse applications.
Model Orchestration Platforms
Orchestration platforms like Databricks and Hugging Face streamline the entire lifecycle of managing LLMs, encompassing data management, model tuning, deployment, and monitoring. These platforms facilitate a collaborative environment for teams to efficiently process data, conduct experiments, develop models and pipelines, and deploy with precision and control, ensuring a seamless integration of LLMs into production workflows.
Frameworks and Libraries
Open-source frameworks like TensorFlow and PyTorch streamline LLM development, providing essential tools for building, fine-tuning, and deploying models. These frameworks support the creation of scalable, production-grade pipelines, enabling efficient management and deployment of LLMs for diverse applications.
Observability and Maintenance Tools
Observability and maintenance tools like Klu are essential for the real-time monitoring of LLMs, ensuring their health and performance. These tools enable teams to quickly identify and address issues, which is crucial for maintaining LLM quality and performance across various applications.
LLMOps in Action
LLMs and LLMOps are being applied across various industries and use cases, demonstrating the versatility and potential of these powerful AI models. From healthcare to AI assistants, chatbots to programming, education to talk-to-your-data applications, sales to SEO, LLMs are redefining the way we interact with and leverage AI technologies.
The following subsections dive into some real-world applications of LLMs and LLMOps, demonstrating their transformative impact across diverse sectors.
AI Assistants
LLMOps significantly enhances AI assistants and chatbots, enabling more natural, conversational interactions for a seamless user experience. It also ensures chatbots deliver accurate, personalized support, boosting customer satisfaction across various sectors.
Chatbots
LLMOps has revolutionized chatbot development and management, enhancing their performance and utility. Through streamlined model training, packaging, validation, and deployment processes, chatbots can now engage users with more accurate and personalized interactions. This advancement enables businesses to improve customer service, optimize operations, and drive growth, thereby elevating the customer experience.
Data Q&A
Talk-to-your-data applications, empowered by LLMs and LLMOps, are transforming the way industries interact with big data. By enabling natural language conversations with data, these applications facilitate quick identification of patterns, trends, and insights. The result is a streamlined decision-making process that enhances productivity, efficiency, and customer satisfaction across various sectors.
LLMOps Platforms
LLMOps utilizes a variety of tools to manage the lifecycle of large language models. Here are some examples of LLMOps tools:
-
Klu.ai — Complete app lifecycle LLMOps for abmitious startups and enterprises, focused on continuous feedback collection for prompt and model refinement, and LLM-powered data labeling.
-
Weights & Biases (W&B) — This platform offers a suite of LLMOps tools within its MLOps platform. It includes features for visualizing and inspecting LLM execution flow, tracking inputs and outputs, viewing intermediate results, and securely managing prompts and LLM chain configurations.
-
Amazon SageMaker — A fully managed service that provides data scientists and developers with the ability to quickly build, train, and deploy machine-learning (ML) models, which can be used in the context of LLMOps.
The automation of programming tasks using LLMs has the potential to revolutionize the software development process. With the help of LLMOps, LLMs can be tailored to generate code snippets, automate bug fixes, and even create entire applications based on user input.
This not only streamlines the development process, but also allows developers to focus on more complex and high-value tasks, ultimately improving the quality and efficiency of software development.
Conclusion
The integration of LLMs and LLMOps is reshaping various sectors by enhancing AI's role in our daily activities.
LLMOps addresses the complexities of LLMs, optimizing their performance for diverse applications. This synergy propels organizational growth, operational efficiency, and improved outcomes.
As LLMs and LLMOps evolve, they promise to further embed AI into our lives, driving innovation and improving how we interact, work, and solve problems. For a deeper understanding of the future implications, visit our LLMOps future insights.