Open Source LLMs Leaderboard
Selecting the best open source LLM depends on the specific use case and performance requirements — as trite as that sounds. Open source models like Gemma 2, Nemotron-4, and Llama 3.1 have surpassed proprietary counterparts such as GPT-3.5 Turbo and Google Gemini in versatility and are leading choices for a broad range of applications.
For another perspective on the landscape, see Benched.ai's guide to the best open source LLMs.
The table below presents a ranking of open source LLMs, detailing their competitive performance through the Arena Elo rating, translation quality via MT-bench scores, and comprehension abilities with MMLU scores. Additionally, each model's licensing terms are provided to inform users of their rights and limitations.
| Model | Arena Score | MT-bench | MMLU | Organization |
|---|
| Gemma 2 27B Instruct | 1216 | – | 76.2 | Google |
| Nemotron-4 340B Instruct | 1208 | – | – | Nvidia |
| Llama 3 70b Instruct | 1207 | 8.2 | 79.2 | Meta |
| Command R+ | 1190 | – | – | Cohere |
| Qwen2 72B Instruct | 1188 | 9.12 | 84.2 | Alibaba |
| Gemma 2 9B Instruct | 1186 | – | 72.3 | Google |
| DeepSeek-Coder V2 Instruct | 1179 | – | – | DeepSeek AI |
| Yi 1.5 34B Chat | 1158 | – | 76.8 | 01 AI |
| Llama 3 8b Instruct | 1152 | – | 68.4 | Meta |
| Command R | 1148 | – | – | Cohere |
| Mixtral 8x22b Instruct-v0.1 | 1146 | – | 77.8 | Mistral |
| Zephyr ORPO 141b-A35b-v0.1 | 1127 | – | – | HuggingFace |
| Qwen1.5 32B Chat | 1125 | 8.3 | 73.4 | Alibaba |
| Phi 3 Medium 4k Instruct | 1123 | – | 78 | Microsoft |
| Starling LM 7B beta | 1119 | 8.12 | – | Nexusflow |
| Mixtral 8x7b Instruct-v0.1 | 1114 | 8.3 | 70.6 | Mistral |
| Yi 34B Chat | 1111 | – | 73.5 | 01 AI |
| Qwen 1.5 14B Chat | 1109 | 7.91 | 67.6 | Alibaba |
| WizardLM 70B v1.0 | 1106 | 7.71 | 63.7 | Microsoft |
| Zephyr 7b | 1049 | 7.34 | 73.5 | Apache 2.0 |
| Llama 2 70b | 1077 | 6.86 | 63.4 | Meta |
| Mistral 7b v0.2 | 1072 | 7.7 | 60.1 | Mistral |
Among smaller models, the Zephyr 7b model excels in general assistant tasks, although it requires additional prompt engineering to match the performance of proprietary models. Additionally, AI2's Tulu 2 used the same RLHF techniques applied to Zephyr, demonstrating the effectiveness of this technique across different models.
Beyond the Elo leaderboard, there are several well-regarded variant models tailored for storytelling and roleplaying, including Mythomax, Nous Hermes, and Noromaid, which are very popular among end users.
Comprehensive Guide to Testing, Running, and Selecting
Open source Large Language Models (LLMs) are powerful and now nearly anyone can use them... on their phone, laptop, or private cloud. These LLMs provide advanced AI capabilities for a variety of applications, from chatbots to code generation, without the restrictions from providers.
The open source LLM ecosystem has undergone a dramatic transformation in just six months since our last review. Once dominated by Llama 2 and Vicuna, the landscape is now enriched by innovative models emerging from community efforts and new foundation model groups.
The evolving landscape of leading open source LLMs underscores the critical importance of selecting the right model for production systems. Throughout 2023, the field witnessed the emergence of several noteworthy models, including MPT-7b, Falcon, and StableLM. In 2024, Meta's Llama 3 and Cohere's Command R and Command R+ models marked a significant resurgence in the open source LLM space. These developments highlight the rapid pace of innovation and the expanding options available to developers and organizations seeking to leverage state-of-the-art language models in their applications.
Several labs, including MPT, Falcon, and Stable, ceased model iteration due to various factors. A lack of widespread adoption hindered progress for some models. Others faced shifting business priorities that redirected resources away from model development. Falcon, in particular, encountered challenges due to its exceptionally high GPU hardware requirements for inference, which limited its practical use.
The introduction of new models like Mixtral, Tuli, and Yi has further enriched the open source LLM ecosystem. With the continuous influx of new LLM models, navigating and selecting the most suitable one for your needs can be challenging.
The growth of open datasets, model architectures, and evaluation frameworks alongside proprietary LLMs democratizes AI advancements. We provide a concise comparison of model architecture, training data, performance metrics, customization options, and community engagement.
Whether for chatbots, story generation, or AI product features, these open source LLMs can elevate your projects.
We have done the heavy lifting for you and will guide you through the most promising playgrounds, tools, and models as of July 2024.
What you'll learn in this guide
- Best ways to test models online
- Best ways to run models locally
- Best ways to run in production
- Best open source models
- Best community variants of open source models
Table of Contents
Models
Testing, Running, and Optimizing
How to test Open Source LLMs online
Before you start downloading models and setting up software to run the models, you may want to first start testing with an online playground. The best places to test open source LLMs online include:
PPLX Labs
Perplexity Labs offers a chat interface and API to access open source LLMs, including their own custom models, Mistral 7b, CodeLlama 34b, and Llama 2 13b and 70b. In addition to the playground, PPLX offers APIs, which we'll review later in the guide.
Vercel AI Playground
Vercel AI Playground offers model inference from Bloom, Llama 2, Flan T5, GPT Neo-X 20B, and OpenAssistant (Pythia 12B).
How to run Open Source LLMs locally
Running open source LLMs locally is a crucial step in understanding their capabilities and limitations. This section provides a comprehensive guide on how to run some of the most popular open source LLMs on your local machine. We will cover models such as Ollama, LM Studio, and others, providing step-by-step instructions and tips for a smooth and successful setup.
Ollama
Ollama is a user-friendly tool designed to run large language models (LLMs) locally on a computer. It supports a variety of AI models including Llama-2, uncensored Llama, CodeLlama, Falcon, Mistral, Vicuna model, WizardCoder, and Wizard uncensored. It is currently compatible with MacOS and Linux, with Windows support expected to be available soon.
- Installation — Download Ollama from the official website and install it using the command
curl https://ollama.ai/install.sh | sh.
- Running Models — Use the
run command in the terminal to run a model. For example, ollama run codellama.
- Python Integration — You can use Ollama with Python. For instance, with the Langchain library, you can connect to a model on Ollama as follows:
from langchain.lm import Ollama
ollama = Ollama(base_url="http://localhost:11434", model="llama2")
print(ollama.generate("Why is the sky blue?"))
- Additional Features — Ollama supports importing GGUF and GGML file formats in the Modelfile, allowing you to create, iterate, and share your models.
- Available Models — Check the Ollama Model Library page for a list of available models. Ensure you have adequate RAM for the model you are running.
Ollama simplifies the process of running LLMs locally, making it a valuable tool for developers and researchers alike.
LM Studio
LM Studio is a desktop application that allows you to discover, download, and run local and open source Large Language Models (LLMs) on your laptop. It provides an easy-to-use interface for experimenting with LLMs without the need for command-line setup.
To get started with LM Studio, follow these steps:
-
Visit the LM Studio website and download the application for your operating system (macOS in your case).
-
Install LM Studio on your laptop by following the installation instructions provided.
-
Launch LM Studio, and you'll be able to discover and download various open source LLMs.
-
Once you've downloaded an LLM, you can use LM Studio's interface to run the model locally on your laptop.
We're big fans of LM Studio at Klu.
Jan
Jan is an open source platform that allows you to run AI models locally on your computer, ensuring data privacy and security. It operates offline and is customizable to meet your specific needs. Jan is just getting started, but we at Klu.ai view it as a potential replacement for LM Studio, which has more functionality, but worse user experience.
Here are the steps to get started with Jan:
- Download and Install — Jan is free and runs on your own hardware, eliminating the need for monthly subscriptions or usage-based APIs. Download it from the official website and follow the installation instructions.
- Extend Functionality — Jan supports an app and plugin framework. You can add more features and capabilities to suit your requirements.
- Use Your Own Files — Jan uses open, standard, and non-proprietary files stored locally on your device. This gives you full control over your AI and allows for easy migration to another app if needed.
- Run Models Locally — With Jan, you can run large language models (LLMs) directly on your desktop. This makes it a cost-effective solution for local LLM operations.
One of the key advantages of Jan is that it eliminates the need for monthly subscriptions or usage-based APIs, as it runs 100% free on your own hardware. This makes it a cost-effective solution for running large language models (LLMs) locally on your desktop.
Llama.cpp
For more customization and performance, you can run models locally using tools like llama.cpp. This gives you full control to load pretrained models from Hugging Face and inference them on your CPU or GPU. Just be sure to download a model size that fits within your laptop's RAM, like a 7B parameter model. The llama.cpp library wraps the models in an easy API for Python, Go, Node.js and more.
Running your own LLM gives you privacy, speed, and flexibility. You can use the models for personalized projects without relying on APIs. So with just a bit of setup, you can unlock the latest AI to generate content, classify text, answer questions and more right on your local machine.
Replicate released a script that greatly simplifies the process of getting started. To run models locally with llama.cpp, follow this one step:
- Install the llama-cpp package — To install the llama-cpp package on your M1/M2 Mac, use the following one-liner command:
curl -L "https://replicate.fyi/install-llama-cpp" | bash. For Intel Mac or Linux machine, use: curl -L "https://replicate.fyi/install-llama-cpp-cpu" | bash. For Windows on WSL, use: curl -L "https://replicate.fyi/windows-install-llama-cpp" | bash.
Here's what the script runs:
#!/bin/bash
# Clone llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# Build it. `LLAMA_METAL=1` allows the computation to be executed on the GPU
LLAMA_METAL=1 make
# Download model
export MODEL=llama-2-13b-chat.ggmlv3.q4_0.bin
if [ ! -f models/${MODEL} ]; then
curl -L "https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/resolve/main/${MODEL}" -o models/${MODEL}
fi
# Set prompt
PROMPT="Hello! How are you?"
# Run in interactive mode
./main -m ./models/llama-2-13b-chat.ggmlv3.q4_0.bin \
--color \
--ctx_size 2048 \
-n -1 \
-ins -b 256 \
--top_k 10000 \
--temp 0.2 \
--repeat_penalty 1.1 \
-t 8
Remember to replace <PATH TO WEIGHTS>.gguf with the actual path to your model weights file and <tokenizer> with the tokenizer you want to use. If you want to use the default tokenizer for huggyllama/llama-7b, you can omit the tokenizer argument.
We're big fans of llama.cpp and the revolution Georgi Gerganov started.
How to run Open Source LLMs in production
Running LLMs in a production environment requires careful consideration of factors such as scalability, reliability, and cost-effectiveness. In this section, we will explore various methods and platforms that can be used to run open source LLMs in a production setting, providing you with practical insights to make an informed decision.
PPLX API
PPLX API is a fast and efficient API for open source LLMs developed by Perplexity Labs. It provides ease of use, blazing fast inference, and a battle-tested infrastructure. It supports models such as Mistral 7B, Llama2 13B, Code Llama 34B, Llama2 70B, and replit-code-v1.5-3b.
Here's how you can get started with PPLX API:
-
Generate an API key — You can generate an API key through the Perplexity Account Settings Page. This API key is a long-lived access token that can be used until it is manually refreshed or deleted.
-
Send the API key — Send the API key as a bearer token in the Authorization header with each PPLX API request.
Here's an example of how to submit a chat completion request using CURL:
curl -X POST \
--url https://api.perplexity.ai/chat/completions \
--header 'accept: application/json' \
--header 'content-type: application/json' \
--header "Authorization: Bearer ${PERPLEXITY_API_KEY}" \
--data '{
"model": "mistral-7b-instruct",
"stream": false,
"max_tokens": 1024,
"frequency_penalty": 1,
"temperature": 0.0,
"messages": [
{
"role": "system",
"content": "Be precise and concise in your responses."
},
{
"role": "user",
"content": "How many stars are there in our galaxy?"
}
]
}'
And here's an example of how to do the same using Python:
import openai
YOUR_API_KEY = "INSERT API KEY HERE"
messages = [
{
"role": "system",
"content": (
"You are an artificial intelligence assistant and you need to "
"engage in a helpful, detailed, polite conversation with a user."
),
},
{
"role": "user",
"content": (
"Count to 100, with a comma between each number and no newlines. "
"E.g., 1, 2, 3, ..."
),
},
]
# demo chat completion without streaming
response = openai.ChatCompletion.create(
model="mistral-7b-instruct",
messages=messages,
api_base="https://api.perplexity.ai",
api_key=YOUR_API_KEY,
)
print(response)
# demo chat completion with streaming
response_stream = openai.ChatCompletion.create(
model="mistral-7b-instruct",
messages=messages,
api_base="https://api.perplexity.ai",
api_key=YOUR_API_KEY,
stream=True,
)
for response in response_stream:
print(response)
For more information, visit the PPLX API documentation and Quickstart Guide.
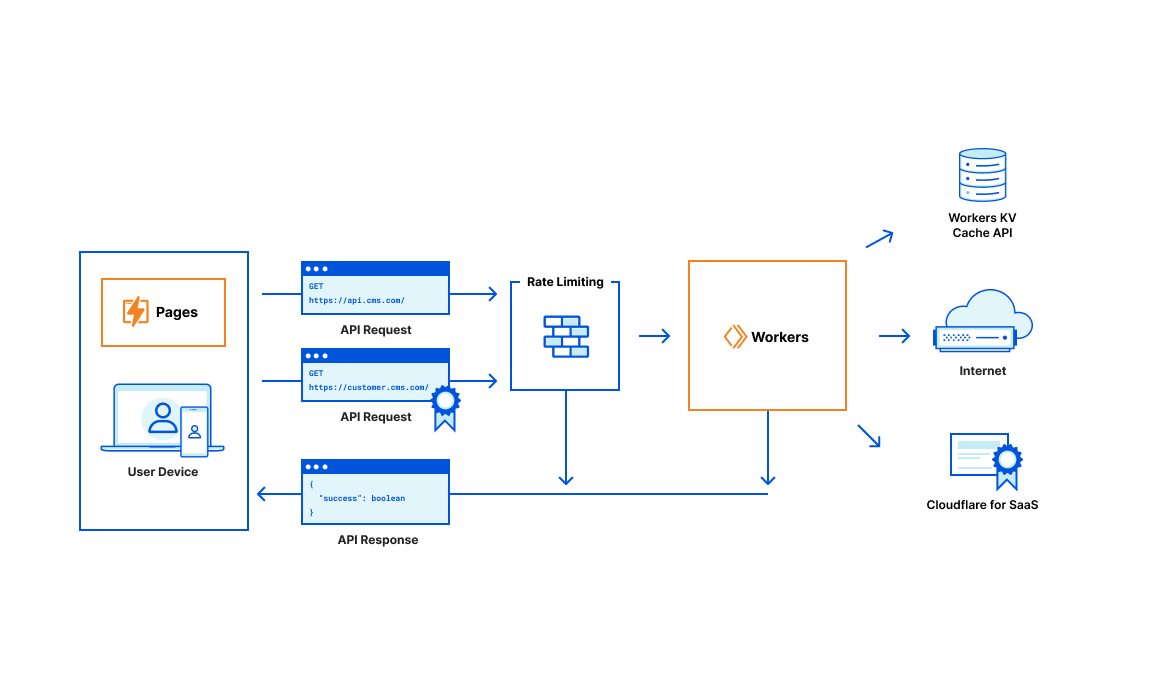
Cloudflare
To run open source LLMs in production using Cloudflare, follow these steps:
-
Choose an open source LLM: Select a suitable open source LLM for your application, such as LLaMA or Falcon.
-
Use Cloudflare Workers AI: Cloudflare Workers AI allows you to run machine learning models on Cloudflare's global network. It comes with a curated set of popular open source models that cover a wide range of inference tasks. You can browse all available models in your Cloudflare dashboard.
-
Set up a Cloudflare Workers project: Create a new project named workers-ai by running npm create cloudflare@latest. Follow the setup instructions to configure your project.
-
Develop your application: Write your application code using Cloudflare Workers or Pages, and integrate the chosen LLM using the Cloudflare Workers AI SDK. For example, you can use the Llama-2 model by running the following code snippet:
import { Ai } from "@cloudflare/ai";
const ai = new Ai(env.AI);
const output = await ai.run("@cf/meta/llama-2-7b-chat-int8", {
prompt: "Tell me about Workers AI",
});
- Deploy your application: Deploy your application using Cloudflare Workers or Pages, ensuring that it runs on Cloudflare's global network of GPUs for low-latency inference tasks.
Remember to continuously monitor your application's performance, and optimize it based on user feedback, latency, and cost considerations.
Replicate
Running open source Large Language Models (LLMs) in production using Replicate involves several steps. Replicate is a platform that allows you to run machine learning models with a few lines of code, without needing to understand the intricacies of machine learning. It provides a Python library and automatically generates a scalable API server for your model, which can be deployed on a large cluster of GPUs.
Here's a concise guide on how to run open source LLMs in production using Replicate:
-
Create a Replicate account — You'll need to create an account on Replicate to get started. This will provide you with an API token that you'll use to authenticate your requests.
-
Install the Replicate Python client — You can install the Replicate Python client using pip. The command is pip install replicate.
-
Set up your environment — After installing the Replicate Python client, you'll need to set up your environment. This involves importing necessary libraries and setting your Replicate API token as an environment variable.
-
Define your model with Cog — Replicate uses Cog to define models. You can use open source models off the shelf, or you can deploy your own custom, private models at scale.
-
Deploy your model — Once your model is defined, you can deploy it using Replicate. If your model gets a lot of traffic, Replicate scales up automatically to handle the demand. If you don't get any traffic, it scales down to zero and doesn't charge you.
-
Use the Replicate API — After your model is deployed, you can use the Replicate API to interact with it. This involves sending requests to the API and processing the responses.
Remember, running LLMs in production requires careful consideration of factors such as cost, scalability, and performance. It's also important to note that while open source LLMs can be a cost-effective alternative to proprietary models, they may not always match the performance of models like ChatGPT. Therefore, it's crucial to thoroughly evaluate your specific needs and the capabilities of the LLM you plan to use.
How to customize (fine-tuning) Open Source LLMs in production
Fine-tuning is a crucial step in deploying open source Large Language Models (LLMs) in production. It allows you to customize the model to better suit your specific needs and use-cases. This section provides a comprehensive guide on how to fine-tune open source LLMs using various platforms and tools.
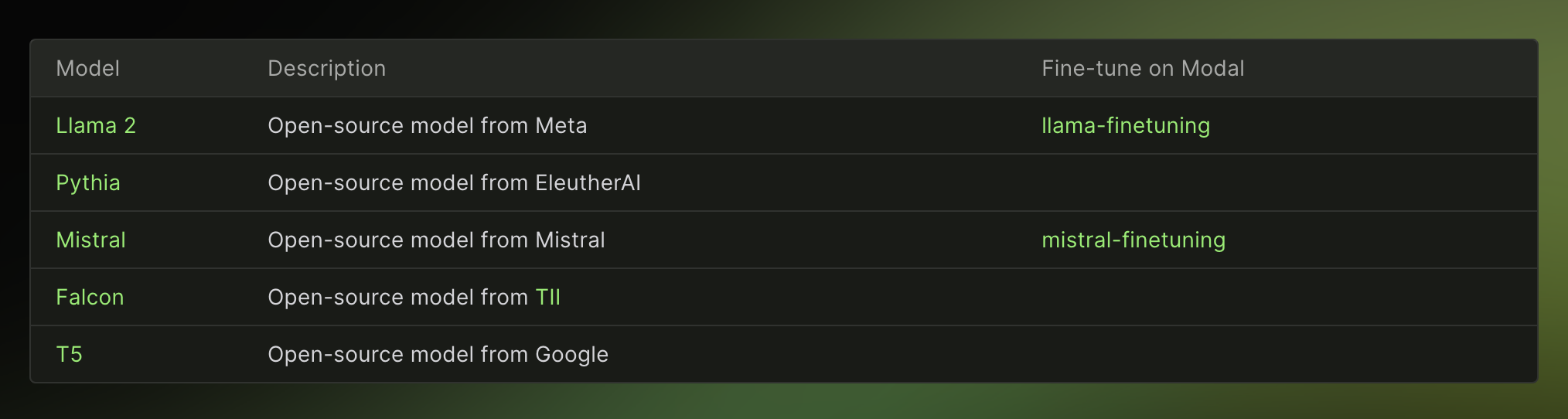
Modal
Fine-tuning open source Large Language Models (LLMs) in production using Modal involves several steps. Here's a concise guide to help you through the process:
-
Create a Modal Account — The first step is to create a Modal account. This is the only local dependency you need.
-
Install Modal — Install Modal in your current Python virtual environment using the command pip install modal.
-
Set up a Modal Token — Set up a Modal token in your environment using the command modal token new.
-
Hugging Face Token — You need to have a secret named huggingface in your workspace. Populate HUGGING_FACE_HUB_TOKEN and HUGGINGFACE_TOKEN with the same key from HuggingFace (settings under API tokens).
-
Model Access — For several models, you need to go to the Hugging Face page and agree to the terms and conditions to get access (which is granted instantly).
-
Launch a Training Job — To launch a training job, use the command modal run train.py --dataset sql_dataset.py --base chat7 --run-id chat7-sql. This example fine-tunes Llama 7B Chat to produce SQL queries (10k examples trained for 10 epochs in about 30 minutes).
Modal allows for multi-GPU training in repeatable environments, making it easy to fine-tune models on up to 8 GPUs with the sharding technique of your choice. You can define environments in code so your fine-tuning runs work are repeatable for your entire team. You can spawn fine-tuning runs on-demand from your app or your terminal, and pay only for GPUs when you use them. Modal also allows you to easily define and run hyperparameter sweeps.
Remember, fine-tuning is often an iterative process. After achieving satisfactory performance on the validation and test sets, it's crucial to implement robust security measures to protect your LLM and applications from potential threats and attacks.
Finally, it's important to note that fine-tuning is a technique used to improve the performance of machine learning models. It offers several advantages over prompt design, including improved quality of results, the ability to train on a larger number of examples than can fit in a prompt, token savings due to shorter prompts, and reduced latency in requests.
Together.ai
Fine-tuning open source Large Language Models (LLMs) in production using Together.ai involves several steps. Here's a concise guide:
Forming the Dataset
First, you need to create your dataset. This can be done using Python. The dataset should be in a format that pairs questions and answers. Here's a Python code snippet to help you do this:
import pandas as pd
df = pd.read_csv('questions_answers.csv')
df['text'] = df.apply(lambda row: '<human>:' + row['Question'] + ' <bot>:' + row['Answer'], axis=1)
df[['text']].to_json('train.jsonl', orient='records', lines=True)
This code reads a CSV file containing questions and answers, formats the data into a specific format, and then saves it as a JSONL file.
Uploading the Dataset
Once your dataset is ready, you need to upload it to Together.ai using the following command:
together files upload train.jsonl
This command uploads the JSONL file you created in the previous step to Together.ai.
Running Fine-Tuning
After uploading your dataset, you can start the fine-tuning process with this command:
together finetune create -t file-740136e9-d376-4d0c-9d5e-c9f96bfbed8f -m togethercomputer/llama-2-7b-chat
This command initiates the fine-tuning process on Together.ai.
Checking the Result
You can check the result of your fine-tuning process using this command:
together finetune list-events ft-c96e9e44-c6b2-41f6-a659-3371ae7a1231
This command lists the events of the fine-tuning process.
Using Fine-Tuned Model in Production
After successfully fine-tuning your model, you can use it in your application. Here's a Python code snippet to help you do this:
import os
from typing import Any, Dict
import together
from langchain.llms.base import LLM
from langchain.utils import get_from_dict_or_env
from pydantic import Extra, root_validator
class TogetherLLM(LLM):
"""Together large language models."""
model: str = "togethercomputer/llama-2-70b-chat" # model endpoint to use
together_api_key: str = os.environ["TOGETHER_API_KEY"] # Together API key
This code defines a class for the fine-tuned model and sets the model endpoint and API key.
Remember, fine-tuning is an optional step that can improve the performance of LLMs for specific tasks. It's also worth noting that fine-tuning can be done using various techniques, such as Low-Rank Adaptation (LoRA).
SkyPilot
Fine-tuning and deploying open source Large Language Models (LLMs) in production using SkyPilot involves several steps. Here's a concise guide to help you through the process:
Fine-Tuning LLMs
- Set up your environment — Clone the project repository and install SkyPilot and DVC using pip. Configure your cloud provider credentials. You can refer to the SkyPilot documentation for more details.
pip install skypilot[all] dvc[all]
-
Fine-tune your model — Use DVC for reproducible pipelines and efficient dataset versioning, SkyPilot for launching cloud compute resources on demand, and HuggingFace Transformers for efficient transformer model training.
-
Use SkyPilot for cost-effective fine-tuning — SkyPilot can be used to fine-tune your own LLMs on your private data in your own cloud account, cost-effectively. It provides high GPU availability and lowers costs by supporting fine-tuning on spot instances with automatic recovery.
sky spot launch -n vicuna train.yaml \
--env ARTIFACT_BUCKET_NAME=<your-bucket-name> \
--env WANDB_API_KEY=<your-wandb-api-key>
Deploying LLMs
- Serve your model — After the training is done, you can serve your model in your own cloud environment with a single command.
sky launch -c serve serve.yaml --env MODEL_CKPT=<your-model-checkpoint>/chatbot/7b
-
Use SkyPilot for deployment — SkyPilot abstracts away cloud infrastructure by launching jobs and clusters on any cloud, automatically queuing and running them, and maximizing GPU availability by provisioning (with automatic failover) in all zones/regions/clouds you are able to use.
-
Launch vLLM in your cloud with one click — SkyPilot provides a simple yaml serve.yaml to launch vLLM. With just one SkyPilot command, you can launch vLLM for LLaMA-65B on any cloud, in your own cloud account.
sky launch -c vllm serve.yaml --gpus A100 --env MODEL_NAME=decapoda-research/llama-13b-hf
-
Handle GPU shortage — LLMs typically require high-end GPUs such as the coveted A100-40GB or A100-80GB GPUs. SkyPilot comes with an auto-failover provisioner, which automatically retries provisioning a cluster in different regions (or clouds) if the requested resources cannot be provisioned.
-
Use Managed Spot Jobs for cost savings — SkyPilot supports managed spot jobs that can automatically recover from preemptions. This feature saves significant cost (e.g., up to 70% for GPU VMs) by making preemptible spot instances practical for long-running jobs.
Remember to replace <your-bucket-name> and <your-wandb-api-key> with your actual bucket name and WandB API key, and <your-model-checkpoint> with the path to your model checkpoint.
Which Open Source LLMs are the best?
Let's dig in and compare some of the leading open source large language models (LLMs) available today.
Ranging from Meta's formidable 70-billion parameter Llama 2 to Microsoft's nimble 2.7-billion parameter Phi 2, these models represent the cutting edge in generative AI capabilities.
Our analysis focuses on the architecture, training data, benchmarks, licenses, community engagement, and specialized capabilities of open source LLMs.
This streamlined overview aims to guide users in choosing the most suitable LLM for various applications, from production chatbots to custom assistants.
Given the rapid evolution of these models, our landscape analysis provides a current perspective for those assessing the potential of Foundation models.
| Model | Style | Community Engagement |
|---|
| Mixtral 8x7B | MoE transformer model based on Mistral 7B | 1.07k likes |
| Mistral 7B | Transformer model with Grouped-Query Attention, Sliding-Window Attention, and Byte-fallback BPE tokenizer | 1.96k likes |
| LlaMA 2 | Transformer, 70B Parameters, Instruct & Chat | 3,500+ likes and 1.5M+ downloads |
| Phi 2 | Transformer-based model with next-word prediction objective, 2.7B Parameters | 2k likes |
| Vicuna | Transformer, 33B Parameters, Instruct | 900+ likes and 500k+ downloads |
| Falcon | Casual decoder-only, 180B, Task-specific Instruct | 900+ likes and 30k+ downloads |
| MPT | Transformer, 30B, Instruct & Completion | 1k+ likes and 20k+ downloads |
| StableLM | Decoder-only, 7B, Instruct | 354+ likes and 10k+ downloads |
| Yi 34B | Bilingual base model, 34B Parameters | 1k likes |
| Falcon 180B | Super-powerful language model, 180B Parameters | 931 likes |
| MPT-7B | Decoder-style transformer model, 7B Parameters | 1.1k likes |
Zephyr 7B
Zephyr-7B is a large language model (LLM) developed by Hugging Face. It's a fine-tuned version of the Mistral-7B model, trained on a mix of publicly available and synthetic datasets using Direct Preference Optimization (DPO). The model is primarily designed to act as a helpful assistant and is primarily used for tasks in English.
Zephyr-7B was developed in two versions: Alpha and Beta. The Alpha version was the first in the series, and the Beta version followed shortly after, showing improvements in performance.
The model's training involved a process known as knowledge distillation, which allows a smaller model (in this case, the 7 billion parameter Zephyr-7B) to learn from larger models. This approach enables Zephyr-7B to balance performance and efficiency, making it suitable for environments where computational resources are limited, without sacrificing the quality of interaction and understanding.
Zephyr-7B has been evaluated across various benchmarks that assess a model's conversational abilities in both single and multi-turn contexts. It has established new benchmarks for 7B models on MT-Bench and AlpacaEval and showed competitive performance against larger models.
However, it's important to note that the model's performance varies depending on the specific task. For instance, it lags behind in tasks like coding and mathematics. Therefore, users should choose a model based on their specific needs, as Zephyr-7B may not be the best fit for all tasks.
One unique aspect of the Zephyr-7B model is its uncensored nature. While it is uncensored to a certain extent, it has been designed to advise against illegal activities when prompted, ensuring that it maintains ethical guidelines in its responses.
You can use Zephyr-7B locally using LMStudio or UABA Text Generation WebUI, providing flexibility to use the model in your preferred environment. If you're using Python, you can load the model using the Hugging Face Transformers library.
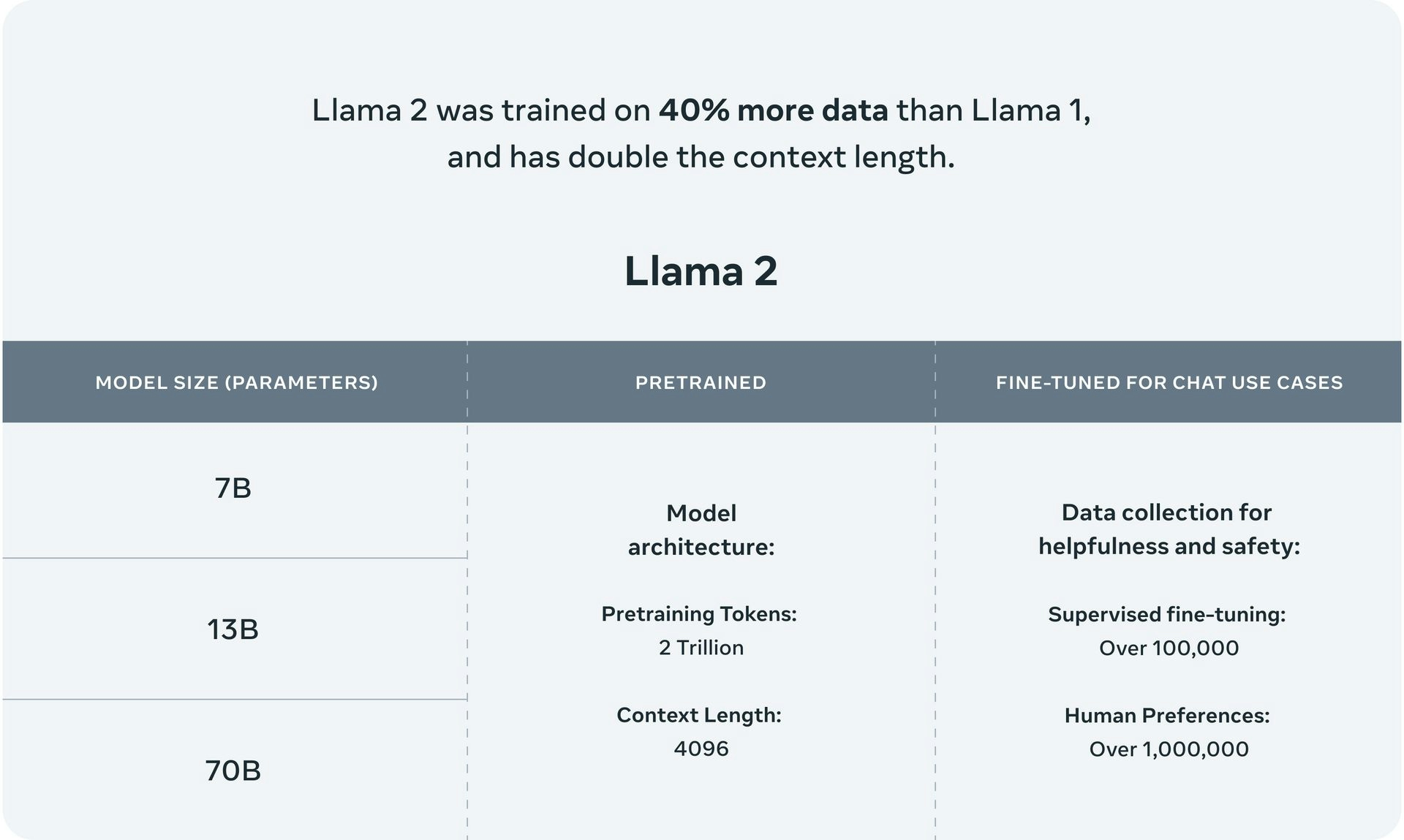
Llama 2
Developed by Meta AI, Llama 2 is an open source LLM with pretrained models ranging from 7B to 70B parameters. It outperforms other open source LLMs on various benchmarks, including reasoning, coding, proficiency, and knowledge tests. Llama 2 also offers fine-tuned models like Llama Chat and Code Llama, which support common programming languages.
| Model Card |
|---|
| Developer: Meta AI |
| Parameters: 7B to 70B |
| Pretrained on: Publicly available online data sources |
| Fine-tuned models: Llama Chat, Code Llama |
| Benchmarks: Outperforms other open source LLMs on reasoning, coding, proficiency, and knowledge tests |
| License: Open source, free for research and commercial use |
| Notable features: Double the context length of Llama 1, reinforcement learning from human feedback for safety and helpfulness |
Llama 2 is an open source large language model (LLM) with parameter sizes ranging from 7B to 65B parameters. While it performs comparably to GPT-3.5, it does not largely outperform GPT-3. The architecture is based on the transformer model, incorporating features such as the SwiGLU activation function, rotary positional embeddings, and root-mean-squared layered normalization.
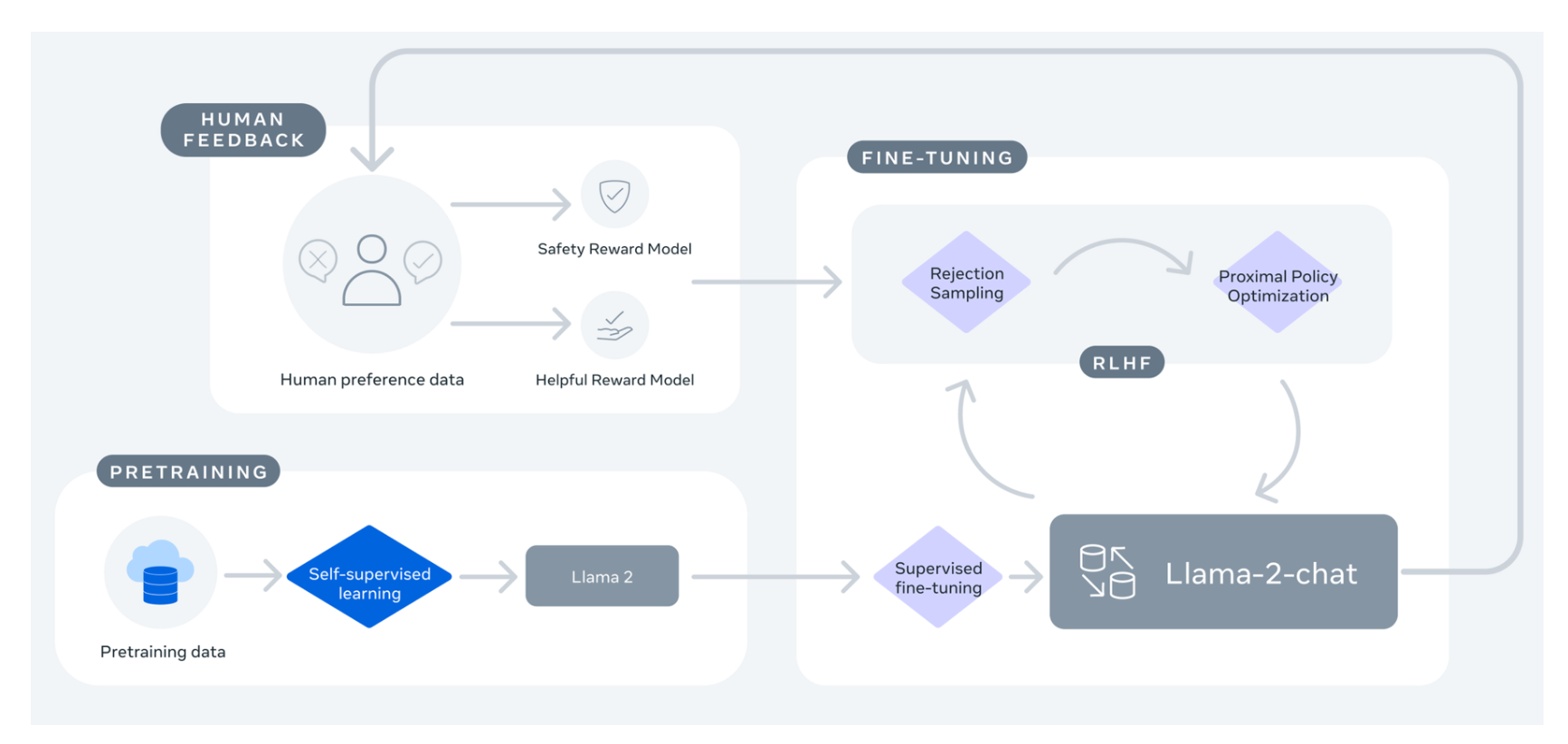
The Llama 2 model is an improved version of its predecessor, offering fine-tuning capabilities for dialogue and chat, including handling multi-task and complex conversational scenarios. Llama 2 benefits from supervised fine-tuning and techniques like Rejection Sampling followed by Proximal Policy Optimization (PPO), which enables it to generate coherent and contextually relevant text. Rejection Sampling (RS) involves sampling a batch of K completions from a language model policy and evaluating them across a reward model, returning the best one. PPO is a popular algorithm for online reinforcement learning.
While the Anthropic paper is not explicitly mentioned in the context of Llama 2, both approaches share similarities in using reinforcement learning from human feedback (RLHF) to improve the performance of their models. In Llama 2, the combination of Rejection Sampling and PPO helps refine the model's outputs, aligning them with human expectations, such as chattiness or safety features.
Llama 2 has been made available through partnerships with industry leaders such as strategic partnership with Microsoft, AWS, Hugging Face, and Snowflake, facilitating the development and deployment of generative AI tools and expanding its accessibility for developers.
The Llama 2-chat variant is specifically fine-tuned for dialogue, with 27,540 prompt-response pairs that allow it to engage in dynamic and contextually rich conversations. The model is trained on 2 trillion tokens from publicly available data sources, excluding personal data from websites.
Despite its advancements, Llama 2 has some limitations. Its substantial computational resource requirements during training and inference may restrict access for smaller businesses and developers. Additionally, its deep neural network architecture makes it difficult to interpret its decision-making process, limiting its usability in critical applications.
In terms of performance, one fine-tuned LLaMa model, Upstage, ranks among the top two models on the Open LLM leaderboard with a score of 72.95 based on the EleutherAI Evaluation Harness. Also, the current leader on the Open LLM leaderboard is a merge of the Llama model with two fine-tuned Llama models (Upstage and Platypus2) that showcases the extensiveness and performance capabilities of the Llama model.
You can access Llama 2 via the Model's Download page or their GitHub, and for technical individuals, find out more about the model within their paper.
Mistral 7B
Mistral 7B is a 7-billion-parameter LLM developed by Mistral AI. It outperforms Llama 2 13B on all benchmarks and uses Sliding Window Attention (SWA) to optimize the model's attention process, resulting in significant speed improvements.
| Model Card |
|---|
| Developer: Mistral AI |
| Parameters: 7 billion |
| Model Architecture: Transformer model with Grouped-Query Attention, Sliding-Window Attention, and Byte-fallback BPE tokenizer |
| Benchmarks: Outperforms Llama 2 13B on all tested benchmarks |
| License: Apache 2.0 |
Yi 34B
Yi 34B is a bilingual (English and Chinese) base model with 34 billion parameters, developed by 01.AI. It outperforms larger open models like Falcon-180B and Meta LlaMa2-70B on Hugging Face's ranking.
| Model Card |
|---|
| Developer: 01.AI |
| Parameters: 34 billion |
| Languages: English and Chinese |
| Model type: Bilingual base model |
| Ranking: Outperforms Falcon-180B and Meta LlaMa2-70B on Hugging Face's ranking |
Falcon 180B
Falcon 180B is a super-powerful language model developed by the Technology Innovation Institute (TII). It has 180 billion parameters and was trained on 3.5 trillion tokens. Falcon 180B currently ranks at the top of the Hugging Face Leaderboard for pre-trained Open Large Language Models and is available for both research and commercial use.
This model performs exceptionally well in various tasks like reasoning, coding, proficiency, and knowledge tests, even beating competitors like Meta's Llama 2. Among closed-source models, it ranks just behind OpenAI's GPT 4 and performs on par with Google's PaLM 2 Large, which powers Bard, despite being half the size of the model.
| Model Card |
|---|
| Developer: Technology Innovation Institute (TII) |
| Parameters: 180 billion |
| Model Architecture: Not specified |
| Pretrained on: 3.5 trillion tokens |
| Benchmarks: Top of the Hugging Face Leaderboard for pre-trained Open Large Language Models. Outperforms Meta's Llama 2 and performs on par with Google's PaLM 2 Large |
| License: Available for both research and commercial use |
| Notable features: Exceptional performance in reasoning, coding, proficiency, and knowledge tests. |
The download of Falcon 180B is subject to TII's Terms & Conditions and Acceptable Use Policy.
Developed by the Technology Innovation Institute under the Apache 2.0 license, the Falcon LLM is another powerful open source LLM that brings a lot of promise in terms of innovation and precision. Trained on 40 billion parameters and an astounding 1 trillion tokens using 384 GPUs on AWS, Falcon makes use of the autoregressive decoder architecture type.
Setting itself apart, Falcon takes an unconventional route by prioritizing data quality over sheer volume. Leveraging a specialized data pipeline and custom coding, it harnesses the RefinedWeb Dataset, which stems from publicly available web data meticulously filtered and deduplicated. Also, it makes use of rotary positional embeddings (similar to LLaMa) and Multiquery and FlashAttention for attention.
With its instruct models for 7B and 40B parameters, Falcon offers adaptability for various use cases, including dialogues and chats. Using the EleutherAI Evaluation framework, the most perfomant falcon model based on the 40B parameter has a score of 63.47. Also, on the Chatbot Arena leaderboard, the Falcon 40B Instruct has a 5.17 out of 10 on the MT-Bench benchmark.
Yet, the Falcon LLM has its limitations as with any LLM. It's limited to a few languages - English, German, Spanish and French. Also, its training data sources introduce potential stereotypes and biases found on the web. Additionally, the lack of a detailed technical paper to show reliability, risk, and bias assessment make it essential to use carefully, especially in production or critical environment.
Access, fine-tune, and deploy the Falcon 40B model via Hugging Face.
MPT-7B
MPT-7B is a decoder-style transformer model developed by MosaicML. It is pretrained from scratch on 1 trillion tokens of English text and code. MPT-7B is part of the MosaicPretrainedTransformer (MPT) family, which uses a modified transformer architecture optimized for efficient training and inference. These architectural changes include performance-optimized layer implementations and the elimination of context length limits by replacing positional embeddings with Attention with Linear Biases (ALiBi).
| Model Card |
|---|
| Developer: MosaicML |
| Parameters: 6.7 billion |
| Model Architecture: Decoder-style transformer |
| Pretrained on: 1 trillion tokens of English text and code |
| License: Apache 2.0 |
| Notable features: ALiBi for handling extremely long inputs (up to 84k tokens), FlashAttention for fast training and inference, Highly efficient open source training code via the llm-foundry repository |
MPT-7B has been shown to outperform other open source 7B-20B models and match the quality of LLaMa-7B. The MPT family includes other models such as MPT-7B-Instruct, MPT-7B-Chat, and MPT-7B-StoryWriter-65k+, which are finetuned for specific tasks.
MPT, or MosaicML Performance Transformer, stands as a differential open source LLM that can push the boundaries of what LLMs can achieve. This Apache 2.0 licensed model has not only reached impressive heights in terms of performance but also emphasizes commercial usability.
Trained on Oracle Cloud's A100-40Gb and A100-80GB GPUs, MPT differentiates itself through a unique data pipeline approach. Unlike other models, MosiacML employed a mixture of data pipelines and EleutherAI's GPT-NeoX alongside a 20B tokenizer. The weights are freely available to the public via GitHub.
The MPT has a transformer model that makes use of 1 trillion tokens which contains both text and code. Its architecture consists of three finely tuned variants; MPT-7B-Instruct, MPT-7B-Chat, and MPT-7B-StoryWriter-65k+. Each variant caters to different applications, from instruction following to chatbot-like dialogue generation.
MosiacML's capabilities in model development shine through their toolset, Composter, LLM Foundry, LION Optimizer, and PyTorch FSDP, which were used to fine-tune MPT. The architecture of the MPT model underwent optimization to eliminate context length limits by incorporating Attention with Linear Biases (ALiBi).
You can fine-tune the model with other transformers and data pipelines via Hugging Face and train using the MosiacML platform. In addition, to access the training code for MosiacML foundation models (MPT-7B and MPT-30B, and their variants), make use of their GitHub. You can configure and fine-tune the MPT-7B via langchain and easily configure using typical notebooks such as Google Colab.
In terms of performance with other models, the most performant MPT LLM mode in terms of dialogue and chat - MPT-30B-chat - scored 1046 and 6.39 in Arena Elo rating and MT-bench score respectively, behind Vicuna-33B but ahead of Llama-2-13b-chat (Arena Elo rating). Also, the MPT-30B LLM model in the Open LLM leaderboard has a 61.21 average score behind the Falcon model. However, MPT is not intended for deployment without any finetuning and developers should make sure to place well-defined guardrails. Also, the model can sometimes produce factually incorrect output as with all LLM models.
Phi 2
Phi-2, developed by Microsoft with 2.7 billion parameters, is a Transformer-based LLM trained on 1.4 trillion tokens of synthetic data from GPT-3.5-turbo. Despite its size, Phi-2 competes with models up to 25 times larger, including outperforming the 70 billion parameter Llama-2 in reasoning, language understanding, and coding benchmarks. It was trained for two weeks on a cluster of 96 A100 GPUs, focusing on Python and common libraries like "typing, math, random, collections, datetime, itertools". Users should verify any generated code using other packages or languages.
While Phi-2 has not been fine-tuned for following instructions, it may exhibit societal biases present in its training data. Microsoft offers Phi-2 via Azure AI Studio for research, but it's not validated for production tasks. Users should load the model with trust_remote_code=True when using transformers version 4.36.0 or later and consider outputs as suggestions. Phi-2's training is cost-effective, but it requires precise prompts to adhere to instructions, underscoring the nuances of prompt-driven LLMs.
| Model Card |
|---|
| Developer: Microsoft Research |
| Parameters: 2.7 billion |
| Model Architecture: Transformer-based model with next-word prediction objective |
| Pretrained on: Subsets of Python codes from StackOverflow, competition code from code contests, synthetic Python textbooks, exercises generated by GPT-3.5-turbo-0301, and various NLP synthetic texts |
| Benchmarks: Nearly state-of-the-art performance among models with 1.4 trillion parameters when assessed against benchmarks testing common sense, language understanding, and logical reasoning. Outperforms Meta's Llama2-7B in AGIEval score and nearly up to par with Llama2-7B in GPT4ALL's Benchmark suite with LM-Eval Harness. |
| License: Open source, free for research use |
| Notable features: Excels at complex reasoning tasks, trained on high-quality synthetic data, and demonstrates human-like coding abilities without the need for vast parameters. |
Which Open Source LLM variants are the best?
In the following sections, we will explore some of the most popular and high-performing open source LLM variants including Zephyr 7B, OpenOrca Platypus2 13B, MythoMax L2 13b, Vicuna 13B v1.5 16k, and OpenHermes 2.5 Mistral 7B. Each of these models has unique features and capabilities, and understanding these can help you choose the most suitable model for your specific needs. Most popular open source LLM variants are primarily utilized for chat and role-playing applications, rather than coding or productivity-related tasks.
OpenOrca Platypus2 13B
OpenOrca-Platypus2-13B is a large language model developed as a merge of garage-bAInd/Platypus2-13B and Open-Orca/OpenOrcaxOpenChat-Preview2-13B. It is an auto-regressive language model based on the Llama 2 transformer architecture and is designed for chat, text generation, and code generation.
The model has achieved impressive results, outperforming the original Llama-65B model in some benchmarks. It has been evaluated using standard benchmarks like MMLU (5-shot), ARC (25-shot), HellaSwag (10-shot), and TruthfulQA (0-shot), with an average score of 64.56.
OpenOrca-Platypus2-13B is available on Hugging Face, and you can use it through their API or command-line interface. To run the model, you'll need a powerful GPU with at least 10 GB of VRAM, such as an AMD 6900 XT, RTX 2060 12GB, RTX 3060 12GB, or RTX 3080. For CPU inference (GGML/GGUF) format, you'll need around 8 GB of available RAM.
MythoMax L2 13b
The MythoMax L2 13B is a large language model developed by Gryphe and further improved by TheBloke. It's an advanced variant of MythoMix, which is a merge of MythoLogic-L2 and Huginn using a highly experimental tensor-type merge technique. This merge technique involves each layer of the model being composed of several tensors that are responsible for specific functions.
The model is proficient at both roleplaying and storywriting due to its unique nature. It uses MythoLogic-L2's robust understanding as its input and Huginn's extensive writing capability as its output, resulting in a model that excels at both tasks.
TheBloke provides multiple quantized versions of the model, each with different bit sizes, file sizes, and RAM requirements. These versions range from 2-bit to 8-bit, with the 4-bit and 5-bit versions being recommended for most purposes due to their balance of quality and resource usage.
The model is compatible with many third-party UIs and libraries, and it can be used with different front-end interfaces like SillyTavern and Oobabooga. However, the performance (measured in tokens per second) can vary significantly depending on the hardware and the specific quantized version of the model used.
Unlike many language models that have built-in content moderation or restrictions, MythoMax L2 13B is fully uncensored, meaning it can generate any type of content and does not have built-in mechanisms to prevent the generation of inappropriate or harmful content.
Vicuna 13B v1.5 16k
Vicuna 13B v1.5 16k is a large language model developed by LMSYS, fine-tuned from Llama 2 on user-shared conversations collected from ShareGPT. It is an auto-regressive language model based on the transformer architecture and is primarily used for research on large language models and chatbots. The model has a context length of 16k tokens, which allows it to handle longer conversations and maintain context over a more extended dialogue.
Vicuna 13B v1.5 16k has been evaluated using standard benchmarks, human preference, and LLM-as-a-judge, showing promising results. Users have reported good performance with the model, with one user achieving 33-35 tokens per second on an RTX 3090 using the 4-bit quantized model. However, some users have experienced issues with repetition and output quality when using the model with specific settings or token lengths.
To run Vicuna 13B v1.5 16k, you'll need a powerful GPU with at least 10 GB of VRAM, such as an AMD 6900 XT, RTX 2060 12GB, RTX 3060 12GB, or RTX 3080. For the CPU inference (GGML/GGUF) format, you'll need around 8 GB of available RAM. Note that the performance of the model depends on the hardware it's running on, and the RAM bandwidth plays a crucial role in the model's efficiency.
Vicuna, the brainchild of the Large Model Systems Organization, brings new ideas to the accessibility of Large Language Models (LLMs). Designed as an open source chatbot, Vicuna finds its root in fine-tuning the Llama 2 model using user-generated conversations obtained via ShareGPT (a means to share OpenAI's GPT-3.5 and GPT-4 conversations). Its unique approach allows it to outperform other models such as Llama 1 and Stanford Alpaca (a fine-tuned version of Llama).
Trained on 7 and 13 billion parameters, Vicuna boasts exceptional fluency and context retention. The model is geared towards human-like conversions with fine-tuning data drawn from 370M tokens. Based on Llama 2, it employs the same transformer model with an auto-regressive function and makes use of 16K context-length versions using linear RoPE scaling.
The commitment to open source is evident in Vicuna's accessible codebase and weight repo. While tailored for noncommercial use, Vicuna also offers instruct models to enhance its versatility. The model enjoys a vibrant developer and community-based involvement with more than 383 thousand downloads for version 1.3.
As far as relative performance and evaluation, it stands tall in the Hugging Face LLM chatbot leaderboard, boasting an impressive 1096 Arena Elo rating and a 7.12 out of 10 in MT-Bench grading. These scores overshadow Llama, its foundational model, in the realm of multi-turn question handling and dialogue optimization.
Vicuna's prowess extends to the more broad Open LLM leaderboard where its most performant 33B model achieves an impressive score of 65.21 through Eleuther evaluation.
Access to Vicuna and the datasets via Hugging Face.
OpenHermes 2.5 Mistral 7B
OpenHermes 2.5 Mistral 7B is an advanced large language model (LLM) developed by Teknium. It's named after Hermes, the Messenger of the Gods in Greek mythology, reflecting its purpose to navigate the complexities of human discourse.
This model is a continuation of the OpenHermes 2 model, with additional training on code datasets. An interesting finding from this training was that a good ratio (estimated around 7-14% of the total dataset) of code instruction boosted several non-code benchmarks, including TruthfulQA, AGIEval, and GPT4All suite. However, it did reduce the BigBench benchmark score, but the net gain overall was significant.
OpenHermes 2.5 Mistral 7B was trained on 1,000,000 entries of primarily GPT-4 generated data, as well as other high-quality data from open datasets across the AI landscape. The data underwent extensive filtering and conversion to the ShareGPT format, which was then further transformed by axolotl to use ChatML.
The model now uses ChatML as the prompt format, which provides a more structured system for engaging the LLM in multi-turn chat dialogue. This allows the model to utilize system prompts from the prompt to more strongly engage in instructions that span over many turns.
In terms of performance, OpenHermes 2.5 on Mistral-7B outperforms all previous Nous-Hermes & Open-Hermes models, except for Hermes 70B, and surpasses most of the current Mistral finetunes across the board.
The performance of an OpenHermes model depends heavily on the hardware it's running on. For example, a 4-bit 13B billion parameter OpenHermes model takes up around 7.5GB of RAM. If your RAM bandwidth is 50 GBps (DDR4-3200 and Ryzen 5 5600X), you can generate roughly 6 tokens per second. But for fast speeds like 11 tokens per second, you'd need more bandwidth - DDR5-5600 with around 90 GBps.
The model is available in different formats, including GGUF, with varying levels of quantization, size, and RAM requirements. For instance, the Q4_K_M version of the model, which is recommended for most purposes, requires 4.37 GB of storage and 6.87 GB of RAM.
In terms of user feedback, OpenHermes 2.5 Mistral 7B has been praised for its ability to follow instructions and generate human-like responses. However, some users have noted that it can sometimes generate long, rambling responses.
Chronos Hermes
The Chronos-Hermes LLM is a large language model that combines two LLaMa-based language models, Chronos and Nous-Hermes, in a 75/25 ratio. The Chronos model is known for generating long, descriptive outputs, making it particularly useful for storytelling. The addition of Nous-Hermes enhances the model's coherence and ability to follow instructions, providing a balance between vivid scene-setting and grounded, on-track responses.
The Chronos-Hermes model is available in various versions and file formats, including GGML, GPTQ, and HF. The performance of the model heavily depends on the hardware it's running on. For instance, a 4-bit 13 billion parameter Chronos-Hermes model requires around 7.5GB of RAM. The RAM bandwidth and model size significantly impact the inference speed. For example, with a RAM bandwidth of 50 GBps (DDR4-3200 and Ryzen 5 5600X), you can generate roughly 6 tokens per second.
Users have praised the Chronos-Hermes 13B model for its ability to generate complex sentences with a good variety of vocabulary. It's noted for its excellent prose and ability to take into account all contextual elements put forward, following instructions to the letter. The model has been reported to outperform other 30B models despite being a 13B LLM.
The model is available in different quantization methods, each with varying size, RAM requirements, and quality loss. For instance, the Q4_K_M version is recommended for its balanced quality, requiring 7.87 GB of storage and 10.37 GB of maximum RAM.
In terms of use cases, the Chronos-Hermes model excels in chat, role-playing, and story writing. It's also capable of simple reasoning and coding tasks. When placed in 'instruct mode', it has shown optimized performance on platforms like SillyTavern.
What models are leading the HuggingFace LLM leaderboard?
The LLM Leaderboard provides a direct comparison of the performance of various Large Language Models (LLMs) across different tuning categories. The LLM Leaderboard provides insights into the preferences and performance of Large Language Models (LLMs) across different tuning categories and sizes. Notably, there is a clear user preference for certain models within each tuning type:
-
Pretrained Models (🟢) — 01-ai/Yi-34B stands out with the highest download (69.8k) and like (1.01k) counts among the pretrained category, indicating a strong user preference for this model in the 30B size range. Pretrained models generally enjoy high engagement, suggesting that users value models that are ready to use without additional customization, but also prefer to start from these for additional tuning.
-
Fine-Tuned Models (🔶) — Intel/neural-chat-7b-v3-1 has a notably high like count (255) for fine-tuned models in the 7B size category, suggesting that users find this model particularly effective or useful after its specialized fine-tuning process.
-
Instruction-Tuned Models (⭕) — These models have a lower engagement compared to pretrained models, with the exception of the 30B category where garage-bAInd/Platypus-30B has a relatively high download count (9.57k). This might indicate a niche but dedicated interest in models that are tailored for specific instructional contexts.
-
RL-Tuned Models (🟦) — The RL-tuned category includes the overall highest-performing model in terms of user engagement, meta-llama/Llama-2-70b-chat-hf, with over 1 million downloads and 1.67k likes. This suggests that models tuned with reinforcement learning are highly valued, possibly due to their ability to generate more contextually appropriate responses.
The data suggests that while there's a general trend towards larger models receiving more downloads and likes, the tuning method also plays a significant role in user preference. Pretrained models are widely used, but there's a clear interest in models that have been further refined through fine-tuning, instruction-tuning, or reinforcement learning, especially when they are in the larger size categories (30B and 65B), which are seen as more capable or versatile.
| Model Name | Tuning | Last Updated | Downloads | Likes | Note |
|---|
| Qwen/Qwen-7B | Pretrained | 12 days ago | 13.3k | 292 | Best 🟢 around 7B |
| TigerResearch/tigerbot-13b-base | Pretrained | 8 days ago | 6.62k | 8 | Best 🟢 around 13B |
| 01-ai/Yi-34B | Pretrained | 2 days ago | 69.8k | 1.01k | Best 🟢 around 30B |
| TigerResearch/tigerbot-70b-base | Pretrained | 8 days ago | 5.4k | 14 | Best 🟢 around 65B |
| GeneZC/MiniChat-3B | Fine-tuned | 4 hours ago | 2.19k | 25 | Best 🔶 around 3B |
| vihangd/shearedplats-2.7b-v2 | Instruction-tuned | 5 days ago | 638 | 1 | Best ⭕ around 3B |
| maywell/Synatra-7B-v0.3-RP | Instruction-tuned | 6 days ago | 2.79k | 9 | Best ⭕ around 7B |
| DanielSc4/RedPajama-INCITE-Chat-3B-v1-RL-LoRA-8bit-test1 | RL-tuned | Aug 10 | N/A | N/A | Best 🟦 RL-tuned around 3B |
| garage-bAInd/Platypus-30B | Instruction-tuned | Jul 25 | 9.57k | 18 | Best ⭕ around 30B |
| meta-llama/Llama-2-7b-chat-hf | RL-tuned | 13 days ago | 954k | 1.91k | Best 🟦 around 7B |
| meta-llama/Llama-2-13b-chat-hf | RL-tuned | 13 days ago | 498k | 705 | Best 🟦 around 13B |
| MayaPH/GodziLLa2-70B | Instruction-tuned | 17 days ago | 5.67k | 32 | Best ⭕ around 65B |
| Yhyu13/oasst-rlhf-2-llama-30b-7k-steps-hf | RL-tuned | Aug 4 | 4.95k | 6 | Best 🟦 around 30B |
| Locutusque/gpt2-large-conversational | RL-tuned | 7 days ago | 5.54k | 4 | Best 🟦 around 1B |
| meta-llama/Llama-2-70b-chat-hf | RL-tuned | 13 days ago | 1.07M | 1.67k | Best 🟦 around 65B |
| tiiuae/falcon-rw-1b | Pretrained | Jul 12 | 37.2k | 67 | Best 🟢 around 1B |
| stabilityai/stablelm-3b-4e1t | Pretrained | Oct 25 | 18.1k | 241 | Best 🟢 around 3B |
| euclaise/falcon_1b_stage3_2 | Fine-tuned | Sep 25 | 6.43k | N/A | Best 🔶 around 1B |
| Aspik101/trurl-2-13b-pl-instruct_unload | Fine-tuned | Aug 18 | 5.16k | 6 | Best 🔶 around 13B |
| upstage/llama-30b-instruct-2048 | Fine-tuned | Aug 3 | 7.58k | 103 | Best 🔶 around 30B |
| sequelbox/StellarBright | Fine-tuned | Oct 17 | 5.49k | 42 | Best 🔶 around 65B |
| yulan-team/YuLan-Chat-2-13b-fp16 | Instruction-tuned | Sep 1 | 4.83k | 12 | Best ⭕ around 13B |
| 42dot/42dot_LLM-SFT-1.3B | Instruction-tuned | 29 days ago | 7.21k | 18 | Best ⭕ around 1B |
| Intel/neural-chat-7b-v3-1 | Fine-tuned | 2 days ago | 9.22k | 255 | Best 🔶 around 7B |
(Note: The notes column includes emojis to denote the type of tuning: 🟢 for pretrained, 🔶 for fine-tuned, ⭕ for instruction-tuned, and 🟦 for RL-tuned models.)
Using Open Source LLMs in Production
Open source LLMs are shaping the future of text generation and generative AI by opening up access to advanced language models (faster feedback), fostering innovation (open research), and enabling diverse applications across industries (diverse ideas).
From Llama 2 to Mistral, these models bring new approaches and means to the LLM world. While these models exhibit remarkable capabilities, it's essential to know how to navigate their limitations - lower performance differences from proprietary LLMs, limited guardrails against bias, incorrect answers, and high computational cost. In many cases, moving to open source LLMs only makes sense at scale (30k+ daily generations) or when data privacy is paramount.
As you explore these open source LLMs, use Klu.ai to evaluate prompt performance against proprietary LLMs like OpenAI's GPT-4 Turbo, Anthropic's Claude 2.1, and Google's PaLM2, among others, and open source LLMs if hosted by Replicate, AWS, or Hugging Face.
By utilizing Klu, you can harness the power and capabilities of cutting-edge LLMs to build generative AI apps that work and transform your development pipeline.
The emergence of open source large language models marks a new era where innovation, creativity, and progress in generative AI grows ever more collaborative and accessible - lighting a path towards an intelligent future we build together.