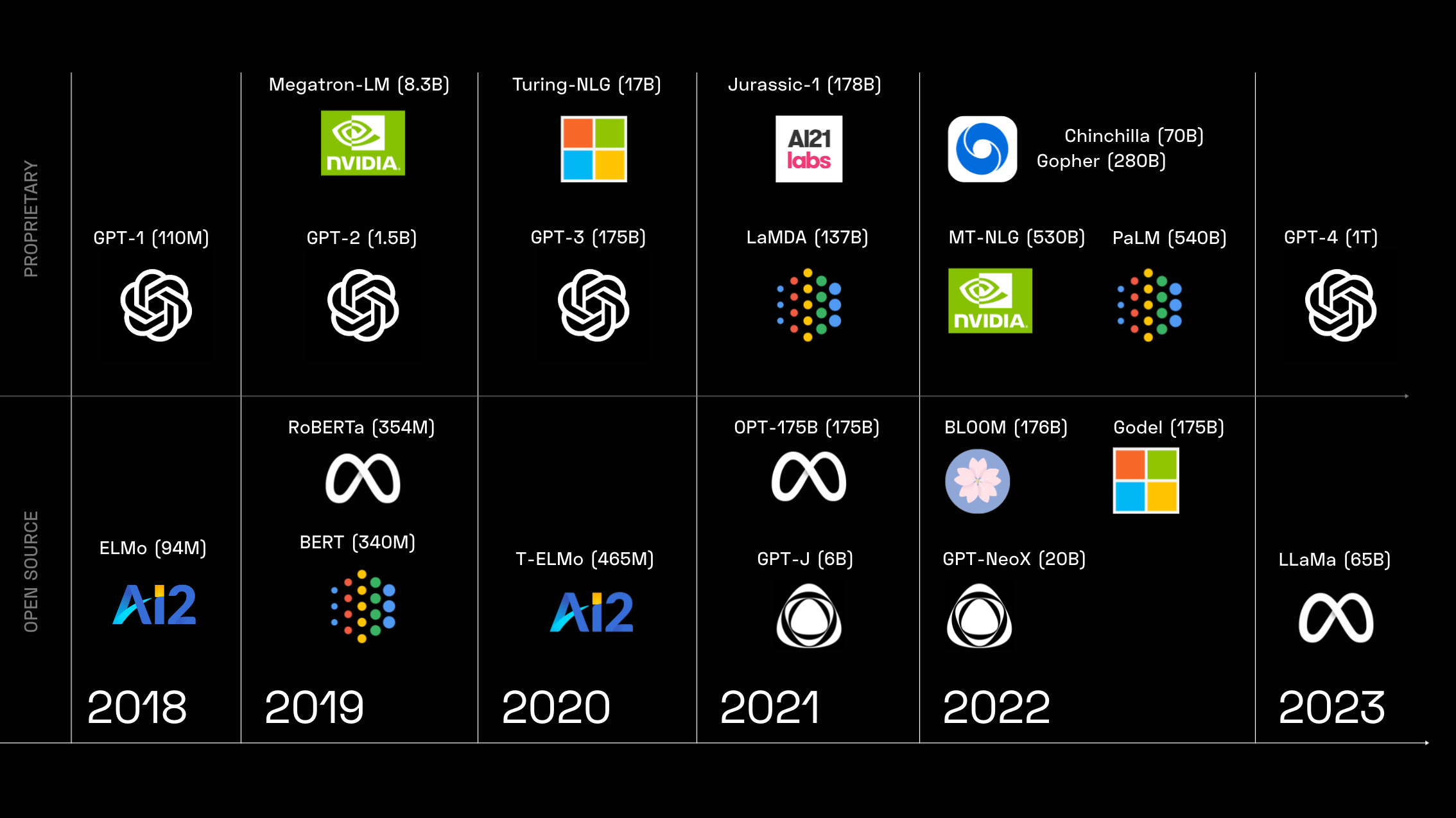
In this article, we dive into the 5 most promising open-source LLMs in 2023 based on accessibility, capabilities, and community support. For developers and researchers looking to harness advanced natural language generation, these models offer new possibilities without the barriers to entry of closed models.
We compare and contrast key details on model architecture, training data, performance metrics, customization options, and community engagement. Whether you want to build a chatbot, generate stories, or power your product's AI, these open-source LLMs can take your projects to the next level. Read on to determine which option best fits your needs.
Unlocking LLMs on Your Laptop
Experimenting with cutting-edge AI on your own computer is easier than ever thanks to open-source large language models (LLMs). With just a few simple steps, you can access some of the most advanced natural language systems on your own laptop.
You can chat with the LLaMA 2, Vicuna, and MPT LLM models via the LMSYS Chatbot Arena.
OpenPlayground
The easiest way to get started is to use the Python package openplayground. After installing it with pip, you can launch an intuitive UI for experimenting with models like GPT-3.5 and PaLM directly in your browser. The openplayground makes it simple to try out different model sizes, tweak parameters, and see how LLMs interpret and generate text.
Here's a step-by-step guide to using openplayground:
- Install the openplayground package by running the following command in your terminal:
pip install openplayground
- Launch openplayground by running the following command in your terminal:
openplayground
llama.cpp
For more customization and performance, you can run models locally using tools like llama.cpp. This gives you full control to load pretrained models from Hugging Face and inference them on your CPU or GPU. Just be sure to download a model size that fits within your laptop's RAM, like a 7B parameter model. The llama.cpp library wraps the models in an easy API for Python, Go, Node.js and more.
Running your own LLM gives you privacy, speed, and flexibility. You can use the models for personalized projects without relying on APIs. So with just a bit of setup, you can unlock the latest AI to generate content, classify text, answer questions and more right on your local machine.
For running models locally with llama.cpp, follow these steps:
-
Download the LLM model of your choice, such as the 7B parameter model guanaco-7B-GGML from Hugging Face.
-
Install the llama.cpp library or its wrappers for your preferred programming language, such as Python, Go, or Node.js.
-
Load the downloaded LLM model using the llama.cpp library or its wrapper.
-
Use the LLM model for inference, generating text, or other tasks as needed.
-
Ensure your laptop has sufficient RAM (at least 12 or 16GB) to run the LLM model.
We're big fans of llama.cpp and the revolution Georgi Gerganov started.
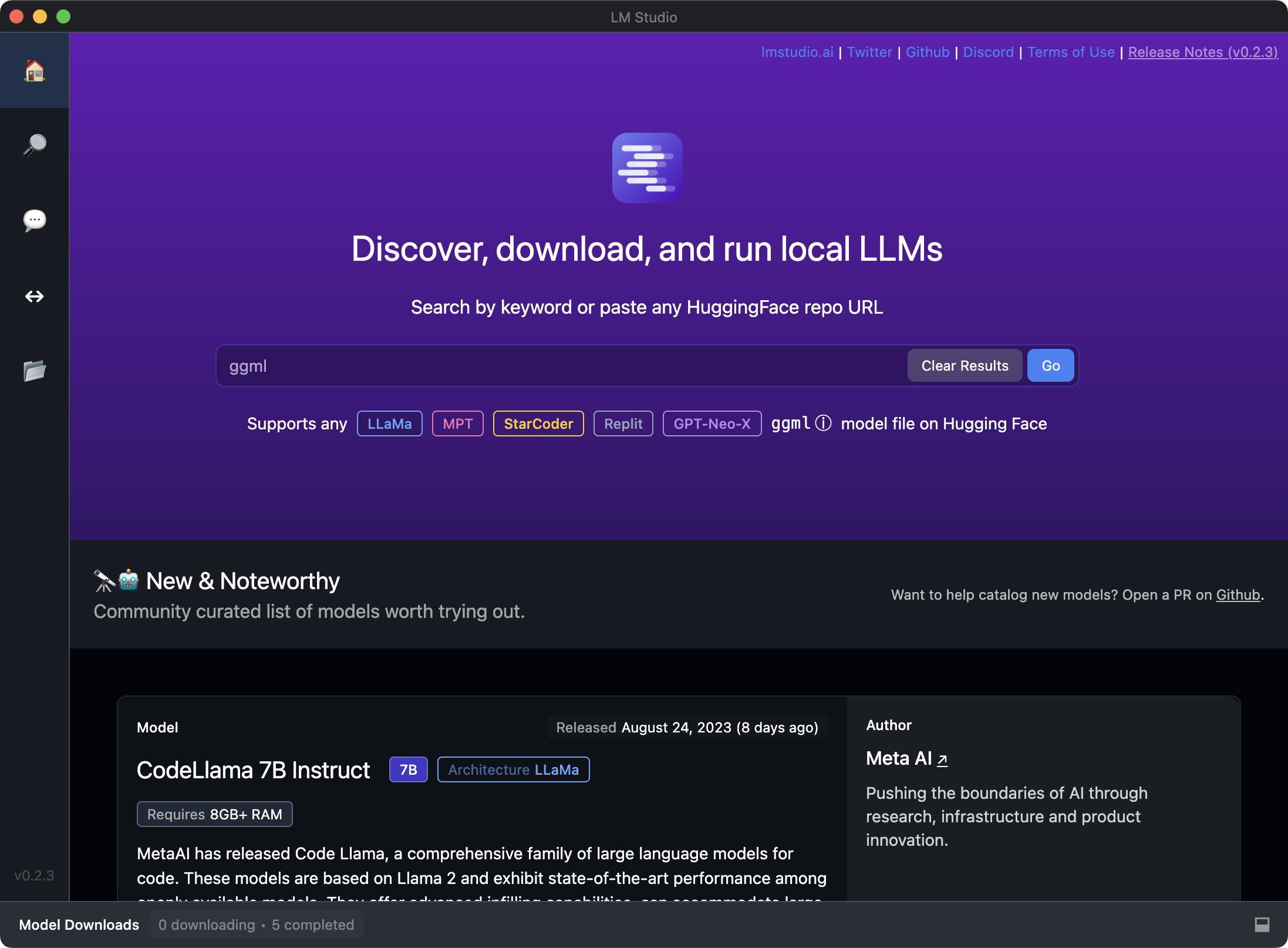
LM Studio
LM Studio is a desktop application that allows you to discover, download, and run local and open-source Large Language Models (LLMs) on your laptop. It provides an easy-to-use interface for experimenting with LLMs without the need for command-line setup. The application is cross-platform and can be used on macOS.
To get started with LM Studio, follow these steps:
-
Visit the LM Studio website and download the application for your operating system (macOS in your case).
-
Install LM Studio on your laptop by following the installation instructions provided.
-
Launch LM Studio, and you'll be able to discover and download various open-source LLMs.
-
Once you've downloaded an LLM, you can use LM Studio's interface to run the model locally on your laptop.
We're big fans of LM Studio at Klu.
Which Open Source LLMs are the best?
Best is hard to define – it depends on your use case and expectations. Llama 2 and MPT are the most interesting for me.
Many open-source LLMs exist today, but within this myriad, only a few stand out as practical, efficient, and extensive models that are useful. Here are the five best open-source LLMs we found compelling across different use cases and features.
- Llama 2
- Vicuna
- Falcon
- MPT
- Stability FM
These models come with their parameters, architecture type, features, and performance. Also, they allow for access to extensive and powerful language processing features. And they allow the average person - developers and researchers - to work, build, and innovate for different industries.
| Model | Style | Community Engagement |
|---|
| LlaMA 2 | Transformer, 70B Parameters, Instruct & Chat | 3,500+ likes and 1.5M+ downloads |
| Vicuna | Transformer, 33B Parameters, Instruct | 900+ likes and 500k+ downloads |
| Falcon | Casual decoder-only, 40B, Task-specific Instruct | 700+ likes and 30k+ downloads |
| MPT | Transformer, 30B, Instruct & Completion | 500+ likes and 20k+ downloads |
| StableLM | Decoder-only, 7B, Instruct | 300+ likes and 10k+ downloads |
LLama 2
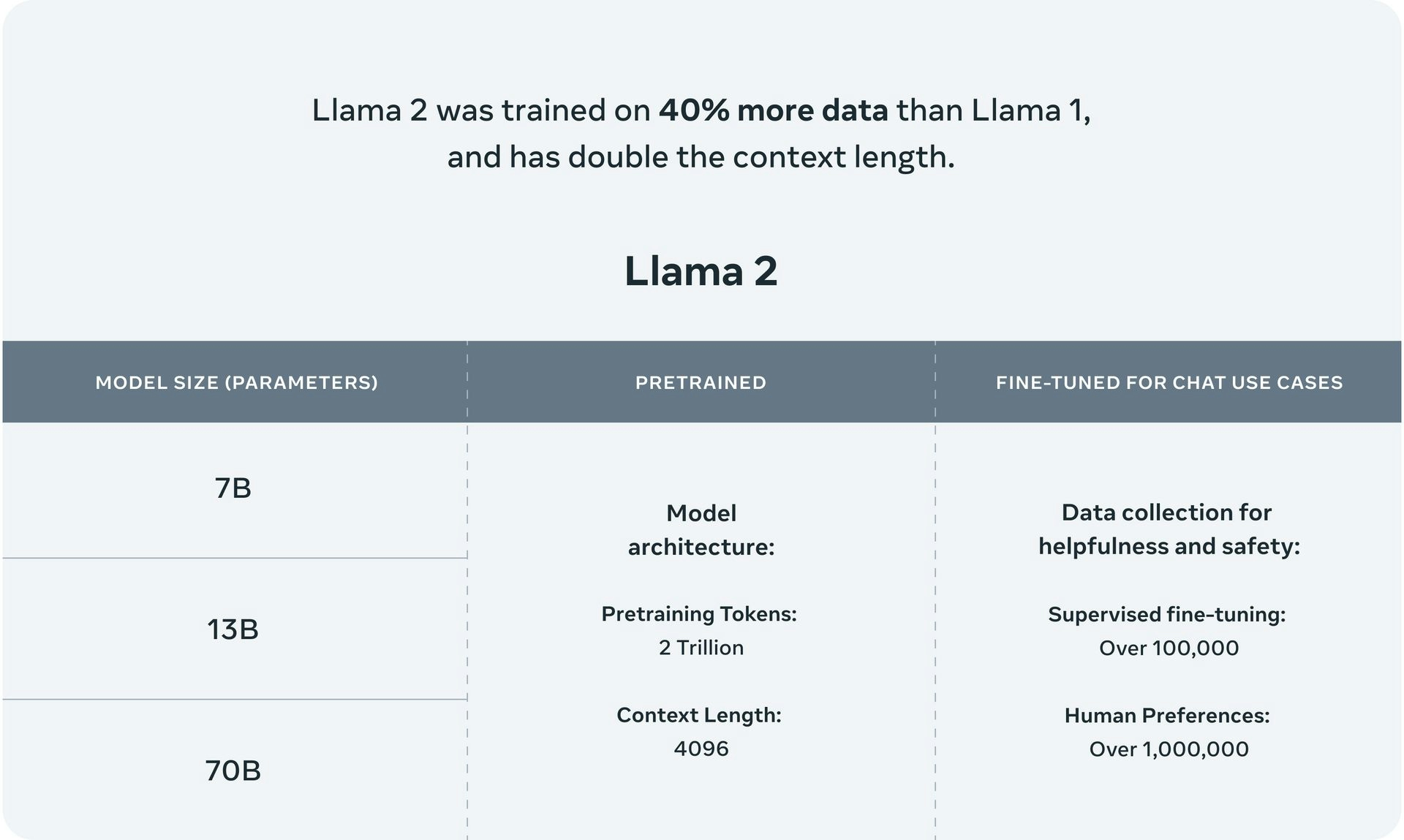
LLaMA 2 is an open-source large language model (LLM) with parameter sizes ranging from 7B to 65B parameters. While it performs comparably to GPT-3.5, it does not largely outperform GPT-3. The architecture is based on the transformer model, incorporating features such as the SwiGLU activation function, rotary positional embeddings, and root-mean-squared layered normalization.
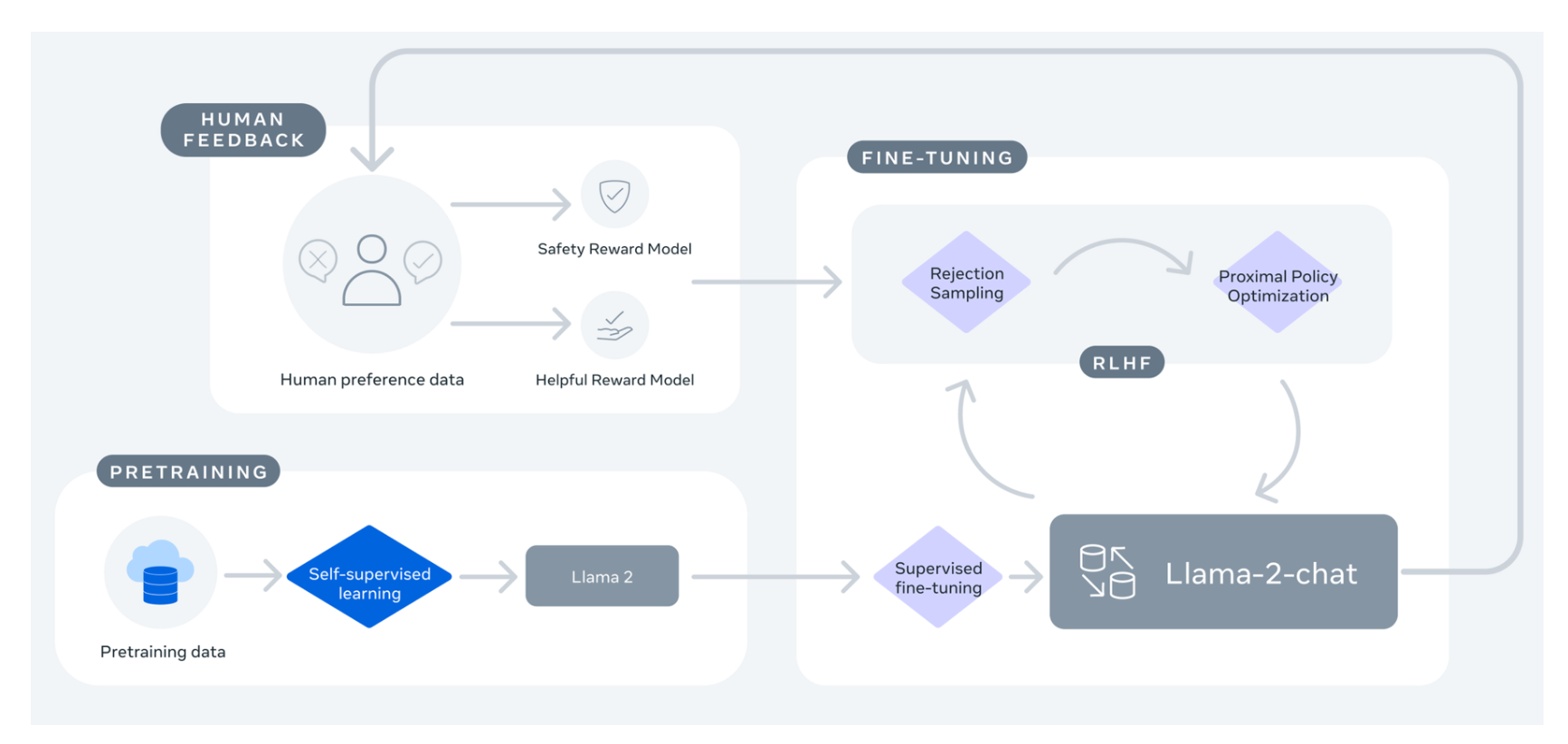
The LLaMA 2 model is an improved version of its predecessor, offering fine-tuning capabilities for dialogue and chat, including handling multi-task and complex conversational scenarios. Llama 2 benefits from supervised fine-tuning and techniques like Rejection Sampling followed by Proximal Policy Optimization (PPO), which enables it to generate coherent and contextually relevant text. Rejection Sampling (RS) involves sampling a batch of K completions from a language model policy and evaluating them across a reward model, returning the best one. PPO is a popular algorithm for online reinforcement learning.
While the Anthropic paper is not explicitly mentioned in the context of Llama 2, both approaches share similarities in using reinforcement learning from human feedback (RLHF) to improve the performance of their models. In Llama 2, the combination of Rejection Sampling and PPO helps refine the model's outputs, aligning them with human expectations, such as chattiness or safety features.
LLaMA 2 has been made available through partnerships with industry leaders such as strategic partnership with Microsoft, AWS, Hugging Face, and Snowflake, facilitating the development and deployment of generative AI tools and expanding its accessibility for developers.
The LLaMA 2-chat variant is specifically fine-tuned for dialogue, with 27,540 prompt-response pairs that allow it to engage in dynamic and contextually rich conversations. The model is trained on 2 trillion tokens from publicly available data sources, excluding personal data from websites.
Despite its advancements, LLaMA 2 has some limitations. Its substantial computational resource requirements during training and inference may restrict access for smaller businesses and developers. Additionally, its deep neural network architecture makes it difficult to interpret its decision-making process, limiting its usability in critical applications.
In terms of performance, one fine-tuned LLaMa model, Upstage, ranks among the top two models on the Open LLM leaderboard with a score of 72.95 based on the EleutherAI Evaluation Harness. Also, the current leader on the Open LLM leaderboard is a merge of the LLaMA model with two fine-tuned LLaMA models (Upstage and Platypus2) that showcases the extensiveness and performance capabilities of the LLaMA model.
You can access LLaMA 2 via the Model's Download page or their GitHub, and for technical individuals, find out more about the model within their paper.
Vicuna
Vicuna, the brainchild of the Large Model Systems Organization, brings new ideas to the accessibility of Large Language Models (LLMs). Designed as an open-source chatbot, Vicuna finds its root in fine-tuning the LLaMA 2 model using user-generated conversations obtained via ShareGPT (a means to share OpenAI's GPT-3.5 and GPT-4 conversations). Its unique approach allows it to outperform other models such as LLaMA 1 and Stanford Alpaca (a fine-tuned version of LLaMA).
Trained on 7 and 13 billion parameters, Vicuna boasts exceptional fluency and context retention. The model is geared towards human-like conversions with fine-tuning data drawn from 370M tokens. Based on LLaMA 2, it employs the same transformer model with an auto-regressive function and makes use of 16K context-length versions using linear RoPE scaling.
The commitment to open-source is evident in Vicuna's accessible codebase and weight repo. While tailored for noncommercial use, Vicuna also offers instruct models to enhance its versatility. The model enjoys a vibrant developer and community-based involvement with more than 383 thousand downloads for version 1.3.
As far as relative performance and evaluation, it stands tall in the Hugging Face LLM chatbot leaderboard, boasting an impressive 1096 Arena Elo rating and a 7.12 out of 10 in MT-Bench grading. These scores overshadow LLaMA, its foundational model, in the realm of multi-turn question handling and dialogue optimization.
Vicuna's prowess extends to the more broad Open LLM leaderboard where its most performant 33B model achieves an impressive score of 65.21 through Eleuther evaluation.
Access to Vicuna and the datasets via Hugging Face.
Falcon
Developed by the Technology Innovation Institute under the Apache 2.0 license, the Falcon LLM is another powerful open-source LLM that brings a lot of promise in terms of innovation and precision. Trained on 40 billion parameters and an astounding 1 trillion tokens using 384 GPUs on AWS, Falcon makes use of the autoregressive decoder architecture type.
Setting itself apart, Falcon takes an unconventional route by prioritizing data quality over sheer volume. Leveraging a specialized data pipeline and custom coding, it harnesses the RefinedWeb Dataset, which stems from publicly available web data meticulously filtered and deduplicated. Also, it makes use of rotary positional embeddings (similar to LLaMa) and Multiquery and FlashAttention for attention.
With its instruct models for 7B and 40B parameters, Falcon offers adaptability for various use cases, including dialogues and chats. Using the EleutherAI Evaluation framework, the most perfomant falcon model based on the 40B parameter has a score of 63.47. Also, on the Chatbot Arena leaderboard, the Falcon 40B Instruct has a 5.17 out of 10 on the MT-Bench benchmark.
Yet, the Falcon LLM has its limitations as with any LLM. It's limited to a few languages - English, German, Spanish and French. Also, its training data sources introduce potential stereotypes and biases found on the web. Additionally, the lack of a detailed technical paper to show reliability, risk, and bias assessment make it essential to use carefully, especially in production or critical environment.
Access, fine-tune, and deploy the Falcon 40B model via Hugging Face.
MPT
MPT, or MosaicML Performance Transformer, stands as a differential open-source LLM that can push the boundaries of what LLMs can achieve. This Apache 2.0 licensed model has not only reached impressive heights in terms of performance but also emphasizes commercial usability.
Trained on Oracle Cloud's A100-40Gb and A100-80GB GPUs, MPT differentiates itself through a unique data pipeline approach. Unlike other models, MosiacML employed a mixture of data pipelines and EleutherAI's GPT-NeoX alongside a 20B tokenizer. The weights are freely available to the public via GitHub.
The MPT has a transformer model that makes use of 1 trillion tokens which contains both text and code. Its architecture consists of three finely tuned variants; MPT-7B-Instruct, MPT-7B-Chat, and MPT-7B-StoryWriter-65k+. Each variant caters to different applications, from instruction following to chatbot-like dialogue generation.
MosiacML's capabilities in model development shine through their toolset, Composter, LLM Foundry, LION Optimizer, and PyTorch FSDP, which were used to fine-tune MPT. The architecture of the MPT model underwent optimization to eliminate context length limits by incorporating Attention with Linear Biases (ALiBi).
You can fine-tune the model with other transformers and data pipelines via Hugging Face and train using the MosiacML platform. In addition, to access the training code for MosiacML foundation models (MPT-7B and MPT-30B, and their variants), make use of their GitHub. You can configure and fine-tune the MPT-7B via langchain and easily configure using typical notebooks such as Google Colab.
In terms of performance with other models, the most performant MPT LLM mode in terms of dialogue and chat - MPT-30B-chat - scored 1046 and 6.39 in Arena Elo rating and MT-bench score respectively, behind Vicuna-33B but ahead of Llama-2-13b-chat (Arena Elo rating). Also, the MPT-30B LLM model in the Open LLM leaderboard has a 61.21 average score behind the Falcon model. However, MPT is not intended for deployment without any finetuning and developers should make sure to place well-defined guardrails. Also, the model can sometimes produce factually incorrect output as with all LLM models.
StableLM
StableLM, designed and developed by the team popularly known for Stable Diffusion, makes an impressive show in the space of open-source LLMs with its impressive 3B and 7B parameter variants. Leveraging the SwiGLU activation function and trained on RefinedWeb and C4 data, this decoder-only transformer model makes use of rotary position embeddings and parallel attention and MLP residuals for a performance-driven design.
The model is open source under the CC BY-SA-4.0 license, making it accessible for both commercial and research endeavors.
At its alpha stage, the StableLM 7B model boasts an average score of 51.5, followed by the 3B alpha version at a score of 34.32 in the Open LLM dashboard. The performance and efficiencies are expected to increase as the Stability Team works on more parameters and checkpoints for more efficient and precise outputs.
StableLM's innovative training approach incorporates an experimental dataset of 1.5T tokens sourced from The Pile, pre-trained with varying context lengths. However, developers and hobbyists need to be mindful of potentially offensive content that could seep through the data-cleaning process.
Aside from their foundation models, Stabily had previously built a fine-tuned LLM model based on the LLaMA2 70B model with Stable Beluga which is trained on a Hugging Face transformers and 3 open-source data mix.
Check out the training code and deploying details for the 3B Model and 7B Model.
Harnessing Open-Source LLMs
Open-source LLMs are shaping the future of text generation and generative AI by opening up access to advanced language models (faster feedback), fostering innovation (open research), and enabling diverse applications across industries (diverse ideas). From LLaMA2 to MPT, these models bring new approaches and means to the LLM world. While these models exhibit remarkable capabilities, it's essential to know how to navigate their limitations - lower performance differences from proprietary LLMs, limited guardrails against bias, incorrect answers, and high computational cost.
As you explore these open-source LLMs, keep in mind that Klu.ai offers a solution to leverage proprietary LLMs like OpenAI's GPT-4, Anthropic's Claude 2.1, and Google's PaLM 2, among others, and open-source LLMs if hosted by Replicate, AWS, or HuggingFace. Klu.ai is API first in its approach.
By utilizing Klu, you can harness the power and capabilities of cutting-edge LLMs to build generative AI apps that work and transform your development pipeline.
The emergence of open-source large language models marks a new era where innovation, creativity, and progress in generative AI grows ever more collaborative and accessible - lighting a path towards an intelligent future we build together.