Mistral 7B is a 7.3 billion parameter language model that represents a significant advancement in large language model (LLM) capabilities. It outperforms the 13 billion parameter Llama 2 model on all tasks and surpasses the 34 billion parameter Llama 1 on many benchmarks. Mistral 7B is designed for both English language tasks and coding tasks, making it a versatile tool for a wide range of applications.
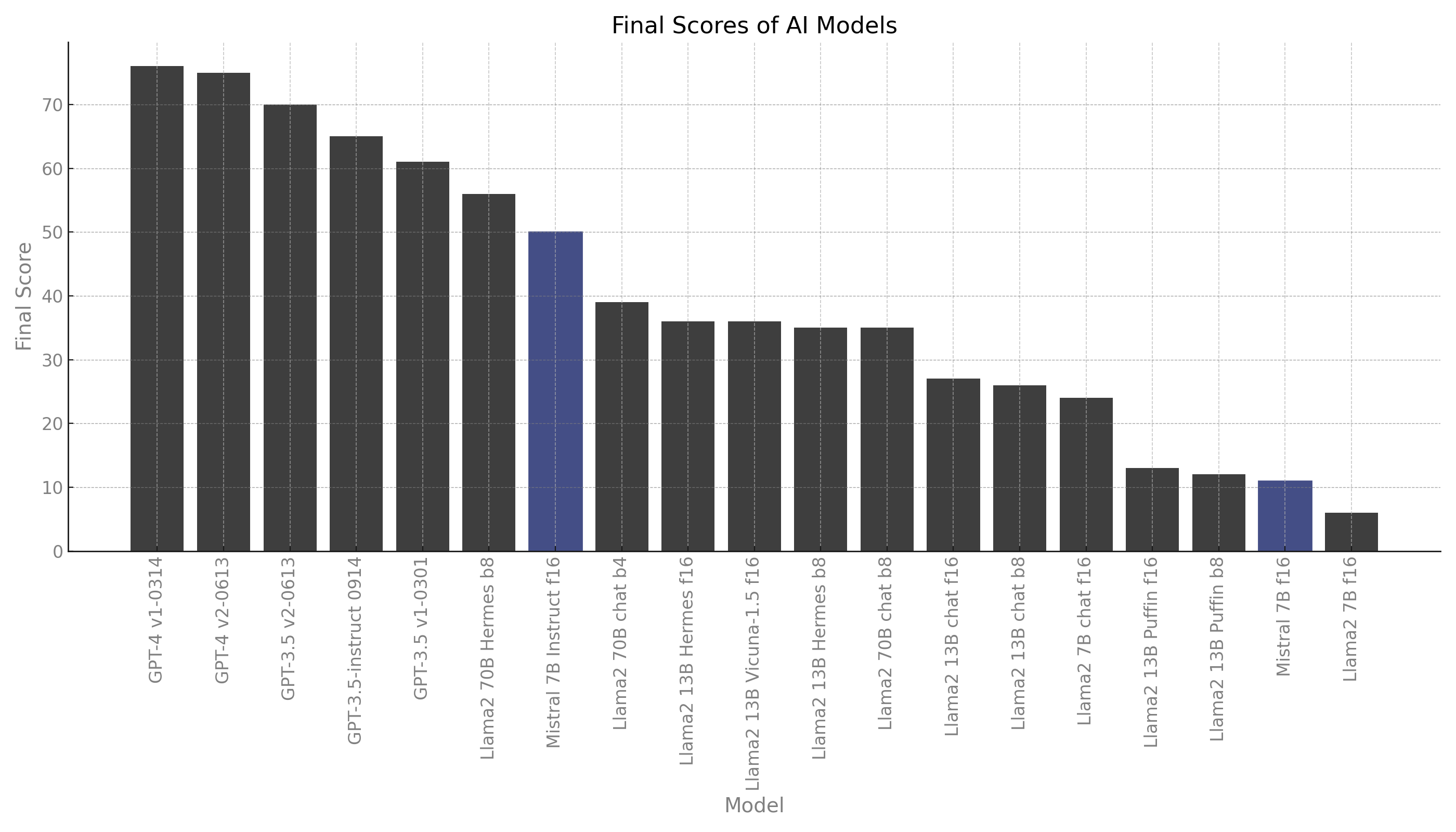
Benchmarking Mistral 7B against GPT-4, Llama 2 and its variants, and other leading models on real-world tasks shows exceptional performance for its size. However, without additional fine-tuning, the model is significantly worse on coding tasks compared to GPT-4.
| MODEL | CODE | CRM | DOCS | MARKETING | REASON | COST (USD) | SPEED |
|---|
| GPT-4 v1-0314 | 85 | 88 | 95 | 88 | 50 | 8.02 | 0.71 rps |
| GPT-4 v2-0613 | 85 | 83 | 95 | 88 | 50 | 8.02 | 0.75 rps |
| GPT-3.5 v2-0613 | 62 | 79 | 76 | 81 | 48 | 0.39 | 0.96 rps |
| GPT-3.5-instruct 0914 | 51 | 90 | 69 | 88 | 32 | 0.40 | 2.35 rps |
| GPT-3.5 v1-0301 | 38 | 75 | 67 | 82 | 37 | 0.40 | 1.76 rps |
| Llama2 70B Hermes b8 | 48 | 76 | 46 | 62 | 29 | 14.65 | 0.13 rps |
| Mistral 7B Instruct f16 | 36 | 77 | 61 | 62 | 18 | 0.47 | 2.63 rps |
| Llama2 70B chat b4 | 13 | 51 | 53 | 64 | 21 | 4.53 | 0.27 rps |
| Llama2 13B Vicuna-1.5 f16 | 36 | 25 | 27 | 77 | 36 | 0.87 | 1.39 rps |
| Llama2 13B Hermes f16 | 36 | 25 | 15 | 39 | 39 | 0.64 | 1.93 rps |
| Llama2 13B Hermes b8 | 31 | 18 | 23 | 56 | 39 | 4.08 | 0.30 rps |
| Llama2 70B chat b8 | 1 | 53 | 34 | 71 | 21 | 11.47 | 0.16 rps |
| Llama2 13B chat f16 | 0 | 38 | 15 | 75 | 8 | 0.72 | 1.71 rps |
| Llama2 13B chat b8 | 0 | 38 | 8 | 75 | 6 | 4.48 | 0.27 rps |
| Llama2 7B chat f16 | 7 | 33 | 23 | 38 | 15 | 0.77 | 1.58 rps |
| Llama2 13B Puffin f16 | 14 | 6 | 0 | 54 | 0 | 1.91 | 0.64 rps |
| Llama2 13B Puffin b8 | 16 | 3 | 0 | 47 | 0 | 8.88 | 0.14 rps |
| Mistral 7B f16 | 0 | 0 | 0 | 0 | 0 | 1.03 | 1.19 rps |
| Llama2 7B f16 | 0 | 0 | 4 | 32 | 0 | 1.21 | 1.01 rps |
What is Mistral 7B?
Mistral 7B is a 7.3 billion parameter language model developed by Mistral AI. It is designed to outperform other models of similar size, and even larger ones, in various benchmarks. For instance, it surpasses the 13 billion parameter Llama 2 model on all tasks and outperforms the 34 billion parameter Llama 1 on many benchmarks. It also approaches the performance of CodeLlama 7B on code tasks while remaining highly capable at English language tasks.
Mistral 7B uses two key mechanisms to achieve its performance. The first is Grouped-query Attention (GQA), which allows for faster inference times compared to standard full attention. The second is Sliding Window Attention (SWA), which gives Mistral 7B the ability to handle longer text sequences at a low cost.
The model is released under the Apache 2.0 license, allowing it to be used without restrictions. It can be deployed on any cloud (AWS/GCP/Azure), using vLLM inference server and skypilot, and can also be used on HuggingFace. It is designed for easy fine-tuning across various tasks, and a version of the model fine-tuned for chat, Mistral 7B Instruct, is provided as a demonstration.
Despite its impressive performance, Mistral 7B does have limitations. Its parameter count restricts the amount of knowledge it can store, especially when compared to larger models. It is also prone to common prompt injections, which are adversarial attacks that can manipulate the model's output.
To mitigate these issues, Mistral 7B provides a mechanism that leverages system prompting to enforce output constraints and perform fine-grained content moderation. This feature can be used to safeguard against certain types of content for high-stakes applications.
Mistral 7B can be used on a computer with a CPU or GPU, and there are two quantized methods, GGUF and GPTQ, that can be used to run the model.
How to Access Mistral 7B?
To access Mistral 7B with SkyPilot, you need to create a configuration file that tells SkyPilot how and where to deploy your inference server. This is done using a pre-built Docker container. Here's an example of a SkyPilot configuration:
envs:
MODEL_NAME: mistralai/Mistral-7B-v0.1
resources:
cloud: aws
accelerators: A10G:1
ports:
- 8000
run: |
docker run --gpus all -p 8000:8000 ghcr.io/mistralai/mistral-src/vllm:latest \
--host 0.0.0.0 \
--model MODEL_NAME \
--tensor-parallel-size SKYPILOT_NUM_GPUS_PER_NODE
Once these environment variables are set, you can use sky launch to launch the inference server with the name mistral-7b:
sky launch -c mistral-7b mistral-7b-v0.1.yaml --region us-east-1
When deployed this way, the model will be accessible to the whole world. You must secure it, either by exposing it exclusively on your private network (change the --host Docker option for that), by adding a load-balancer with an authentication mechanism in front of it, or by configuring your instance networking properly.
To easily retrieve the IP address of the deployed mistral-7b cluster you can use:
sky status --ip mistral-7b
You can then use curl to send a completion request:
IP=(sky status --ip cluster-name)
curl http://IP:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{ "model": "mistralai/Mistral-7B-v0.1", "prompt": "My favourite condiment is", "max_tokens": 25 }'
Please note that many cloud providers require you to explicitly request access to powerful GPU instances. You can read SkyPilot's guide on how to do this.
Mistral 7B can be accessed on platforms like HuggingFace, Vertex AI, Replicate, Sagemaker Jumpstart, and Baseten. It can be loaded and fine-tuned using the transformer library.
What are the key features of Mistral 7B?
Mistral 7B is a 7-billion-parameter language model developed by Mistral AI. It is designed to provide both efficiency and high performance, making it suitable for real-world applications that require quick responses. The model uses attention mechanisms like Grouped-Query Attention (GQA) for faster inference and reduced memory requirements during decoding, and Sliding Window Attention (SWA) for handling sequences of arbitrary length with reduced inference cost.
Mistral 7B has demonstrated superior performance across various benchmarks, outperforming even models with larger parameter counts. It excels in areas like mathematics, code generation, and reasoning. At the time of its release, Mistral 7B outperformed the best open source 13B model (Llama 2) in all evaluated benchmarks.
The model is designed for easy fine-tuning across various tasks. For instance, the Mistral 7B Instruct model is a version of the model fine-tuned for conversation and question answering.
Mistral 7B also has guardrails to enforce output constraints and performs fine-grained content moderation. It can be used as a content moderator to classify user prompts or generated answers into categories like illegal activities, hateful content, or unqualified advice.
The model is released under the Apache 2.0 license, allowing it to be used without restrictions. It can be accessed on platforms like HuggingFace, Vertex AI, Replicate, Sagemaker Jumpstart, and Baseten.
However, like many other large language models, Mistral 7B can hallucinate and is prone to common issues such as prompt injections. Its limited parameter count also restricts the amount of knowledge it can store, especially when compared to larger models.
What are the Use Cases of Mistral 7B?
Mistral-7B-Instruct is a language model that has been designed to excel in two primary domains: English language tasks and coding tasks. Its open-source nature allows developers and organizations to modify it to suit their unique needs and build custom AI applications without any restrictive barriers. This flexibility empowers a wide spectrum of applications, from sophisticated customer service chatbots to advanced code generation tools.
Some specific use cases of Mistral-7B include:
-
Automated Code Generation — Developers can automate code generation tasks using Mistral-7B-Instruct. It understands and generates code snippets, offering immense assistance in software development. This reduces manual coding effort and accelerates the development cycle.
-
Debugging Assistance — Mistral-7B-Instruct assists in debugging by understanding code logic, identifying errors, and recommending solutions, streamlining the debugging process.
-
Algorithm Optimization — Mistral-7B-Instruct can suggest algorithm optimizations, contributing to more efficient and faster software.
-
Text Summarization and Classification — Mistral-7B supports a variety of use cases, such as text summarization, classification, text completion, and code completion.
-
Chat Use Cases — Mistral AI has released a Mistral 7B Instruct model for chat use cases, fine-tuned using a variety of publicly available conversation datasets.
-
Knowledge Retrieval — Mistral 7B can be used for knowledge retrieval tasks, providing accurate and detailed responses to queries.
-
Mathematics Accuracy — Mistral 7B reports strengths in mathematics accuracy, providing comprehension for math logic.
-
Roleplay and Text Generation — Users have reported using Mistral 7B for roleplaying RPG settings and generating blocks of text.
-
Natural Language Processing (NLP) — Some users have used Mistral 7B for NLP tasks on documents to return JSON, finding it reliable enough for personal use.
It's important to note that the effectiveness of Mistral-7B can vary depending on the specific task and the fine-tuning applied to the model. Some users have reported excellent results in their specific use cases, while others have found it less effective for their needs.
How to Fine-tune Mistral 7B?
Fine-tuning Mistral 7B involves several steps, including setting up the environment, preparing the dataset, configuring the model, and training the model. Here's a step-by-step guide:
-
Set up the environment — Ensure you have access to a GPU environment with sufficient memory (at least 24GB GPU memory) and the necessary dependencies installed, such as PyTorch and Hugging Face Transformers library.
-
Prepare the dataset — Load a domain-specific dataset for fine-tuning. The dataset should be formatted according to the model's requirements. For Mistral 7B Instruct, prompts should be surrounded by [INST] and [/INST] tokens.
-
Load the base model and tokenizer — Load the Mistral 7B model and its tokenizer using the Hugging Face Transformers library.
-
Configure the training parameters — Set hyperparameters such as learning rate, batch size, and the number of training epochs. These parameters govern how the model adapts to your specific task and can be optimized to enhance performance.
-
Train the model — Train the fine-tuned model using the prepared dataset and configured training parameters. Monitor the training progress and adjust the parameters if necessary to improve the model's performance.
-
Evaluate the fine-tuned model — Test the fine-tuned model on a validation dataset to assess its performance on the target task. Adjust the training parameters and fine-tune the model further if needed.
-
Deploy the fine-tuned model — Once the fine-tuned model meets your performance criteria, deploy it for use in your application or service.
For a more detailed guide and code examples, refer to the resources available on Amazon SageMaker JumpStart, Hugging Face AutoTrain, and GitHub repositories that demonstrate fine-tuning Mistral 7B.
What are some common issues with Mistral 7B?
Mistral 7B, a 7.3 billion parameter language model developed by Mistral AI, has faced some criticisms and issues:
- Hallucination — Like many other large language models, Mistral 7B can generate content that is not based on facts or reality, which can lead to incorrect or misleading information.
- Prompt injections — Mistral 7B is prone to prompt injections, a type of adversarial attack that can manipulate the model's output.
- Limited knowledge storage — Due to its parameter count, Mistral 7B's knowledge storage capacity is limited compared to larger models, which can affect its performance in certain tasks.
- Lack of content moderation — Upon its release, Mistral 7B faced backlash for generating harmful content, such as detailed instructions on how to create a bomb, which raised concerns about responsible AI development. However, Mistral AI has since provided a mechanism to enforce output constraints and perform fine-grained content moderation.
Despite these issues, Mistral 7B has demonstrated superior performance across various benchmarks, outperforming even models with larger parameter counts in some cases.
How Does Mistral 7B Perform?
Mistral 7B outperforms Llama 2 13B across all metrics, and approaches the code performance of Code-Llama 7B without sacrificing performance on non-code benchmarks. It displays superior performance in code, mathematics, and reasoning benchmarks.
How Does Mistral 7B Promote Responsible AI Usage?
Mistral 7B emphasizes responsible AI usage through its system prompts, which allow users to enforce content constraints, ensuring safe and ethical content generation. Its ability to classify and moderate content makes it a valuable tool for maintaining quality and safety in various applications.