What is Grouped Query Attention (GQA)?
Grouped Query Attention simplifies how LLMs understand large amounts of text by bundling similar pieces together. This makes the model faster and smarter, as it can focus on groups of words at a time instead of each word individually.
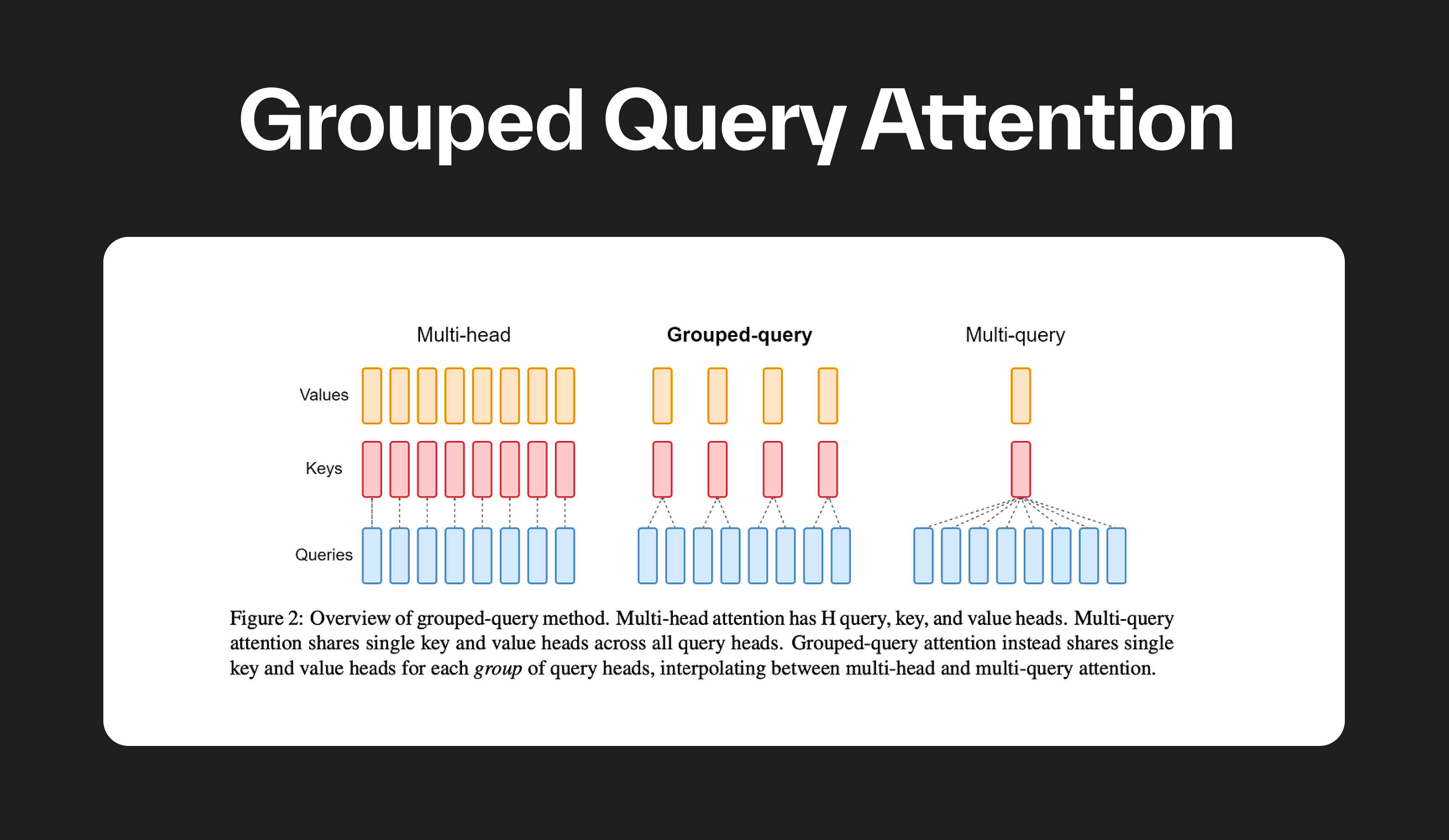
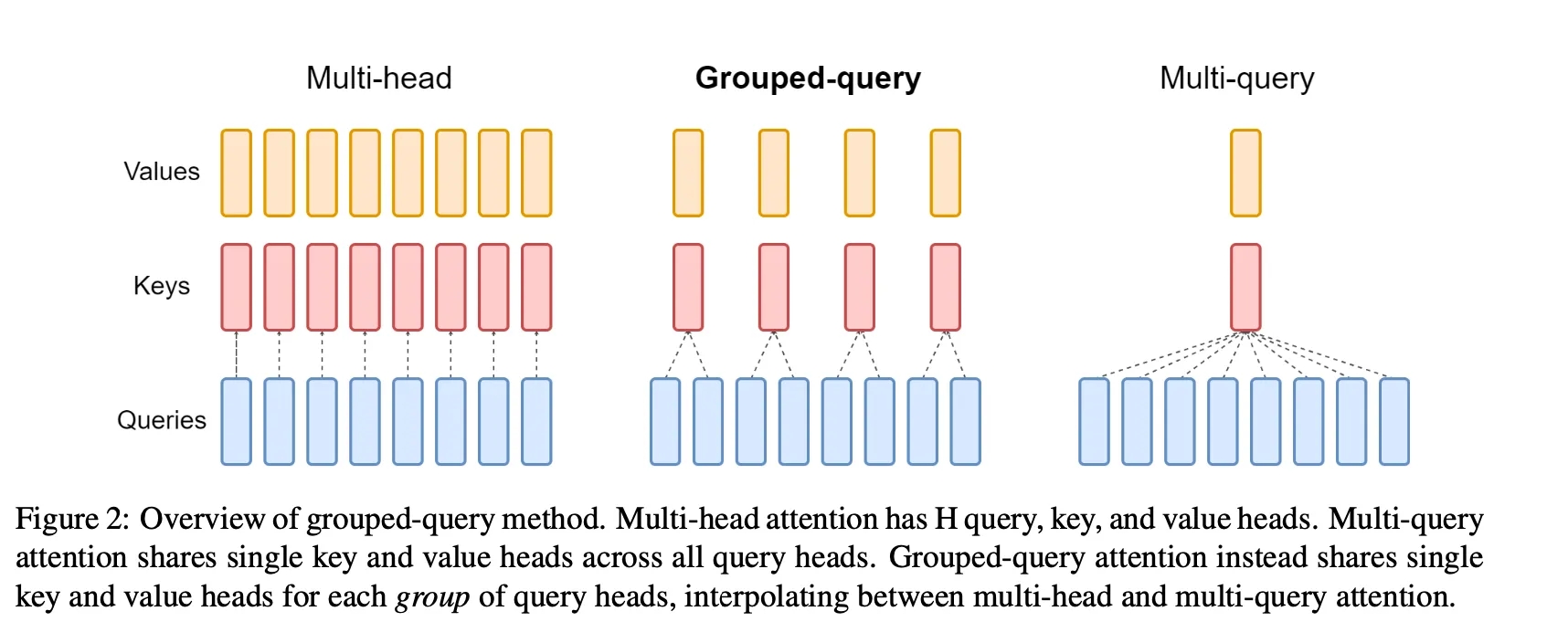
Grouped Query Attention (GQA) is a method that interpolates between multi-query attention (MQA) and multi-head attention (MHA) in Large Language Models (LLMs). It aims to achieve the quality of MHA while maintaining the speed of MQA.
GQA divides query heads into G groups, each of which shares a single key head and value head.
Key attributes of GQA include:
-
Interpolation — GQA is an intermediate approach between MQA and MHA, addressing the drawbacks of MQA, such as quality degradation and training instability.
-
Efficiency — GQA optimizes performance while maintaining quality by using an intermediate number of key-value heads.
-
Trade-off — GQA strikes a balance between the speed of MQA and the quality of MHA, providing a favorable trade-off.
GQA models the hierarchical relationships within queries by grouping query terms and paying various attention to different groups. This method helps to understand the semantic structure of complex queries and enhances the system's performance in retrieving relevant information.
It's a key component in many machine learning models for text understanding and information retrieval, particularly useful in search engines, question-answering systems, and document summarization. GQA helps these systems better understand the user's search intent, providing more accurate results.
GQA improves the efficiency of LLMs by reducing the memory bandwidth needed during decoder inference without sacrificing quality.
How does Grouped Query Attention work?
Grouped Query Attention (GQA) blends the speed of Multi-Query Attention (MQA) with the quality of Multi-Head Attention (MHA).
In transformer models, multi-head attention uses multiple parallel attention layers (heads), each with unique linear transformations for queries, keys, values, and outputs. Conversely, multi-query attention uses shared keys and values across different heads.
GQA can be thought of as a way to optimize the attention mechanism in transformer-based models. Instead of computing attention for each query independently, GQA groups queries together and computes their attention jointly. This reduces the number of attention computations, leading to faster inference times.
However, while MQA drastically speeds up decoder inference, it can lead to quality degradation. To address this, GQA was introduced as a generalization of MQA, using an intermediate number of key-value heads, which is more than one but less than the number of query heads.
In GQA, query heads are divided into groups, each of which shares a single key head and value head. This approach allows GQA to interpolate between multi-head and multi-query attention, achieving a balance between quality and speed. For instance, GQA with a single group (and therefore a single key and value head) is equivalent to MQA, while GQA with groups equal to the number of heads is equivalent to MHA.
The GQA method has been applied to speed up inference on large language models without significantly sacrificing quality. It's a promising technique for improving the efficiency of transformer models, particularly in the context of generative AI.
What are some common methods for implementing Grouped Query Attention?
Common methods for implementing Grouped Query Attention (GQA) include:
-
Grouping queries based on similarity — One popular method for implementing GQA is to group queries based on their similarity. This involves computing a similarity metric between queries and then assigning them to groups accordingly.
-
Dividing query heads into groups — In GQA, query heads are divided into groups, each of which shares a single key head and value head. This approach allows GQA to interpolate between multi-head and multi-query attention, achieving a balance between quality and speed.
-
Using an intermediate number of key-value heads — GQA strikes a balance between multi-query attention (MQA) and multi-head attention (MHA) by using an intermediate number of key-value heads, which is more than one but less than the number of query heads.
-
Repeating key-value pairs for computational efficiency — In GQA, key-value pairs are repeated to optimize performance while maintaining quality. This is achieved by repeating key-value pairs n_rep times, where n_rep corresponds to the number of query heads that share the same key-value pair.
These methods can be combined and adapted to suit the specific requirements of a given task or model architecture.
What are some benefits of Grouped Query Attention?
Benefits of Grouped Query Attention (GQA) include:
-
Quality — GQA achieves a quality close to multi-head attention (MHA) by interpolating between multi-query attention (MQA) and MHA, striking a balance between the two.
-
Speed — GQA maintains a speed comparable to MQA, which is faster than MHA, by using an intermediate number of key-value heads.
-
Reduced Computational Complexity — GQA can significantly reduce the computational complexity of large language models, leading to faster inference times.
-
Multi-GPU Parallelism — GQA allows for multi-GPU parallelism, enabling more efficient use of computational resources.
-
Low Memory Usage — GQA combines the low memory usage of MQA with the quality of MHA, making it suitable for large-scale models with memory constraints.
What are some challenges associated with Grouped Query Attention?
Grouped Query Attention (GQA) is a technique used in large language models to speed up the inference time by grouping queries together and computing their attention collectively. It is an interpolation of multi-query and multi-head attention that achieves quality close to multi-head at comparable speed to multi-query attention. However, there are several challenges associated with GQA:
-
Quality Degradation and Training Instability — GQA is an evolution of Multi-Query Attention (MQA), which uses multiple query heads but a single key and value head. While MQA speeds up decoder inference, it can lead to quality degradation and training instability. GQA attempts to mitigate this by using an intermediate number of key-value heads (more than one but fewer than the query heads), but the balance between speed and quality is a challenge.
-
Memory Bandwidth Overhead — Autoregressive decoder inference is a severe bottleneck for Transformer models due to the memory bandwidth overhead from loading decoder weights and all attention keys and values at every decoding step. GQA attempts to address this by dividing query heads into groups, each of which shares a single key head and value head. However, managing this memory bandwidth overhead is a significant challenge.
-
Complexity of Implementation — Implementing GQA within the context of an autoregressive decoder using a Transformer model can be complex. It involves repeating key-value pairs for computational efficiency, managing cached key-value pairs, and performing scaled dot-product attention computation.
-
Group Division — The input nodes are divided into several groups and attention is calculated only within that local block. If the total number of nodes cannot be divided by the group length, zero-padded nodes are added to match the length. This division and management of groups add to the complexity of the GQA implementation.
-
Hyperparameter Tuning — Achieving optimal performance with GQA requires careful tuning of hyperparameters. For instance, the number of groups into which the query heads are divided can significantly impact the model's performance and efficiency.
Despite these challenges, GQA is a promising technique for improving the efficiency of large language models, and ongoing research is addressing these issues to further optimize its performance.
What are some future directions for Grouped Query Attention research?
Future research directions for Grouped Query Attention (GQA) could include:
-
Exploring Different Grouping Strategies — The current implementation of GQA divides query heads into groups, each of which shares a single key head and value head. Future research could explore different strategies for grouping the query heads, potentially based on the nature of the data or task at hand.
-
Combining Keys, Queries, and Values in Self-Attention — Some research has shown outstanding performances when combining keys and queries. It remains a question of whether it is beneficial to combine keys, queries, and values in self-attention, which could be an interesting direction for GQA research.
-
Applying GQA to Different Tasks — GQA has been applied to speed up inference on large language models. Future research could explore the application of GQA to other tasks, such as image classification, object detection, semantic segmentation, video understanding, image generation, 3D vision, multi-modal tasks, and self-supervised learning.
-
Improving Efficiency with Sparse Attention Patterns — Some research has proposed learning dynamic sparse attention patterns that avoid allocating computation and memory to attend to content unrelated to the query of interest. This could be an interesting direction for improving the efficiency of GQA.
-
Personalized Query Understanding — As the field of query understanding evolves, there is a growing interest in personalized query understanding. Future research could explore how GQA can be adapted to better understand and respond to individual user queries.
-
Content-Selection and Content-Plan Generation — A novel attention mechanism called Grouped-Attention has been proposed for content-selection and content-plan generation in data-to-text generation models. This could be an interesting direction for GQA research.
These directions could potentially lead to improvements in the quality and efficiency of GQA, as well as its applicability to a wider range of tasks.