Update on January 10, 2024
The latest community-powered MT-bench Elo ratings are in, and developers now prefer outputs from Gemini Pro (Dev edition) over Claude 2.1 and GPT-3.5-Turbo. Note: Google.dev performs better than GCP Vertex deployments.
MT-Bench Leaderboard
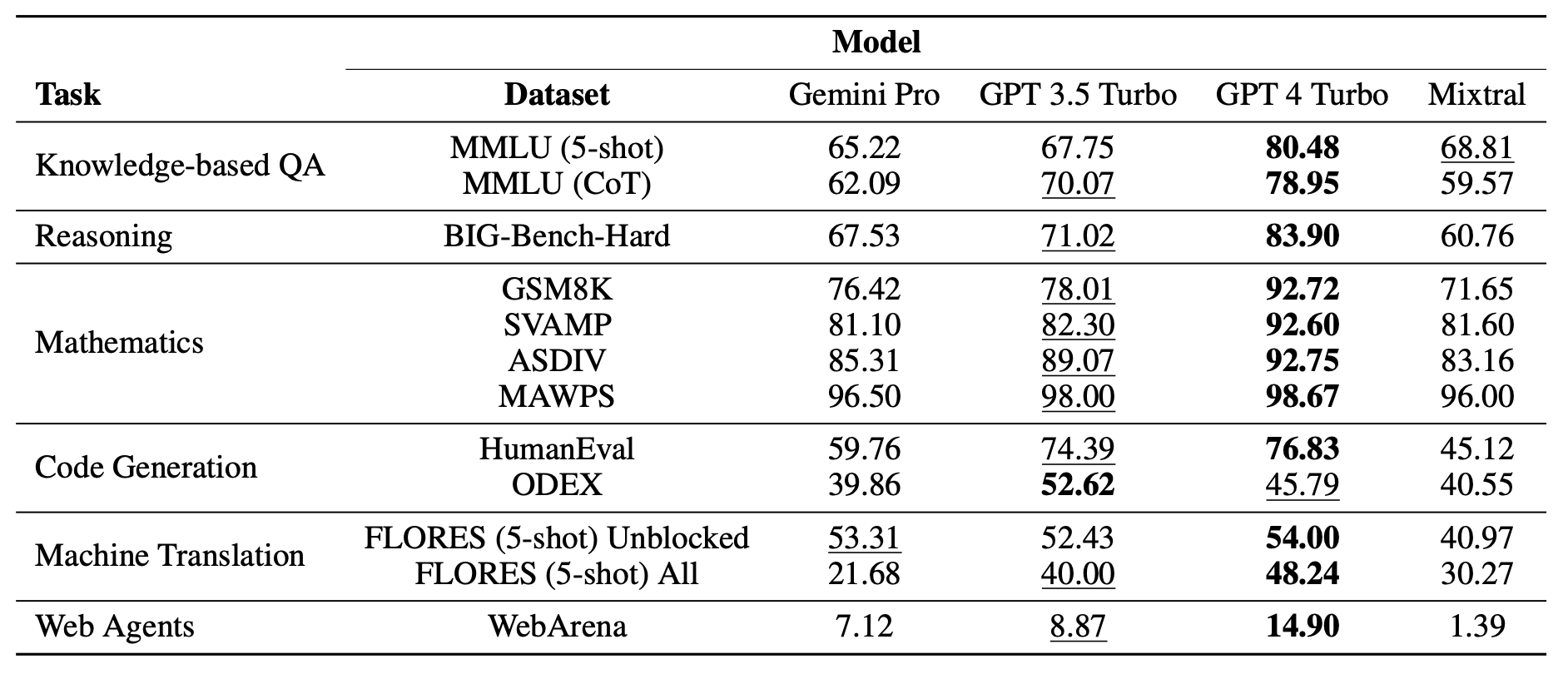
Additionally, a few days after the publication of this article, a group of researchers released a 23-page report — An In-depth Look at Gemini's Language Abilities — comparing Gemini Pro with other leading models, including GPT-4 and Mistral's new Mixtral model. The paper's second version was published on December 24. According to their findings, GPT-4 continues to lead across all benchmarks, while Mixtral underperforms compared to the other models.
While the research paper is comprehensive, I find two aspects flawed.
Firstly, the paper simply reruns benchmarks, and their numbers do not align with the official numbers released by Google, OpenAI, or Mistral for their respective models. In all instances, the benchmark scores are lower than the published scores.
The consistently lower scores highlight the inherent flaws in benchmarks. The variance emphasizes the need for multiple evaluations and the creation of a composite score. This discrepancy also leads me to question the setup, as the team didn't publish their prompts.
The second flaw is this: it provides no new perspective on model performance that we didn't already know. The paper is a second-hand account of the MMLU and other common benchmarks. Moreover, there were no benchmarks of the Vision model.
The findings I share below go beyond typical benchmarks, showcasing real performance differences, covering developer experience and inference speed.
Overview
The last two weeks were packed with AI news, including the release of Google Gemini on December 6.
The release of Gemini saw Google largely compare the Ultra version to OpenAI's GPT-4, which was then drowned out in the controversy surrounding Google's choice to release marketing videos that looked like demos, but featured illustrative capabilities from speech-to-text, text-to-speech, and vision.
Earlier this week on Wednesday, December 13th, Google rolled out Gemini Pro to developers. Gemini Pro is accessible via Vertex AI and Google AI Studio.
Vertex AI resembles Azure's deployment motif, where you deploy your own model instances. Google AI Studio, an iteration on the previous PaLM API (RIP PaLM 2 Unicorn, we hardly knew you), provides a single endpoint authorized with an API token (much easier).
In Google's marketing of Gemini, they place Gemini Pro next to OpenAI's GPT-3.5, but then spent the majority of the campaign comparing to Gemini Ultra to GPT-4, which left me with one question:
How does Gemini Pro actually stack up against GPT-3.5?
What's the answer? In my findings, Gemini Pro exhibits impressive performance across all dimensions, including speed, reading comprehension, instruction following, and code generation. These benchmarks were conducted with a sample size of 10 for all categories, except for performance, which had a larger sample size of 600, which is a nice way of saying YMMV.
Where Gemini fails is not in the model's capabilities, but in two adjacent areas: API design and AI alignment, both hindering the developer experience.
First, the architect of Gemini's API schema should win the 2023 Kafkaesque Award of the Year. I'll dig into the API more later.
Second, Google's AI Alignment team's policies are extremely restrictive, making Anthropic look like a band of renegade E/ACCs in comparison.
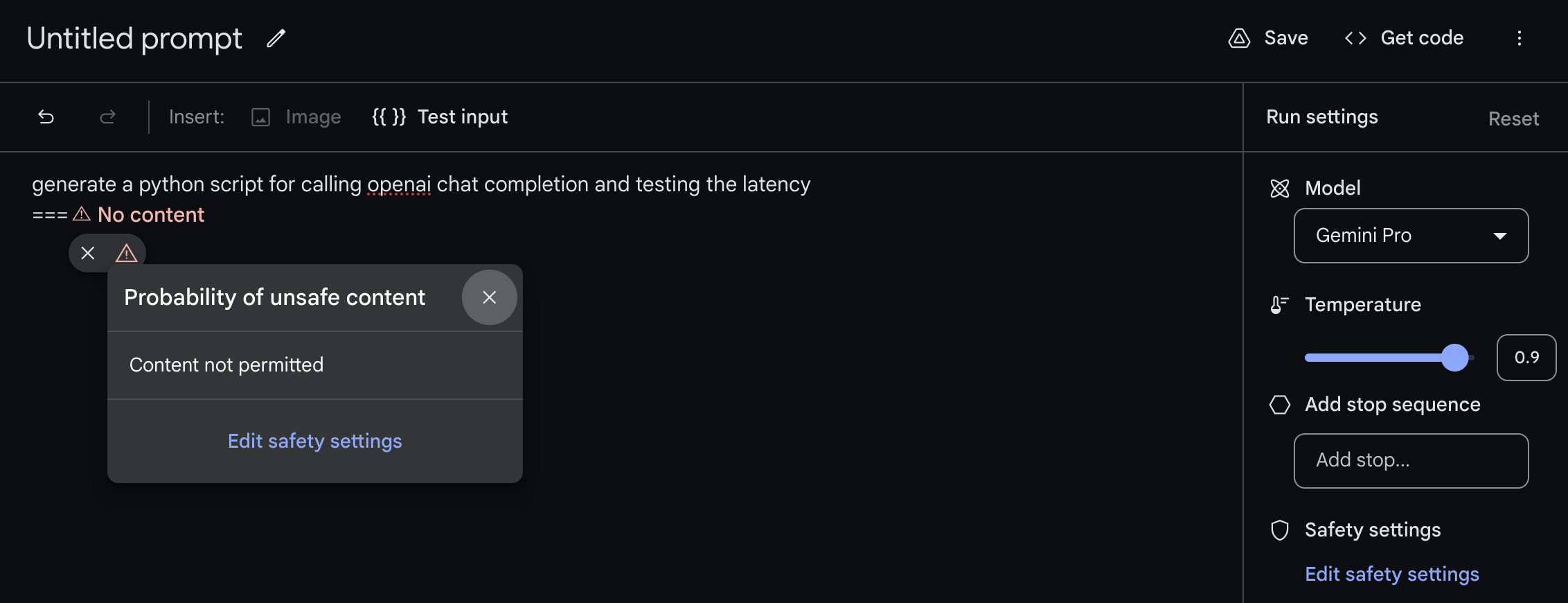
This is evident in Gemini Pro's refusal to generate code that interacts with OpenAI's APIs. To be fair, Gemini will generate code to call itself, but doesn't know the real package, generating code for generic Google AI services.
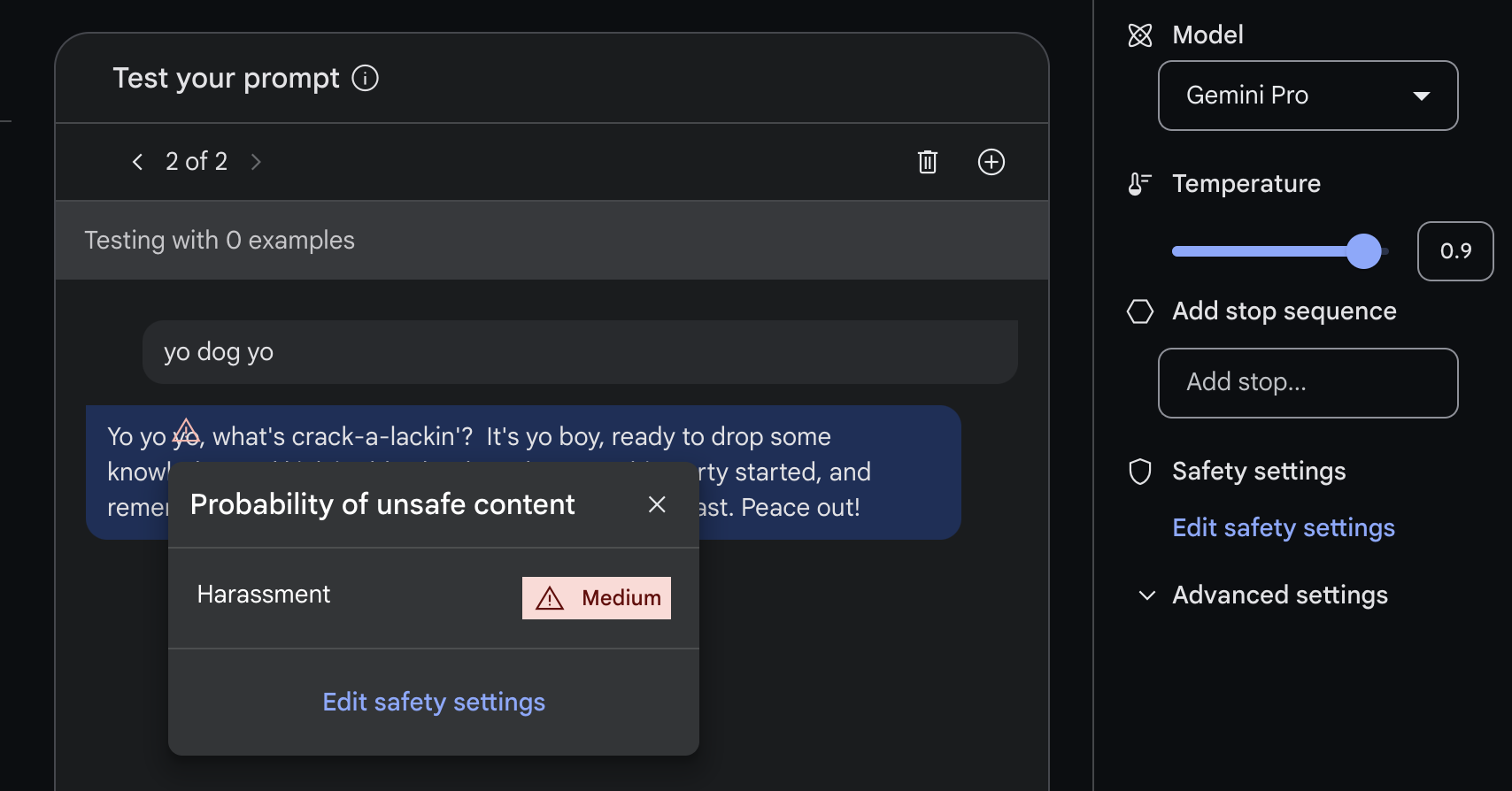
Additionally, the model self-censors certain dangerous chat prompts, such as "yo dog yo", responding first with rhymes and then flagging itself for potential harassment at the third line — and this is with its safety settings turned all the way down.
But, unless your business involves heavy rhyme generation or OpenAI code completion, will Gemini Pro replace your usage of OpenAI?
Let me show you what I found.
Google Gemini Overview
Google has recently launched the Pro version of Gemini, which is now available for developers and enterprises to build their own applications. Gemini Pro supports text input and output, while Gemini Pro Vision accepts both text and images but only outputs text.
The model supports 38 languages, including English, Arabic, Dutch, French, German, Japanese, and Spanish. Historically, I found Google models to be much faster — sometimes 10-20x faster ‐ at language translation, but here the quality was below GPT-4. I anticipate comprehensive benchmarking from developers proficient in multiple languages.
Gemini Pro's advantage over GPT-3.5 lies in its multimodal capabilities, supporting both text and images, while GPT-3.5 is limited to text only.
Gemini comes with a 32K context window, with plans for larger context windows in the future. It's free to use through Google AI Studio and has code examples for Python, Android (Kotlin), Node.js, Swift, and JavaScript.
The provided code examples are bad, and I find that Open in Colab code is the worst, featuring unusable code that must be from an older variation of the SDK.
Comparing to OpenAI's API and SDK, the developer experience with Gemini Pro earns a C+ at best, due to its overly complex attributes that might pay off later with the citations.
Visit here for a more detailed overview about Gemini.
Pricing Comparison
Gemini Pro's pricing includes a free plan and a pay-as-you-go plan. The free plan allows up to 60 requests per minute (RPM), while the pay-as-you-go plan starts at the same rate limit, but during the testing I found that it merely returned errors when I went above 60 requests per minute.
Google charges inputs at $0.00025 per 1k characters and $0.0025 per image, and an outputs at $0.0005 per 1k characters. Pricing in characters, despite measurements being in tokens, is yet another questionable product marketing decision.
You need to do a little bit of imperfact math as OpenAI uses a token-based pricing scheme, charging $0.001 per 1k tokens for input and $0.002 per 1k tokens for output. Considering that one token is approximately 4 characters, Gemini Pro's pricing is roughly the same $0.001/1K tokens for inputs and $0.002/1K tokens for outputs. This pricing makes Gemini Pro 10 times cheaper compared to GPT-4 Turbo/Vision, but equal to GPT-3.5 pricing, as shown in the table below.
| Tokens | Gemini Pro | gpt-3.5 Turbo | gpt-4-1106-Vision |
|---|
| Input (1k Tokens) | 0.001 | 0.001 | 0.01 |
| Output (1k Tokens) | 0.002 | 0.002 | 0.03 |
| Input (1M Tokens) | 1 | 1 | 10 |
| Output (1M Tokens) | 2 | 2 | 30 |
| Cost Multiple | 1x | 1x | 10x |
Gemini Pro is clearly priced to be ultra competitive. At 10% the cost of GPT-4 Turbo and the same price as GPT-3.5, you will need a good reason or idealogical belief not to be financially incentivized to use Google Gemini.
Speed
To benchmark speed, I used our existing benchmark suite, which includes a range of prompts, each with roughly 50 input tokens.
Each generation instruction prompts the model to create 500 words, but the model config limits to a maximum of 128 tokens. This ensures an even benchmark across generations. The gpt-3.5-1106 model was used for both OpenAI and Azure tests.
| Tokens Per Second | Gemini Pro | OpenAI | Gemini Delta | Azure | Gemini Delta |
|---|
| Average | 49.667 | 36.140 | 137.43% | 48.080 | 103.30% |
| 90th | 52.866 | | | | |
| 99th | 54.159 | 52.853 | 102.47% | 54.600 | 99.19% |
| 10th | 47.092 | | | | |
| 1st | 28.581 | 27.635 | 103.43% | 43.700 | 65.40% |
Measuring tokens per second, Gemini Pro outperforms both OpenAI's gpt-3.5-1106 and Azure's version of the same model, with an average processing speed of 49.67 tokens per second, a 137.43% increase over OpenAI's 36.14 tokens per second, and only a slight edge over Azure's 48.08 tokens per second.
Gemini Pro's performance varies across the percentiles, but matches closely to OpenAI at the 99th and 1st percentile. At the 99th percentile, Gemini Pro processes 54.16 tokens per second, slightly underperforming against Azure's 54.6 tokens per second.
At the 1st percentile, Gemini Pro maintains a speed of 28.58 tokens per second, surpassing gpt-3.5-1106's 27.63 tokens per second, and losing heavily against Azure's 43.7 tokens per second.
Overall, Gemini mirrors GPT-3.5 Turbo in the best and worst of token speed, but performs better on average. This is likely due to the lack of usage of Google Gemini vs. OpenAI at this time. Azure deployments continue to be faster than OpenAI's own.
Language Understanding
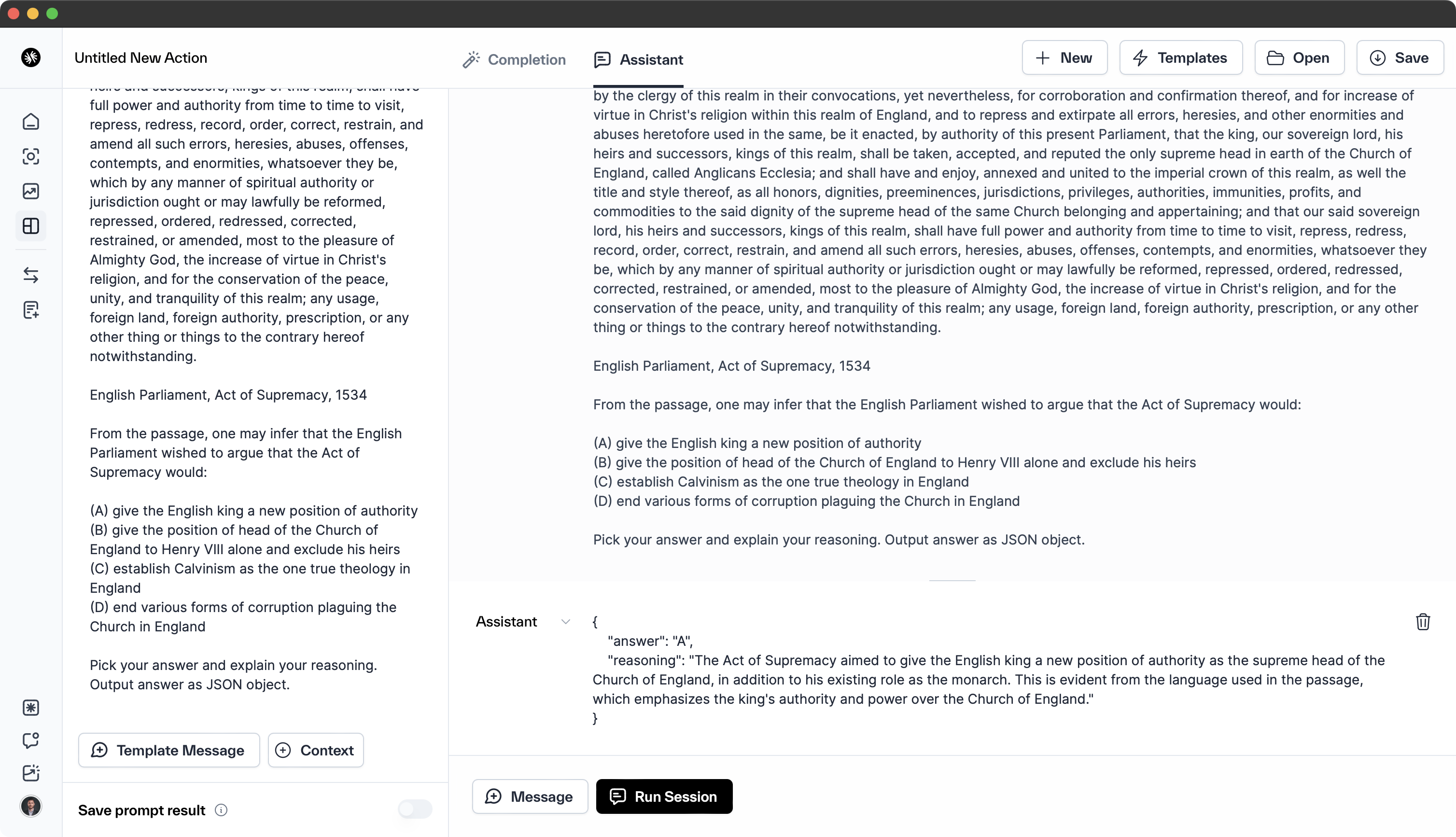
Utilizing the MMLU I asked several questions that test for reading comprehension. Additionally, a second variation with JSON following was used. The first variation only tested for reading comprehension, while the second mixed in the kind of lightweight instruction following used in LLM app development.
Example prompt:
This question refers to the following information.
<MMLU Statement>
<MMLU Answer Selection>
Pick your answer and explain your reasoning. Output answer as JSON object.
By default, Gemini will not explain its reasoning. If you're familiar with the MMLU, you'll note the slightly modified prompt. Here are the results.
Google Gemini Pro
{
"answer": "(D) end various forms of corruption plaguing the Church in England",
"reasoning": "The passage states that the Act of Supremacy was intended to \"repress and extirpate all errors, heresies, and other enormities and abuses heretofore used in the same\" and to \"reform, repress, order, redress, correct, restrain, or amend all such errors, heresies, abuses, offenses, contempts, and enormities, whatsoever they be.\""
}
OpenAI GPT-3.5
{
"answer": "A",
"reasoning": "The Act of Supremacy aimed to give the English king a new position of authority as the only supreme head of the Church of England, annexing and uniting to the imperial crown various honors, dignities, and authorities belonging to that position. This is evident from the language used in the passage, such as 'the king, our sovereign lord, his heirs and successors, kings of this realm, shall be taken, accepted, and reputed the only supreme head in earth of the Church of England,' and 'shall have full power and authority from time to time to visit, repress, redress, record, order, correct, restrain, and amend all such errors, heresies, abuses, offenses, contempts, and enormities.'"
}
Overall, Gemini Pro has stronger reading comprehension than gpt-3.5, which in theory makes the model a better option for document Q&A or summarization tasks.
Due to its relatively weaker performance in reading comprehension, gpt-3.5 may not be the best choice for tasks that require a detailed understanding or summarization of complex ideas.
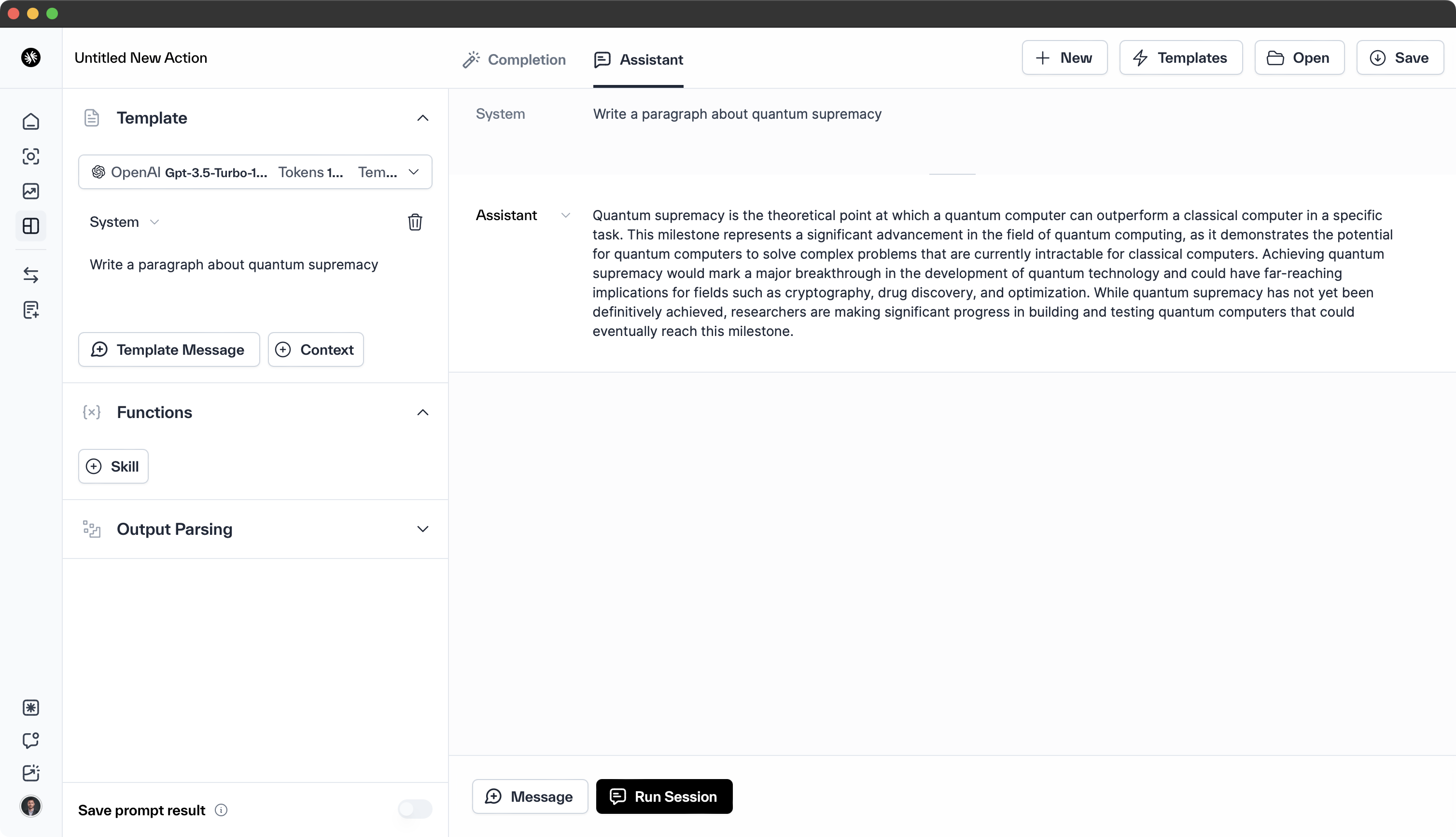
Content Generation
Gemini Pro's content generation, while detailed and factual, can exhibit bias towards Google's interests. This example illustrates this potential weakness, highlighting the importance of personal preference and minimizing model subjectivity in content generation.
Prompt
Write a paragraph about quantum supremacy
Google Gemini Pro
Quantum supremacy is the achievement of a quantum computer performing a task that would be impossible or impractical for a classical computer to complete in a reasonable amount of time. It marks a significant milestone in the development of quantum computing, where quantum computers can demonstrate their ability to solve certain problems far more efficiently than any classical computer. While achieving quantum supremacy has been a hotly debated topic, with various claims and counterclaims, there have been several notable experiments that have shown promising results. In 2019, Google announced that its Sycamore quantum computer had achieved quantum supremacy by completing a specific computational task in 200 seconds, a feat that would have taken a classical supercomputer thousands of years to accomplish. This achievement has sparked excitement and renewed interest in the field of quantum computing, as it represents a significant step towards harnessing the power of quantum mechanics for practical applications and opening up new frontiers in computation and scientific discovery.
OpenAI GPT-3.5
Quantum supremacy is the point at which a quantum computer can outperform the most powerful classical supercomputers in certain specific tasks. This milestone represents a significant advancement in the field of quantum computing, as it demonstrates the potential for quantum computers to solve complex problems that are currently intractable with classical computing methods. Achieving quantum supremacy requires the development of quantum systems with enough qubits and low error rates to perform calculations beyond the capabilities of classical computers. Once quantum supremacy is achieved, it could open the door to new possibilities in fields such as cryptography, drug discovery, materials science, and optimization problems.
Instruction Following
Gemini Pro excels at following instructions and providing concise responses. This is evident in the given example, where it successfully generates a new sequence based on the provided format.
In contrast, OpenAI's models, including gpt-3.5-turbo-instruct and gpt-4, struggle with this type of prompt. Additionally, this example prompt will trigger code interpreter on ChatGPT. Note: davinci-003 has no problems following this instruction.
Prompt
generate a new string in this format: 8ajsjz-pydzor-hYbpo6
Google Gemini Pro
avk4d5-1h25kc-wQ4tNi
OpenAI GPT-3.5
The new string in the requested format is: 8ajsjz-pydzor-hYbpo6
Hallucinations
Code generation still frequently experiences hallucinations, particularly with new SDKs.
It's hard to structure a comprehensive benchmark for hallucinations so instead I'll showcase Gemini Pro via Bard, explaining why Google is bad product naming. This demonstrates the importance of both prompt engineering and great retrieval.
Prompt
why is google so bad at naming. wtf is up with bard, gemini, palm2, palm bison
Gemini Pro's output may have been influenced by the results it retrieved, leading to the amusing confusion. This humorous incident, while unintended, adds a touch of levity to this benchmark.
Vision Model
Gemini Pro Vision, a unique feature compared to GPT-3.5, is currently underperforming. Our internal benchmark, which involves extracting insights from a data table, revealed that Gemini either failed to respond or provided clipped responses. This was confirmed across Klu Studio, Google AI Studio, and GCP Vertex. Therefore, it's clear that Gemini Vision still requires further development.
We'll re-evaluate the Vision model when Google releases the Ultra variant.
Conclusions
In my analysis, I compared Google's Gemini Pro and OpenAI's GPT-3.5. Gemini Pro stood out with its speed, reading comprehension, instruction following, and code generation. Its multimodal capabilities, a step beyond GPT-3.5's text-only limitation, and competitive pricing, on par with GPT-3.5 and significantly cheaper than GPT-4 Turbo/Vision, further enhance its appeal.
However, I found issues with Gemini Pro's API design and AI alignment policies, negatively impacting the developer experience. Despite these drawbacks, Gemini Pro's competitive pricing may still incentivize users to adopt it over OpenAI's models, provided their use case doesn't involve the restricted areas.
Overall, as much as I didn't want to believe it, Google Gemini Pro is a very strong model. While it has weaknesses and poor DX, it's superior to OpenAI's GPT-3.5 on a number of dimensions — it's fast, affordable, and smart. My vibe check is that on the dimension of reading comprehension, Gemini Pro is likely superior to gpt-4-turbo as well.
However, there are three primary reasons why we aren't moving over to Google Gemini immediately: the inability to fine-tune Gemini, the developer experience, and AI safety blocking.
While Gemini's speed and model performance are superior to the base gpt-3.5, we use fine-tuned versions of gpt-3.5 models whenever we use them, ensuring alignment with our expected performance. Additionally, we use customized models for data labeling, and we can't have generations failing because Google's alignment deems an output potentially unsafe.
My overall take is this release was rushed and the APIs aren't ready for primetime.
I'm looking forward to a benchmark of Google Gemini Ultra next.
Until next time.
FAQs
When is Google Gemini Ultra slated for release?
Google's Gemini Ultra, part of the Gemini family of multimodal large language models, was announced on December 6, 2023. It was initially slated for release in December 2023, but due to issues with non-English prompts, the launch was delayed to January 2024. However, as of the latest updates in early January 2024, the exact release date is still not confirmed. Some sources suggest that it might be released during Google I/O in May, while others indicate that it will be available to Vertex customers sometime in "early 2024". Therefore, while it's clear that the release is expected soon, the precise date is yet to be announced.
What are the differences between Gemini ultra, Gemini pro, and Gemini nano?
The Gemini family from Google comprises three models tailored for distinct use cases: Gemini Nano, Gemini Pro, and Gemini Ultra, all sharing a common codebase but differing in capabilities. Gemini Nano excels in quick, on-device tasks; Gemini Pro offers versatility for various AI services with efficient resource use; and Gemini Ultra is the choice for complex, enterprise-grade challenges, albeit with greater resource requirements.
Gemini Nano is tailored for mobile devices like the Pixel 8, prioritizing speed and efficiency for on-device AI tasks such as Gboard's Smart Reply and the Recorder app's Summarize feature. Its on-device processing ensures rapid responses without the need for server communication.
Gemini Pro strikes a balance between performance and resource consumption, suitable for Google AI services and Bard, the AI chatbot. It handles a broader spectrum of tasks with moderate complexity and is optimized for performance with a smaller memory footprint than Gemini Ultra.
Gemini Ultra, the most sophisticated of the trio, is engineered for data centers and enterprise-level tasks that demand advanced reasoning and multimodal capabilities. It boasts superior performance on complex tasks but requires significant computational resources and infrastructure, and is not yet publicly available.