January 10, 2024 Update
Mistral released an API-only, experimental variant of Mixtral, simply titled Mistral Medium &mdas h; while no model data or facts have been shared, we now have benchmark data showing developers prefer Mistral Medium outputs over all Anthropic models.
MT-Bench Leaderboard
What is the Mistral "Mixtral" 8x7B 32k?
The Mistral "Mixtral" 8x7B 32k model is a state-of-the-art LLM developed by Mistral AI, designed as a Sparse Mixture of Experts (SMoE) model. Mixtral employs a sparse mixture-of-experts network, functioning as a decoder-only model.
The model uses a feedforward block that selects from 8 unique parameter groups, and a router network determines two groups to process each token, merging their outputs. This approach allows Mixtral to maintain a high parameter count (46.7B total) while optimizing for cost and latency, using a per-token efficiency equivalent to a 12.9B model.
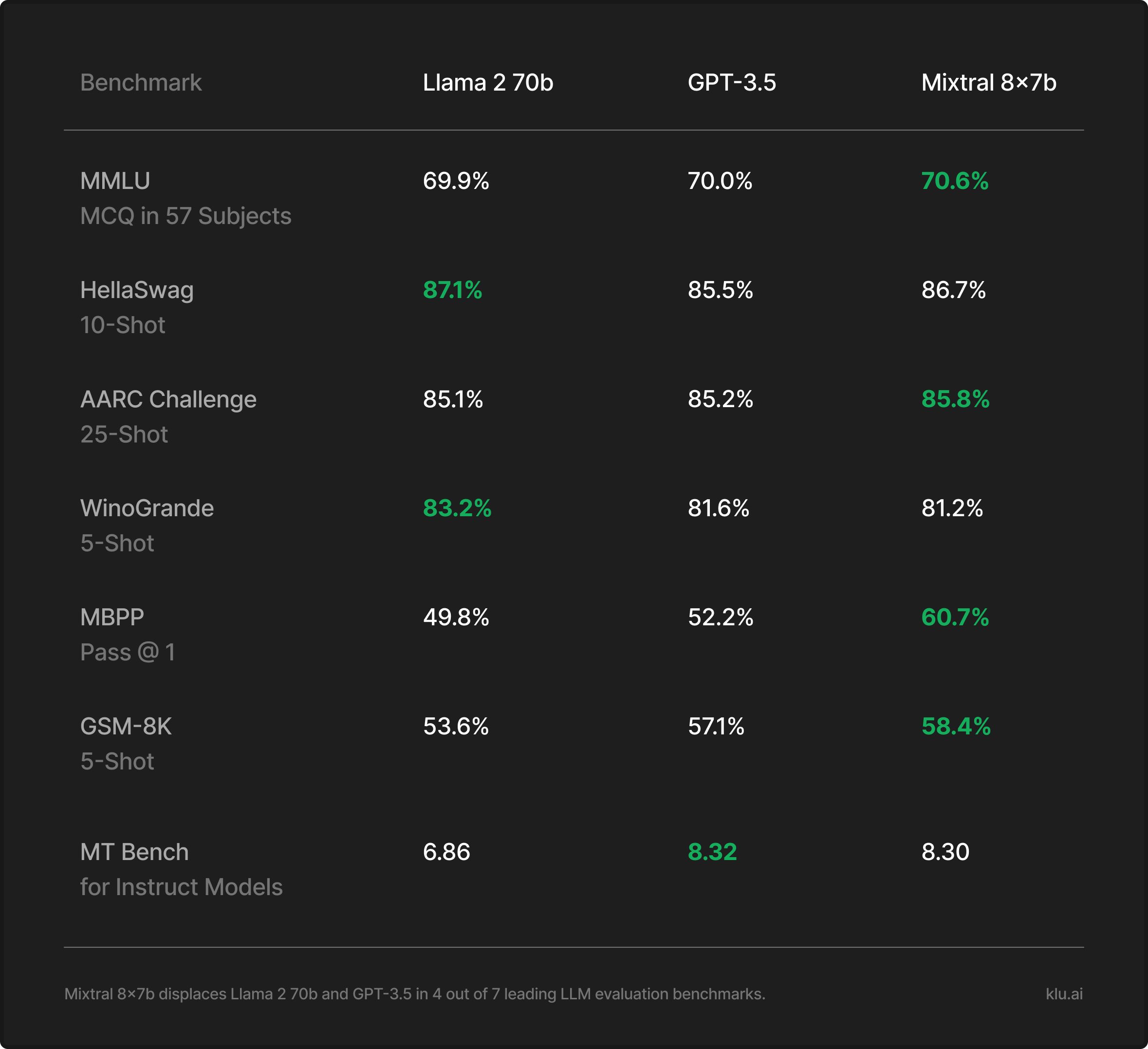
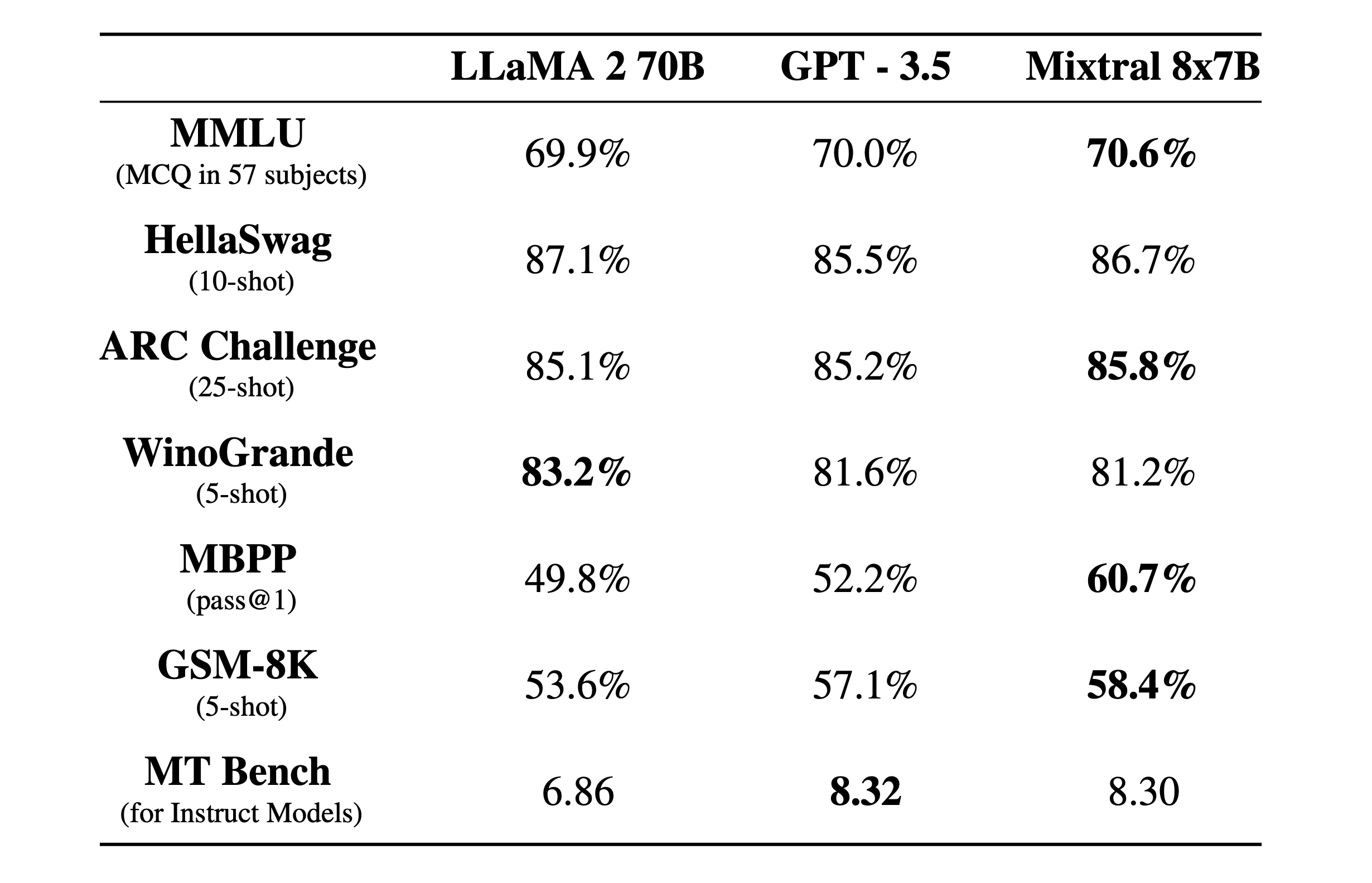
Mixtral surpasses Llama 2 70B in most benchmarks and offers six times the inference speed, making it the leading open-weight model in terms of cost-performance balance.
Mixtral 8x7B competes with or exceeds OpenAI GPT-3.5 on various benchmarks, and Mixtral outputs are preferred by users over Anthropic Claude 2.1, OpenAI GPT-3.5-Turbo, Google Gemini Pro, and 01 Yi-34B.
Key Features of Mixtral 8x7B:
- Supports a 32k token context for extensive data handling
- Multilingual capabilities in English, French, Italian, German, and Spanish
- Superior code generation performance
- Instruction-following model with an 8.3 MT-Bench score
- The model is trained on open web data
- simultaneous expert and router development
- Competitive with both Llama 2 70B and GPT-3.5 across various benchmarks
Mixtral 8x7b has a total of 56 billion parameters, supports a 32k context window, and displaces both Meta Llama 2 and OpenAI GPT-3.5 in 4 out of 7 leading LLM benchmarks. The Mixtral 8x7B model include support for 32k tokens, which allows it to handle extensive contexts, and it has demonstrated better code generation capabilities. It has been shown to match or outperform GPT-3.5 on most standard benchmarks. The model is also noted for its truthfulness and reduced bias, as indicated by its performance on benchmarks like TruthfulQA.
Mixtral 8x7B is Mistral AI's second Large Language Model (LLM) and is licensed under Apache 2.0, making its weights openly available. It offers a 6x faster inference rate compared to Llama 2 70B and is considered the strongest open-weight model with a permissive license. The model is available in multiple languages, including French, German, Spanish, Italian, and English, and has been fine-tuned for instructed tasks.
Developers can access the Mixtral 8x7B model through various platforms, including the Klu.ai platform and Vercel's demo, which allows for comparison with other models like Meta LLaMA 2 70B. For those who prefer local usage, LM Studio supports offline model usage on various operating systems.
Mistral AI has positioned the Mixtral 8x7B model as a transformative force in the AI landscape, with its combination of cutting-edge computing architecture and sophisticated algorithms. The model's release represents a significant step towards commercializing AI innovations and making advanced AI models more accessible to the developer community.
Mistral-8x7B, an upgrade from Mistral-7B-v0.1, offers enhanced text understanding and generation, making it ideal for chat, writing, and communication tasks. It is designed to be powerful and fast, adaptable to many use cases, and supports multiple languages and code. However, due to its large size, it may not be suitable for running on a home GPU.
The model is a high-quality, sparse mixture of experts model (SMoE) with open weights and is licensed under Apache. It has been optimized through supervised fine-tuning and direct preference optimization (DPO) for careful instruction following.
Key features of this model include:
- Architecture — Mistral 8x7B uses a transformer architecture, with 8 experts, utilizing 2 experts at inference time.
- Attention Mechanisms — The model employs grouped-query attention for quick inference and sliding window attention for reasoning.
- Size — The 8x7B model has 8 experts, each with 7 billion parameters, resulting in a total of 56 billion parameters.
From Mistral's press release:
Mistral AI has released Mixtral 8x7B, a high-quality sparse mixture of expert models (SMoE) with open weights, licensed under Apache 2.0. The model, which outperforms Llama 2 70B on most benchmarks, is capable of handling a context of 32k tokens in several languages, including English, French, Italian, German, and Spanish. Mixtral performs well in code generation and can be fine-tuned to follow instructions, achieving a score of 8.3 on MT-Bench. It uses a sparse mixture-of-experts network and is pre-trained on data extracted from the open web. In comparison to other models, Mixtral is more truthful and presents less bias. The model can be deployed using an open-source stack, and Mistral AI is currently using it in their endpoint mistral-small, which is available in beta.
The Mixtral 8x7B 32k model is a significant advancement in the field of AI and large language models, offering improved performance and efficiency compared to its predecessors. The official model code is not yet available, but frontier research labs and startups started implementing versions of the model.
Mistral announced additional details about the model on December 11, 2023, including a prototype model with superior benchmarks. More information can be found on their official news page. As part of this announcement, Mistral has launched their model platform, which hosts the Mistral 7b (tiny), Mixtral 8x7b (small), and an undisclosed, more performant prototype model (medium).
Below is the stock model config.
{
"dim": 4096,
"n_layers": 32,
"head_dim": 128,
"hidden_dim": 14336,
"n_heads": 32,
"n_kv_heads": 8,
"norm_eps": 1e-05,
"vocab_size": 32000,
"moe": {
"num_experts_per_tok": 2,
"num_experts": 8
}
}
Official Mistral Benchmarks for Mixtral 8x7b
Mistral released official benchmarks for Mixtral 8x7b across comparable models, including OpenAI GPT-3.5 and Meta Llama 2.
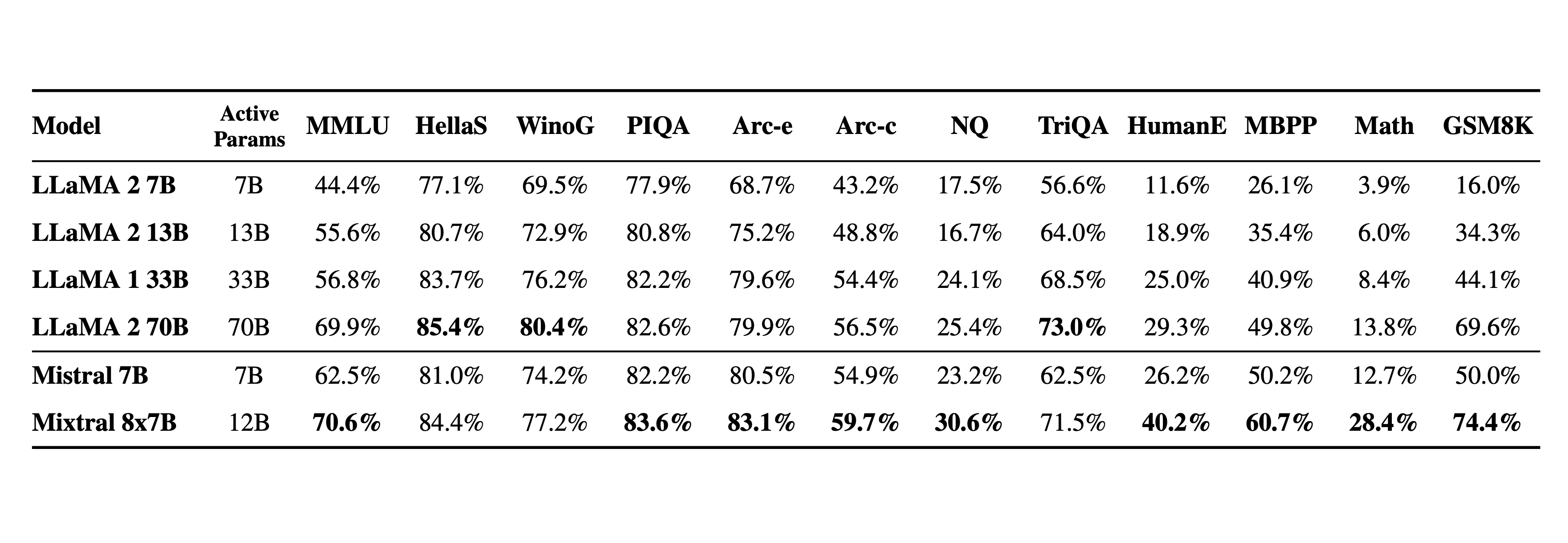
The Mixtral 8x7B model shows strong performance across a range of benchmarks, often outperforming the Llama models on tasks that measure understanding and reasoning, such as MMLU, HellaSwag, ARC Challenge, and WinoGrande.
Overall, the Mixtral 8x7B model appears to be a robust and capable model, often outperforming or matching the benchmarks set by Llama models, especially in multilingual understanding and bias measurements. Mixtral 8x7B's performance indicates its potential as a leading choice for tasks requiring detailed understanding and generation.
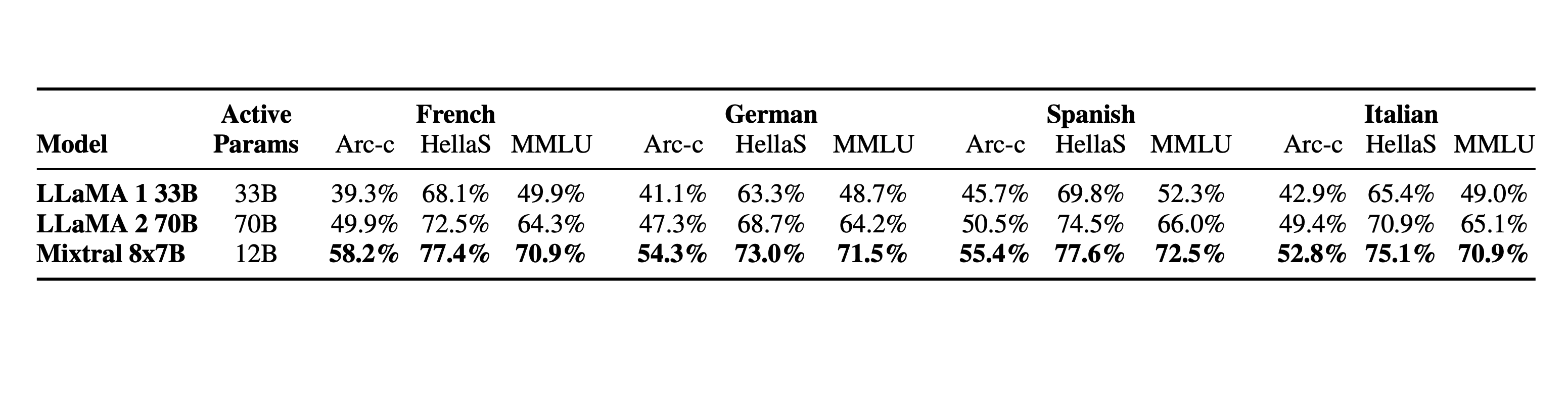
Mixtral 8x7B exhibits superior multilingual capabilities, outperforming Llama models in Spanish, French, German, and Italian on the MMLU (Multiple-Choice Questions in 57 Subjects) test. Its consistent high performance across different languages, particularly in the Hellas benchmarks, underscores its robust multilingual proficiency.
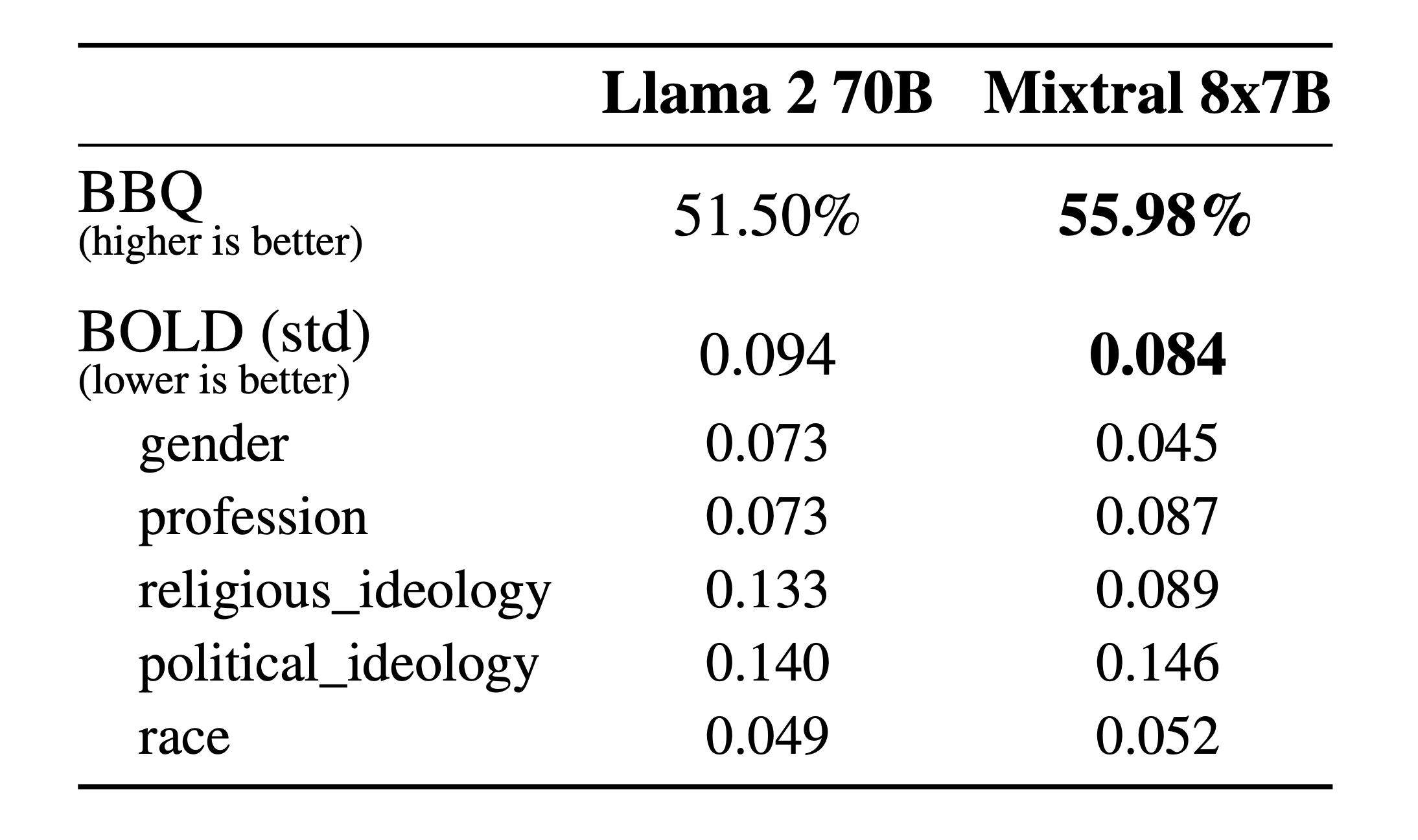
The Mixtral 8x7B model has lower BOLD (Bias in Open-ended Language generation Datasets) standard deviation scores, indicating it may generate less biased text across categories like gender, profession, religious ideology, political ideology, and race. Particularly, it shows less gender and race bias compared to Llama 2 70B, which is an important consideration for models deployed in diverse and inclusive environments.
MMLU 5-Shot Benchmark
Early community benchmarks place Mistral 8x7b higher than Open GPT-3.5 and near Google Gemini Pro. We expect fine-tuned variations to gain 5-10 more points.
| Model | MMLU Score |
|---|
| GPT-4 | 86.4 |
| Gemini Ultra | 83.7 |
| Mistral Medium | 75.3 |
| Gemini Pro | 71.8 |
| Mistral 8x7b | 71.3 |
| GPT-3.5 | 70 |
| Mistral 7b | 60.1 |
Community Benchmark
The team behind OpenCompass published comprehensive, third-party benchmarks of the Mixtral 8x7b model, comparing it to Mistral 7b, Llama 2 70b, DeepSeek 67b, and Qwen 72b.
| Eval | Mode | Mistral-7B | Mixtral-8x7B | Llama2-70B | DeepSeek-67B-Base | Qwen-72B |
|---|
| MMLU | PPL | 64.1 | 71.3 | 69.7 | 71.9 | 77.3 |
| BIG-Bench-Hard | GEN | 56.7 | 67.1 | 64.9 | 71.7 | 63.7 |
| GSM-8K | GEN | 47.5 | 65.7 | 63.4 | 66.5 | 77.6 |
| MATH | GEN | 11.3 | 22.7 | 12.0 | 15.9 | 35.1 |
| HumanEval | GEN | 27.4 | 32.3 | 26.2 | 40.9 | 33.5 |
| MBPP | GEN | 38.6 | 47.8 | 39.6 | 55.2 | 51.6 |
| ARC-c | PPL | 74.2 | 85.1 | 78.3 | 86.8 | 92.2 |
| ARC-e | PPL | 83.6 | 91.4 | 85.9 | 93.7 | 96.8 |
| CommonSenseQA | PPL | 67.4 | 70.4 | 78.3 | 70.7 | 73.9 |
| NaturalQuestion | GEN | 24.6 | 29.4 | 34.2 | 29.9 | 27.1 |
| TrivialQA | GEN | 56.5 | 66.1 | 70.7 | 67.4 | 60.1 |
| HellaSwag | PPL | 78.9 | 82.0 | 82.3 | 82.3 | 85.4 |
| PIQA | PPL | 81.6 | 82.9 | 82.5 | 82.6 | 85.2 |
| SIQA | GEN | 60.2 | 64.3 | 64.8 | 62.6 | 78.2 |
| Dataset | Version | Metric | Mode | Mixtral-8x7b-32k |
|---|
| MMLU | - | naive_average | PPL | 71.34 |
| ARC-c | 2ef631 | accuracy | PPL | 85.08 |
| ARC-e | 2ef631 | accuracy | PPL | 91.36 |
| BoolQ | 314797 | accuracy | PPL | 86.27 |
| commonsense_qa | 5545e2 | accuracy | PPL | 70.43 |
| triviaqa | 2121ce | score | GEN | 66.05 |
| nq | 2121ce | score | GEN | 29.36 |
| openbookqa_fact | 6aac9e | accuracy | PPL | 85.40 |
| AX_b | 6db806 | accuracy | PPL | 48.28 |
| AX_g | 66caf3 | accuracy | PPL | 48.60 |
| hellaswag | a6e128 | accuracy | PPL | 82.01 |
| piqa | 0cfff2 | accuracy | PPL | 82.86 |
| siqa | e8d8c5 | accuracy | PPL | 64.28 |
| math | 265cce | accuracy | GEN | 22.74 |
| gsm8k | 1d7fe4 | accuracy | GEN | 65.66 |
| openai_humaneval | a82cae | humaneval_pass@1 | GEN | 32.32 |
| mbpp | 1e1056 | score | GEN | 47.80 |
| bbh | - | naive_average | GEN | 67.14 |
How to Access Mistral 8x7B 32k?
You can find the original Torrent Magnet link drop on X / Twitter.
If you don't want to use the Torrent, the Mistral "Mixtral" 8x7B 32k model can be found on the HuggingFace Model Hub, where you can directly download or use it for inference:
Testing the model
You can test the new model on several platforms:
Please note that the information provided is based on the current state of the Mistral 8x7B 32k model. We expect this to rapidly evolve over the next week.
What are the key features of Mistral 8x7B 32k?
The Mistral "Mixtral" 8x7B 32k model is a state-of-the-art artificial intelligence model developed by Mistral AI. It is a Sparse Mixture of Experts (SMoE) model, characterized by its advanced computational architecture, which includes high-speed parallel processing capabilities and sophisticated data handling functions.
Key features of the Mixtral 8x7B model include:
-
Support for 32k tokens — This allows the model to handle extensive contexts, making it capable of understanding and generating complex text.
-
Advanced code generation capabilities — The model has demonstrated better code generation capabilities, making it a valuable tool for tasks where understanding and solving algorithmic challenges are crucial.
-
Performance — The model matches or outperforms GPT-3.5 on most standard benchmarks, indicating its high performance and efficiency.
-
Open-source — The model is licensed under Apache 2.0, making its weights openly available. This fosters responsible AI usage and allows developers to modify and build upon the model.
-
Multilingual support — The model supports multiple languages, including French, German, Spanish, Italian, and English, making it versatile for various applications.
-
Efficiency — The model offers a 6x faster inference rate compared to Llama 2 70B, making it one of the most efficient models available.
-
Fine-tuning for instructed tasks — The model has been fine-tuned for instructed tasks, enhancing its performance for specific applications.
What is the difference between Mistral "Mixtral" 8x7b 32k model and Mistral 7b model?
The Mistral "Mixtral" 8x7B 32k and Mistral 7B models, both from Mistral AI, differ significantly. Mixtral 8x7B employs a Sparse Mixture of Experts (SMoE) architecture, integrating eight specialized models to enhance performance, whereas Mistral 7B lacks this structure. Consequently, Mixtral 8x7B surpasses Mistral 7B in benchmarks, including multilingual tasks, and supports a broader context with 32k tokens compared to Mistral 7B's effective 8k due to its sliding window implementation. However, Mixtral 8x7B's advanced capabilities require more resources—64GB of RAM and dual GPUs—unlike Mistral 7B's modest 24GB RAM and single GPU setup, leading to higher operational costs. Additionally, Mixtral 8x7B benefits from extensive fine-tuning across multiple datasets, contributing to its superior performance.
How does the performance of mistral "mixtral" 8x7b 32k model compare to other models?
The Mistral "Mixtral" 8x7B model, with 45 billion parameters, achieves high efficiency by utilizing only 12 billion parameters per token. This design enables it to operate at the speed and cost of a smaller model while maintaining the capability to process a 32k token context in multiple languages, including English, French, Italian, and German. Its performance rivals or exceeds that of Llama 2 70B and GPT-3.5 across various benchmarks, offering six times faster inference than Llama 2 70B, making it the most potent model available under a permissive license.
Mixtral 8x7B stands out for its truthfulness, scoring 73.9% on the TruthfulQA benchmark, and exhibits reduced bias, particularly in the BOLD benchmark. Its advanced code generation capabilities also surpass GPT-3.5 in standard benchmarks. While Mixtral 8x7B's resource requirements exceed those of Mistral 7B, necessitating more RAM and GPUs, its user-tunable nature allows for deployment on sufficiently equipped systems. Overall, Mixtral 8x7B's combination of efficiency, multilingual support, and superior code generation positions it as an optimal choice for diverse applications.
What are the Use Cases of Mistral 8x7B 32k?
The Mistral 8x7B 32k model is a powerful and efficient large language model (LLM) that has various use cases. Some of the potential applications include:
-
Natural language processing — The model can be used for various natural language processing tasks, such as text classification, sentiment analysis, and text generation.
-
Coding assistance — Mistral 8x7B 32k can help developers with code generation, debugging, and understanding complex programming concepts.
-
Content generation — The model can be used to generate content for blogs, articles, and other written materials, as well as create code for various applications.
-
Benchmarking — As a powerful and efficient LLM, Mistral 8x7B 32k can be used to benchmark the performance of other models and systems.
-
Customization — The model can be adapted to various use cases, making it a versatile tool for different applications and industries.
Overall, the Mistral 8x7B 32k model has the potential to revolutionize various industries and applications, offering a powerful and efficient LLM solution for numerous tasks and challenges.
How to Fine-tune Mistral 8x7B 32k?
To fine-tune the Mistral 8x7B 32k model, follow these steps:
-
Data Preprocessing — Convert your data into a suitable format for fine-tuning. This may involve tokenization, encoding, or other preprocessing tasks.
-
Fine-tuning Pipeline — Use a fine-tuning pipeline that includes data preprocessing, model training, and evaluation. You can use tools like Hugging Face Transformers, PEFT, or Valohai to fine-tune the model.
-
Prompt Engineering — Craft effective prompts for fine-tuning the model. This may involve experimenting with different prompt structures and techniques to improve the model's performance.
-
LoRA (Localized Reweighting of Attention) — To fine-tune the model cost-efficiently, consider using the LoRA technique, which allows you to fine-tune the model on your own data without the need for extensive GPU resources.
-
Inference — After fine-tuning the model, test its performance on a few prompts to ensure that it has learned the desired patterns and features.
What are some common issues with Mistral 8x7B 32k?
Some common issues with the Mistral 8x7B 32k model include:
-
Memory requirements — The model requires a significant amount of memory to operate. While it can fit in VRAM, it may not be possible to fit all layers of the model into VRAM, which could lead to performance issues.
-
Swapping experts — When "swapping" experts during inference, the model may run out of GPU memory if it cannot fit all experts into VRAM at the same time. This could result in slower performance.
-
Caching — It is recommended to cache the N most recent experts to avoid having to re-load them during inference, which could lead to performance issues if the cache is not properly managed.
-
Comparison with other models — The Mistral 8x7B 32k model is a scaled-down version of GPT-4, with 8 experts and 7B parameters per expert. It has a similar architecture to GPT-4 but with reduced parameters and sequence length.
-
Deployment — The model has been released under the Apache 2.0 License and can be deployed on various cloud platforms. However, it is unclear if there are any specific integration challenges or limitations when using the model with certain cloud services.
The Mistral 8x7B 32k model, while powerful and efficient, presents challenges that must be navigated for effective use. These include substantial memory demands, potential GPU memory shortages during expert swapping, and the need for strategic caching to prevent performance degradation. Additionally, when comparing to other models, it's important to note that Mistral 8x7B 32k is a scaled-down GPT-4 variant with fewer parameters and a shorter sequence length, which may affect its suitability for certain applications.
How Does Mistral 8x7B 32k Perform?
The Mistral 8x7B 32k model is a large language model (LLM) that has shown promising performance in various benchmarks. Some key aspects of this model include:
-
High Performance — Mistral 7B outperforms 13B Llama 2 in all benchmarks and surpasses the 34B Llama 1 in reasoning, math, and code generation.
-
Efficiency — Despite its large size (8 billion parameters), Mistral 7B is more efficient than other models. For example, it can perform as well as a 3x larger Llama 2 in comprehension and STEM reasoning while requiring less memory.
-
Fine-tuning — Mistral 7B can be fine-tuned on various datasets, such as public instruction datasets from the Hugging Face repository. The resulting model, Mistral 7B — Instruct, shows superior performance to other 7B models on MT-Bench and is on par with 13B — Chat models.
-
Human Evaluation — An independent human evaluation was conducted on llmboxing.com, where participants compared responses from two models. As of October 6, 2023, Mistral 7B's outputs were preferred 5020 times, while Llama 2 13B was chosen 4143 times.