What is MT-Bench?
MT-Bench is a challenging multi-turn benchmark that measures the ability of large language models (LLMs) to engage in coherent, informative, and engaging conversations. It was designed to assess the conversation flow and instruction-following capabilities of LLMs, making it a valuable tool for evaluating their performance in understanding and responding to user queries.
MT-Bench evaluates large language models (LLMs) like GPT-4 on multi-turn dialogues, assessing their ability to maintain context, follow instructions, and reason coherently. It uses quantitative scores for model comparison. Initially reliant on human evaluators, MT-Bench now employs the LLM-as-a-Judge approach, where strong LLMs score and explain responses, aligning with human preferences over 80% of the time. This scalable method is detailed in resources like leobeeson's GitHub and AWS samples. Early human evaluations remain crucial, as discussed in OpenReview and arXiv 2306.05685.
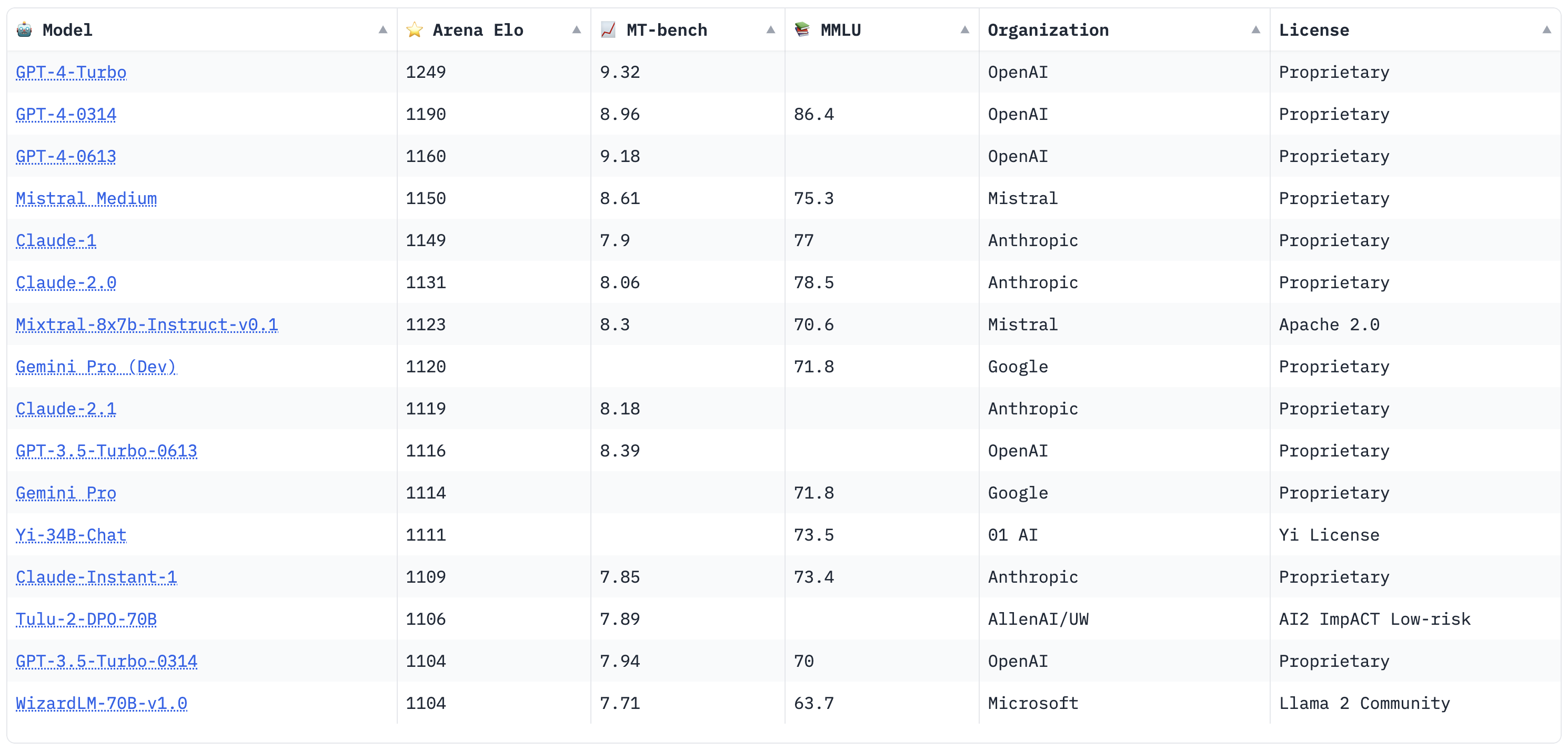
In addition to the benchmark score, you can participate in the Elo arena and provide human feedback. Preference feedback is used to generate the Elo leaderboard. As of September 2024, the leaderboard includes models such as Anthropic Claude 3, OpenAI GPT-4o and GPT-4 Turbo, Mistral Medium and Large, Google Gemini Pro and FLash, Mixtral-8x7b, and Tulu 2 among others.
The leaderboard is updated regularly (last updated July 31, 2024), providing a dynamic view of the best LLMs in the field.
It's important to note that the Elo score reflects a model's performance on a comparative single response rather than a multi-turn conversation. This distinction is crucial because while some models may generate impressive initial responses, their performance can diminish more rapidly over multiple exchanges compared to others.
Key features of the MT Bench Leaderboard include:
- Challenging Multi-Turn Benchmark — The MT-Bench incorporates challenging follow-up questions as part of its design, ensuring that models demonstrate a deep understanding of the task at hand.
- Three Metrics — The leaderboard uses three metrics for evaluation: Chatbot Arena Elo, based on 200k+ anonymous votes from Chatbot Arena using the Elo rating system; MT-Bench score, based on a challenging multi-turn benchmark and GPT-4 grading; and MMLU, a widely adopted benchmark.
- Regular Updates — The leaderboard is updated regularly, providing a constantly evolving view of the latest LLM performance.
Triangulating relative model performance with MT-Bench and AlpacaEval provides the best benchmark for general performance from both human preference and LLM-as-judge perspectives. While performance on individual use cases may vary between models, these two benchmarks offer the most reliable standard.
MT-Bench Leaderboard (September 2024)
As of September 27, 2024, the MT Bench Leaderboard has undergone significant changes, reflecting the rapid advancements in large language models (LLMs). The latest update reveals a reshuffling of top positions and the introduction of several new models. The o1-preview model has claimed the top spot with an impressive Arena Elo rating of 1355, followed closely by ChatGPT-4o-latest (2024-09-03) and o1-mini in second and third places respectively. This update highlights the intense dominance from OpenAI among leading AI companies.
Google has made a strong showing with multiple new entries, including various Gemini-1.5 variants such as Gemini-1.5-Pro-Exp-0827 and Gemini-1.5-Flash-Exp-0827. These additions demonstrate Google's commitment to advancing their AI capabilities. Meta has also entered the fray with their Meta-Llama-3.1-405b-Instruct models, which have secured competitive positions on the leaderboard with Arena Elo ratings of 1266 and 1264. xAI's contribution to the leaderboard comes in the form of the Grok-2-08-13 and Grok-2-Mini-08-13 models, further diversifying the range of high-performing LLMs.
Vision Leaderboard
The Vision Leaderboard ranks top LLMs based on their performance in vision-based conversations. It evaluates models using metrics like Arena Elo, MT-bench score, and MMLU, providing insights into their strengths and weaknesses.
| Model | Arena Score | Organization | Knowledge Cutoff |
|---|
| Gemini-1.5-Pro-Exp-0827 | 1231 (+9/-6) | Google | 2023/11 |
| GPT-4o-2024-05-13 | 1209 (+6/-6) | OpenAI | 2023/10 |
| Gemini-1.5-Flash-Exp-0827 | 1208 (+11/-12) | Google | 2023/11 |
| Claude 3.5 Sonnet | 1191 (+6/-4) | Anthropic | 2024/4 |
| Gemini-1.5-Pro-001 | 1151 (+8/-6) | Google | 2023/11 |
| GPT-4-Turbo-2024-04-09 | 1151 (+7/-4) | OpenAI | 2023/12 |
| GPT-4o-mini-2024-07-18 | 1120 (+6/-5) | OpenAI | 2023/10 |
| Gemini-1.5-Flash-8b-Exp-0827 | 1110 (+9/-10) | Google | 2023/11 |
| Qwen2-VL-72B | 1085 (+26/-19) | Alibaba | Unknown |
| Claude 3 Opus | 1075 (+5/-6) | Anthropic | 2023/8 |
| Gemini-1.5-Flash-001 | 1072 (+7/-6) | Google | 2023/11 |
| InternVL2-26b | 1068 (+8/-7) | OpenGVLab | 2024/7 |
| Claude 3 Sonnet | 1048 (+6/-6) | Anthropic | 2023/8 |
| Yi-Vision | 1039 (+15/-15) | 01 AI | 2024/7 |
| qwen2-vl-7b-instruct | 1037 (+23/-21) | Alibaba | Unknown |
| Reka-Flash-Preview-20240611 | 1024 (+8/-6) | Reka AI | Unknown |
| Reka-Core-20240501 | 1015 (+5/-6) | Reka AI | Unknown |
| InternVL2-4b | 1010 (+9/-8) | OpenGVLab | 2024/7 |
| LLaVA-v1.6-34B | 1000 (+9/-7) | LLaVA | 2024/1 |
| Claude 3 Haiku | 1000 (+7/-6) | Anthropic | 2023/8 |
| LLaVA-OneVision-qwen2-72b-ov-sft | 992 (+16/-13) | LLaVA | 2024/8 |
| CogVLM2-llama3-chat-19b | 990 (+13/-12) | Zhipu AI | 2024/7 |
| MiniCPM-v 2_6 | 976 (+15/-13) | OpenBMB | 2024/7 |
| Phi-3.5-vision-instruct | 916 (+11/-10) | Microsoft | 2024/8 |
| Phi-3-Vision-128k-Instruct | 874 (+15/-12) | Microsoft | 2024/3 |
The updated leaderboard continues to evaluate a wide spectrum of models from renowned AI research organizations such as OpenAI, Anthropic, Google, Meta, and Reka AI. It provides a comprehensive overview of model performance, considering metrics like Arena Elo rating, MT-bench score, and MMLU score. This latest update underscores the ongoing competition and rapid innovation in AI, with new models consistently pushing the boundaries of performance benchmarks. As of September 2024, the MT Bench Leaderboard remains an essential resource for tracking the state-of-the-art in LLM capabilities, offering valuable insights into the evolving landscape of artificial intelligence.
How does MT-Bench work?
MT-Bench is a challenging multi-turn question set designed to evaluate the conversational and instruction-following ability of large language models (LLMs).
The benchmark consists of 80 high-quality, multi-turn questions tailored to assess conversation flow and instruction-following capabilities.
Some key aspects of MT-Bench include:
- Purpose — MT-Bench aims to evaluate the performance of LLMs in open-ended conversations, approximating human preferences.
- Methodology — The benchmark uses fastchat.llm_judge and the Arena Elo calculator, with MMLU based on InstructEval and Chain-of-Thought Hub.
- Leaderboard — A leaderboard is maintained to track the performance of various LLMs, such as GPT-4-turbo, Vicuna-33B, WizardLM-30B, and others.
- Challenges — MT-Bench incorporates challenging follow-up questions as part of its design, making it a rigorous test for LLMs.
For practical use, the MT Bench prompts are available through the Hugging Face datasets library, allowing developers and researchers to evaluate chat models using the benchmark.
The MT-Bench dataset contains expert-level pairwise human preferences for model responses generated by LLMs like GPT-4, GPT-3.5, Claud-v1, Vicuna-13B, Alpaca-13B, and LLaMA-13B.
The benchmark is used in conjunction with Chatbot Arena, a crowdsourced battle platform where users ask chatbots any question and vote for their preferred answer. Both benchmarks aim to use human preferences as the primary metric for evaluating LLMs.
What is the purpose of MT-Bench?
The Multi-Turn Bench addresses the shortcomings of traditional benchmarks that struggle to differentiate between human-aligned and non-aligned LLMs. MT Bench uses a challenging multi-turn question set to assess the conversational and instruction-following abilities of models, simulating real-world conversational scenarios for a dynamic performance assessment.
MT Bench LLM Eval aims to provide a comprehensive, objective, and scalable method for evaluating LLMs, particularly in chatbot applications, by addressing the limitations of traditional benchmarks and offering a more dynamic and explainable evaluation process.
This makes it ideal for evaluating chatbots, which are expected to manage complex, multi-turn conversations. A distinctive feature of MT Bench is its use of strong LLMs as judges, which offers scalability and explainability.
Automation and Explainability
The automation of the evaluation process through LLM judges allows for rapid and scalable assessments, particularly beneficial when evaluating a large number of models or conducting frequent evaluations.
Additionally, LLM judges provide not only scores but also explanations, offering interpretable outputs and valuable insights.
Limitations of LLM-as-a-Judge
However, it's crucial to acknowledge the limitations of LLM-as-a-judge, such as its inability to detect hallucinations and penalize LLM generated answers accordingly, and potential errors when grading math/reasoning questions.
What are some criticisms of MT-Bench?
Some criticisms of the MT Bench include:
-
Position, verbosity, and self-enhancement biases — The paper examines the usage and limitations of LLM-as-a-judge, which can be affected by position, verbosity, and self-enhancement biases, as well as limited reasoning ability.
-
Limited reasoning ability — The paper also discusses the limited reasoning ability of LLM-as-a-judge, which may not be able to fully understand and evaluate the complexities of certain tasks or questions.
Despite these criticisms, the paper proposes solutions to mitigate some of the limitations and demonstrates that strong LLM judges, like GPT-4, can match both controlled and crowdsourced achieving over 80% agreement, the same level of agreement between humans. The benchmark and traditional benchmarks complement each other by evaluating various aspects of LLM performance, providing a more comprehensive understanding of their capabilities and limitations.
What are some future directions for MT-Bench research?
Some future directions for MT-Bench research include:
-
Expansion of language pairs and tasks — Incorporating more languages, dialects, and task types will broaden the scope of machine translation evaluation. This could involve adding new languages or working with low-resource and endangered languages.
-
Exploration of multimodal and cross-lingual tasks — Expanding MT-Bench to include multimodal and cross-lingual tasks such as image captioning, visual question answering, and language understanding can further assess the capabilities of translation models in real-world scenarios.
-
Inclusion of newer metrics and evaluation methods — As new metrics are developed to evaluate translation quality, incorporating these into MT-Bench will provide a more comprehensive assessment of machine translation systems. This could involve developing metrics for evaluating aspects such as fluency, coherence, and naturalness in translations.
-
Incorporation of real-world data — Utilizing authentic data from various domains, such as e-commerce, healthcare, or social media, can better reflect the real-world scenarios where machine translation models will be employed. This would also involve addressing challenges like handling noisy and incomplete data.
-
Improving benchmarking tools and methodologies — Developing advanced methods for preprocessing, postprocessing, and managing evaluation results can facilitate more accurate and reliable comparisons between different models and approaches.
-
Promoting collaboration and sharing of resources — Encouraging researchers to contribute datasets, models, metrics, and other resources to MT-Bench will promote a collaborative environment that fosters innovation and improves the quality of machine translation research overall.
Judging LLM-as-a-Judge
The paper "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena" explores the use of Large Language Models (LLMs) as judges to evaluate other LLMs, particularly in the context of chat assistants. The authors identify the challenges of evaluating LLMs due to their broad capabilities and propose using strong LLMs as judges to evaluate these models on more open-ended questions.
The paper introduces two benchmarks: MT-Bench, a multi-turn question set, and Chatbot Arena, a crowdsourced battle platform. These benchmarks are used to verify the agreement between LLM judges and human preferences. The results reveal that strong LLM judges like GPT-4 can match both controlled and crowdsourced human preferences, achieving over 80% agreement, which is the same level of agreement between humans.
The authors also examine the usage and limitations of LLM-as-a-judge, including position bias, verbosity bias, self-enhancement bias, and limited reasoning ability. They propose solutions to mitigate some of these biases. The paper concludes that LLM-as-a-judge is a scalable and explainable way to approximate human preferences, which are otherwise very expensive to obtain.
The paper's data, including the MT-bench questions, 3K expert votes, and 30K conversations with human preferences, are publicly available.
What does MT stand for?
MT-Bench stands for "Multi-Turn Benchmark," in which the "MT" is often mistakenly thought to refer to machine translation.
Looking at you Claude...