What is Google Gemini?
Google Gemini is a powerful AI model developed by Google DeepMind, which has been trained on video, images, and audio, making it the company's most capable AI model to date. Some of the key features and capabilities of Google Gemini include:
- Multimodal Reasoning — Gemini is designed to reason seamlessly across text, images, video, audio, and code, making it a versatile tool for various applications.
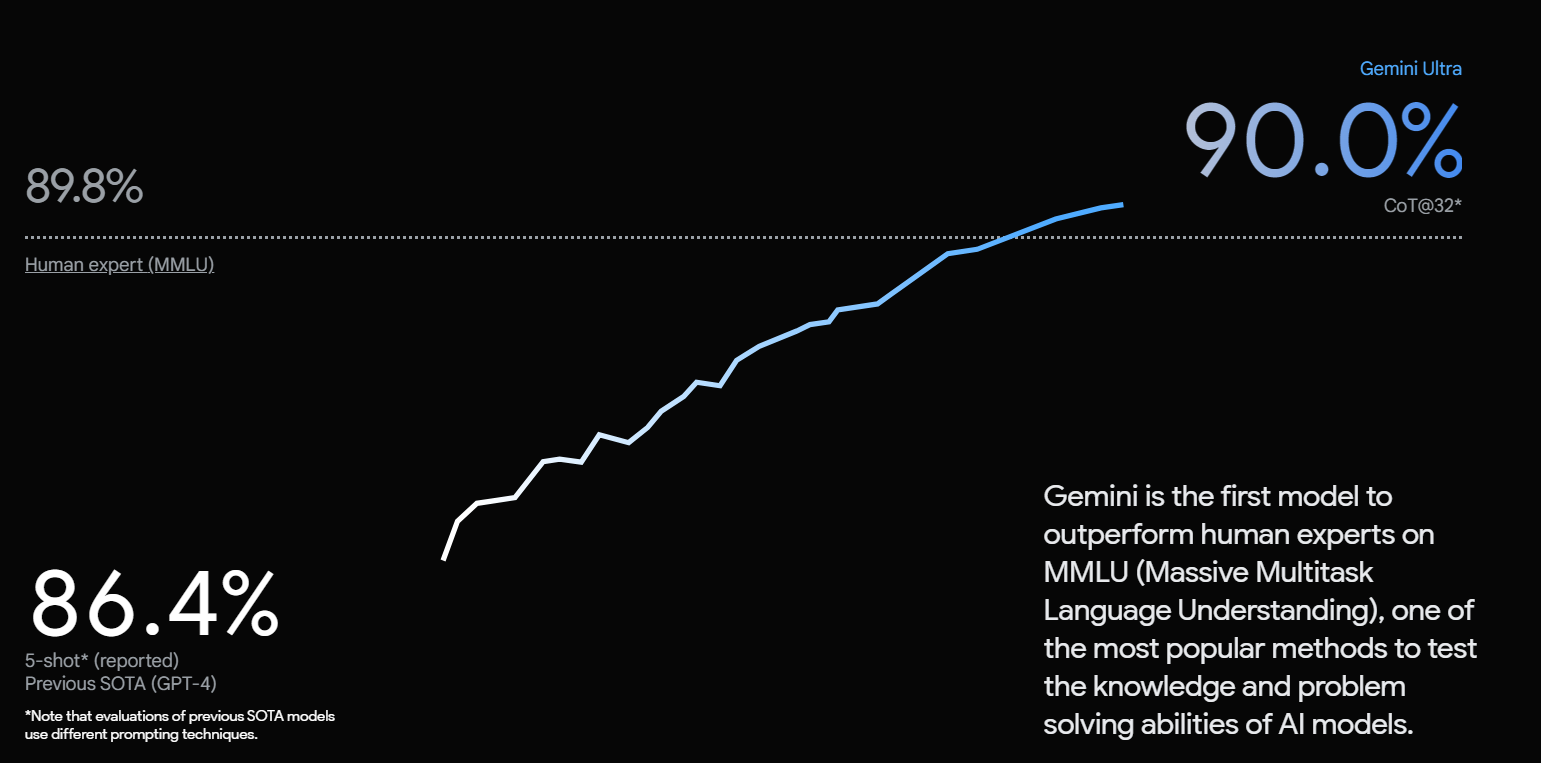
- Massive Multitask Language Understanding (MMLU) — Gemini is the first model to outperform human experts on MMLU, a popular method for testing AI models.
- Code Generation — Gemini can generate code based on different inputs, showcasing its potential in various software applications.
- Visual Reasoning — The model can reason visually across languages and recognize images quickly, even for connect-the-dots pictures.
However, Google has faced criticism for a demonstrative video of Gemini, which the company now claims was not conducted in real time. The video showed a smooth voice conversation with Gemini, as well as its ability to recognize visual pictures and physical objects. Despite the controversy, Google continues to develop and improve Gemini, with plans to integrate it into various products and services, such as search, ads, and the Chrome browser.
Google Gemini Model Details
Google Gemini, developed by Google, is a multimodal generative AI model. It's capable of understanding text, images, videos, and audio, making it Google's most versatile AI model to date.
It comes in three variants: Gemini Ultra, Gemini Pro, and Gemini Nano, each optimized for specific tasks and platforms.
- Gemini Ultra is designed for highly complex tasks and is set to be released after finishing its current phase of testing. It exceeds "current state-of-the-art results on 30 of the 32 widely-used academic benchmarks used in large language model (LLM) research and development".
- Gemini Pro is designed for a wide range of tasks and is currently being integrated across various Google products and platforms.
- Gemini Nano is designed for efficient on-device tasks and is currently available on Google products like the Pixel 8 phone and Bard chatbot.
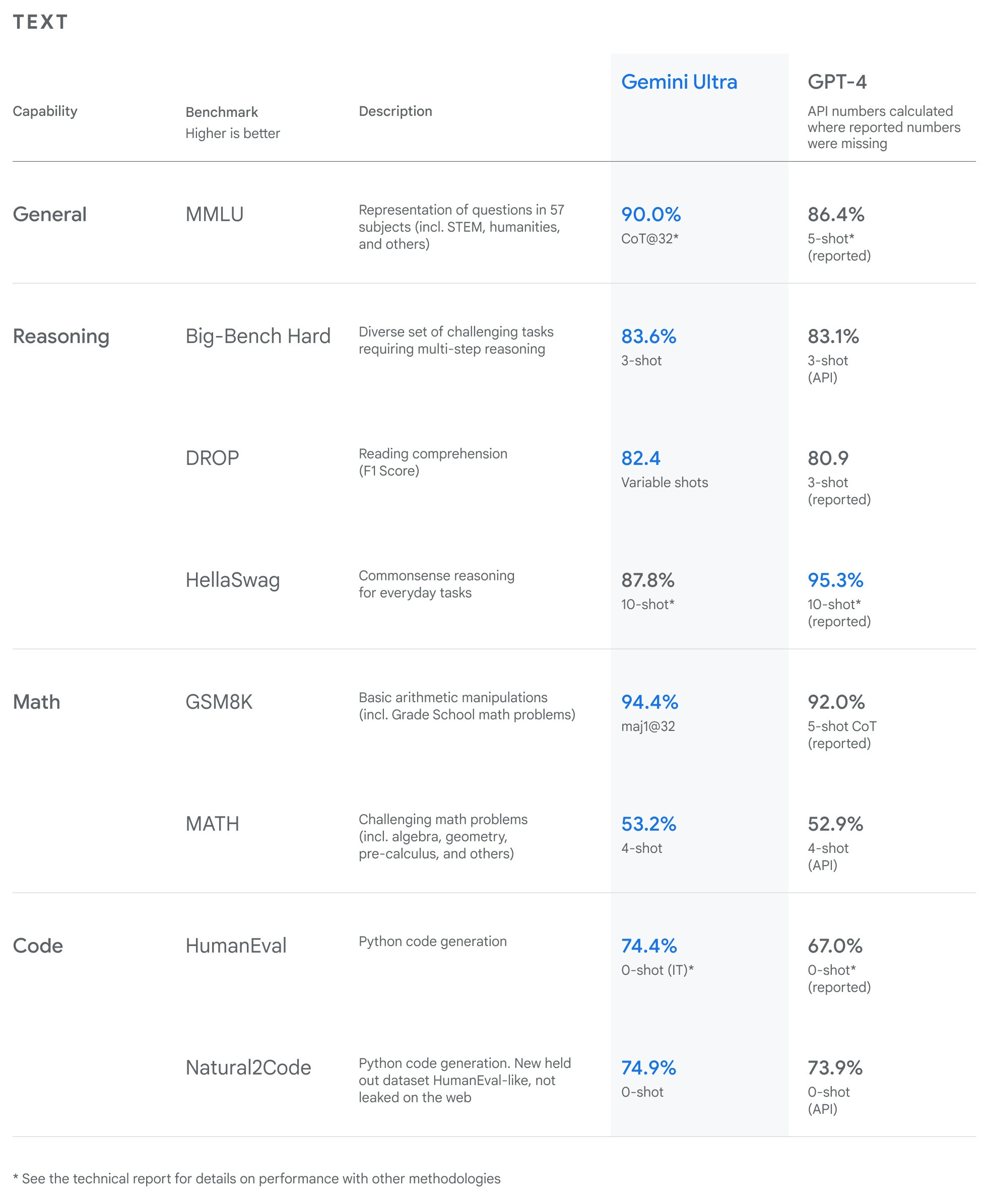
The model's performance is exceptional, surpassing human experts in Massive Multitask Language Understanding (MMLU) with a score of 90.0%. However, in a test set for commonsense reasoning, HellaSwag, Gemini Ultra scored 87.8%, which is behind GPT-4.
Training Data
The specific details about the training data used for Gemini are not disclosed in the search results.
Evaluation Data
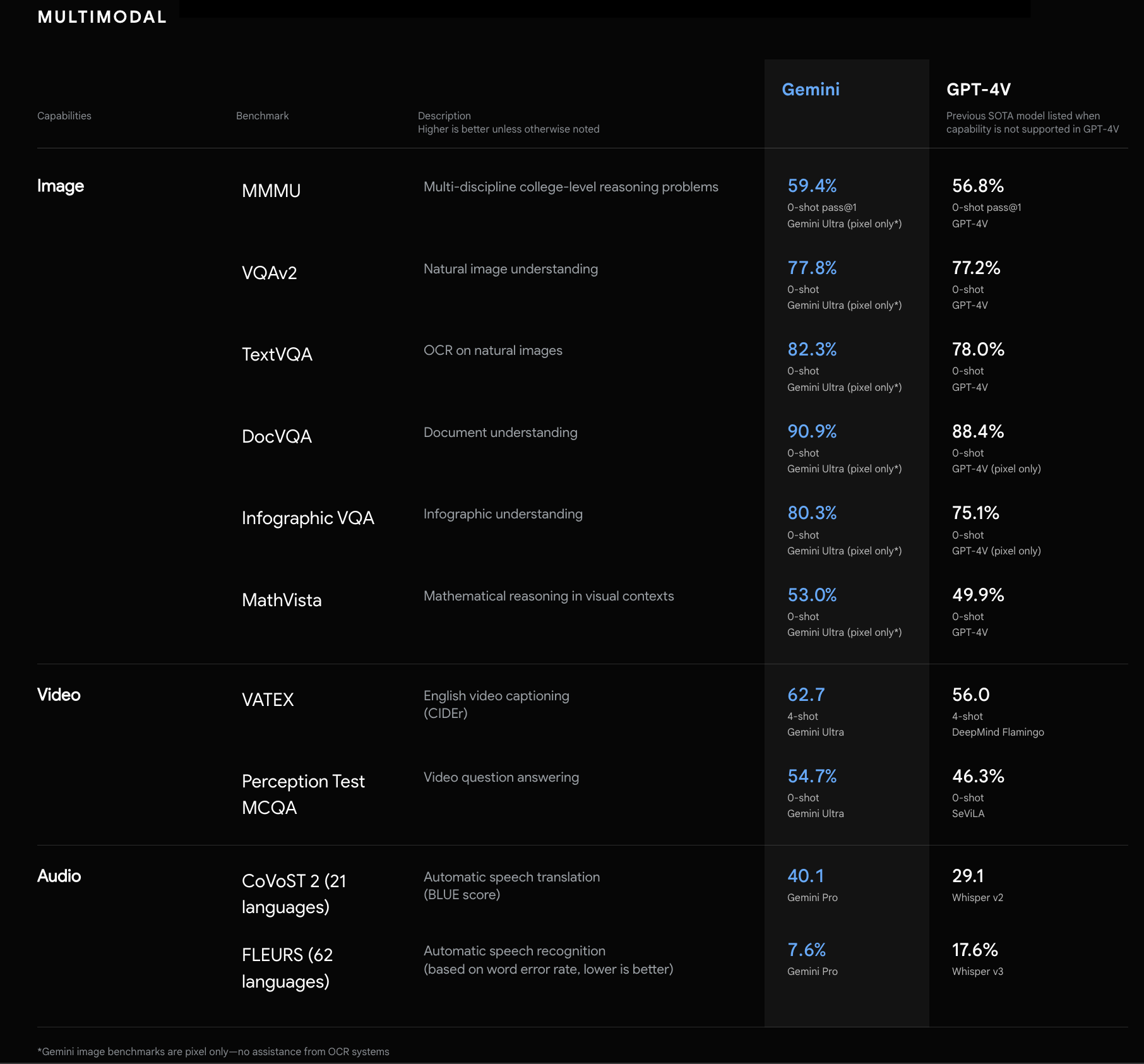
Gemini's performance was evaluated using a variety of benchmarks. It outperformed GPT-4 in 30 out of 32 benchmarks. However, it scored 87.8% in the HellaSwag commonsense reasoning test, which is behind GPT-4.
Metrics
Gemini surpassed human experts in Massive Multitask Language Understanding (MMLU) with a score of 90.0%. In the HellaSwag commonsense reasoning test, Gemini Ultra scored 87.8%.
What are Google Gemini's key features?
Google Gemini is a cutting-edge AI model with several key features that make it stand out from other large language models (LLMs). Some of its most notable features include:
- Multimodal capabilities — Gemini is designed to seamlessly reason across text, images, video, audio, and code, making it a versatile and powerful AI system.
- Massive Multitask Language Understanding (MMLU) — Gemini is the first model to surpass human experts in MMLU, demonstrating its extensive knowledge and problem-solving capabilities.
- Understanding and generating high-quality code — Gemini is particularly adept at understanding and generating code in various programming languages, making it a valuable tool for developers and software engineers.
- Integration with Google products — Gemini is now available on Google products in its Nano and Pro sizes, such as the Pixel 8 phone and Bard chat assistant, with plans to integrate it into Google's Search, Ads, Chrome, and other services.
- Gemini Ultra — This is the most capable version of Gemini, exceeding "current state-of-the-art results on 30 of the 32 widely-used academic benchmarks used in the field".
Overall, Google Gemini is a highly advanced AI model with diverse capabilities that span across various domains, making it a significant leap forward in artificial intelligence and a potential challenge to other LLMs like OpenAI's ChatGPT.
How does Google Gemini work?
Google Gemini is a multimodal large language model (LLM) that can understand and process not just text but also images, videos, and audio. It was developed by Google DeepMind and serves as the successor to LaMDA and PaLM 2. Gemini is designed to be flexible and capable of running on various platforms, from Google's Tensor Processing Units (TPUs) to other computing systems.
Gemini is currently accessible through integrations into Google Bard and the Google Pixel 8, but expanded to Google Vertex developers on December 13, 2023.
Gemini's architecture is built on top of Transformer decoders, with separate text and vision encoders. It has been trained on a wide range of data, including text, code, audio, image, and video, making it a versatile model capable of completing complex tasks in various domains, such as math and physics. Google claims that Gemini largely outperforms OpenAI's GPT-4 model in most benchmark tests.
Some of the key features and capabilities of Google Gemini include:
- Multimodal Inputs — Gemini can take textual input and a wide variety of audio and visual inputs, such as natural language text, images, audio, video, 3D models, and graphs.
- Versatility — Gemini is designed to be adaptable and efficient, capable of running on different platforms and handling various tasks.
- Improved Code Generation — Google claims that Gemini's AlphaCode 2 system performs better than 85% up from 50% for the original AlphaCode, making it a significant improvement in code generation capabilities.
As of now, Gemini is still in the training phase, with plans to fine-tune and improve safety in the future. Once fully developed and integrated into various Google services, such as search, ads, and Bard, Gemini has the potential to revolutionize AI applications and user experiences.
What are the benefits of using Google Gemini?
Google Gemini is a powerful and versatile AI model that offers numerous benefits across various applications and industries. Some of the key advantages of using Google Gemini include:
-
Multimodal capabilities — Gemini is trained on Tensor Processing Units (TPUs) across image, audio, video, and text data, making it highly capable of understanding and reasoning in multi-modal tasks for different domains.
-
Strong generalist capabilities — Gemini can process a wide variety of inputs, such as natural images, charts, screenshots, PDFs, and videos, and produce text and image outputs, making it excellent at understanding and reasoning in various tasks.
-
Efficiency — Gemini is designed with cost- and latency-optimization in mind, making it a more efficient model for deploying at scale.
-
Safety and responsible deployment — Google has employed best-in-class adversarial testing techniques to identify safety issues and has built dedicated safety classifiers to help its model with toxicity and other potential problems.
-
Integration with Google products — Gemini is poised to be integrated into various Google products, including the search engine, ad products, and the Chrome browser, marking the beginning of a new era in AI development.
-
Enhanced user experiences — Gemini promises advanced reasoning, planning, and understanding capabilities, particularly in Google's products like the Bard chatbot and Search Generative Experience.
-
Availability for developers — Google Cloud will make Gemini Ultra available in an early access program for developers, rolling out more broadly in early 2024. Gemini Pro will be available starting December 13 in Google Cloud's Vertex AI and AI Studio, while a version called Gemini Nano for on-device applications will be available on Google Pixel phones.
Overall, Google Gemini is a significant advancement in AI technology, with the potential to revolutionize various industries and applications, from search and chatbots to enterprise solutions and on-device tasks.
What are the limitations of Google Gemini?
Google Gemini is a multimodal AI model that showcases impressive capabilities in various modalities, but it also has some limitations. Some of the key limitations of Google Gemini include:
-
English-only interactions — The current version of Gemini Pro is available only in English, which hinders its global accessibility.
-
Integration within Bard — The integration of Gemini Pro within Google's Bard chatbot is limited, with future enhancements expected from Google.
-
Inconsistencies in factual accuracy — Gemini Pro has faced criticism for inconsistencies in factual accuracy and translation errors.
-
Coding limitations — Developers have reported limitations in coding when using Gemini Pro.
-
Multimodal capabilities — Despite being touted as "natively multimodal," Gemini's multimodal capabilities are not yet fully available, and it may struggle to handle visual information as effectively as it claims to.
-
Comparison to other AI models — While Gemini may outperform some AI models, such as GPT-4, it has not disclosed full details of its architecture, training data, or size, making it difficult to determine its true capabilities.
-
Geographical constraints — The availability of Gemini Pro is restricted in certain regions, such as the European Union.
Despite these limitations, Google plans to release more advanced versions of Gemini, such as Gemini Ultra, which may address some of the current concerns.
What is the scandal around Google Gemini?
The scandal around Google Gemini revolves around a demonstration video that showcased the AI model's capabilities. However, Google has admitted that the video was edited and did not accurately represent the AI's abilities in real-time. Key points about the scandal include:
-
The demonstration video was intended to inspire and showcase Gemini's capabilities, but it was later clarified that the AI did not respond in real-time to voice or video prompts.
-
Critics argue that the video's portrayal of Gemini's capabilities is similar to existing models like OpenAI's GPT-4, and the AI did not actually come up with the game featured in the video.
-
Google has released different versions of Gemini, including Gemini Nano, Gemini Pro, and Gemini Ultra, with the most advanced version, Gemini Ultra, outperforming OpenAI's GPT-4 on a commonly-used evaluation, MMLU.
Despite the controversy, Google's Gemini project remains a significant milestone in the development of AI and has the potential to intensify the debate about the technology's potential promise and perils.