What is Sliding Window Attention?
Sliding Window Attention is like having a narrow spotlight in a dark room, where you can only focus on objects within a small area at a time. It's a smart way for LLMs to read and understand large texts without getting overwhelmed, by concentrating on a few words at a time.
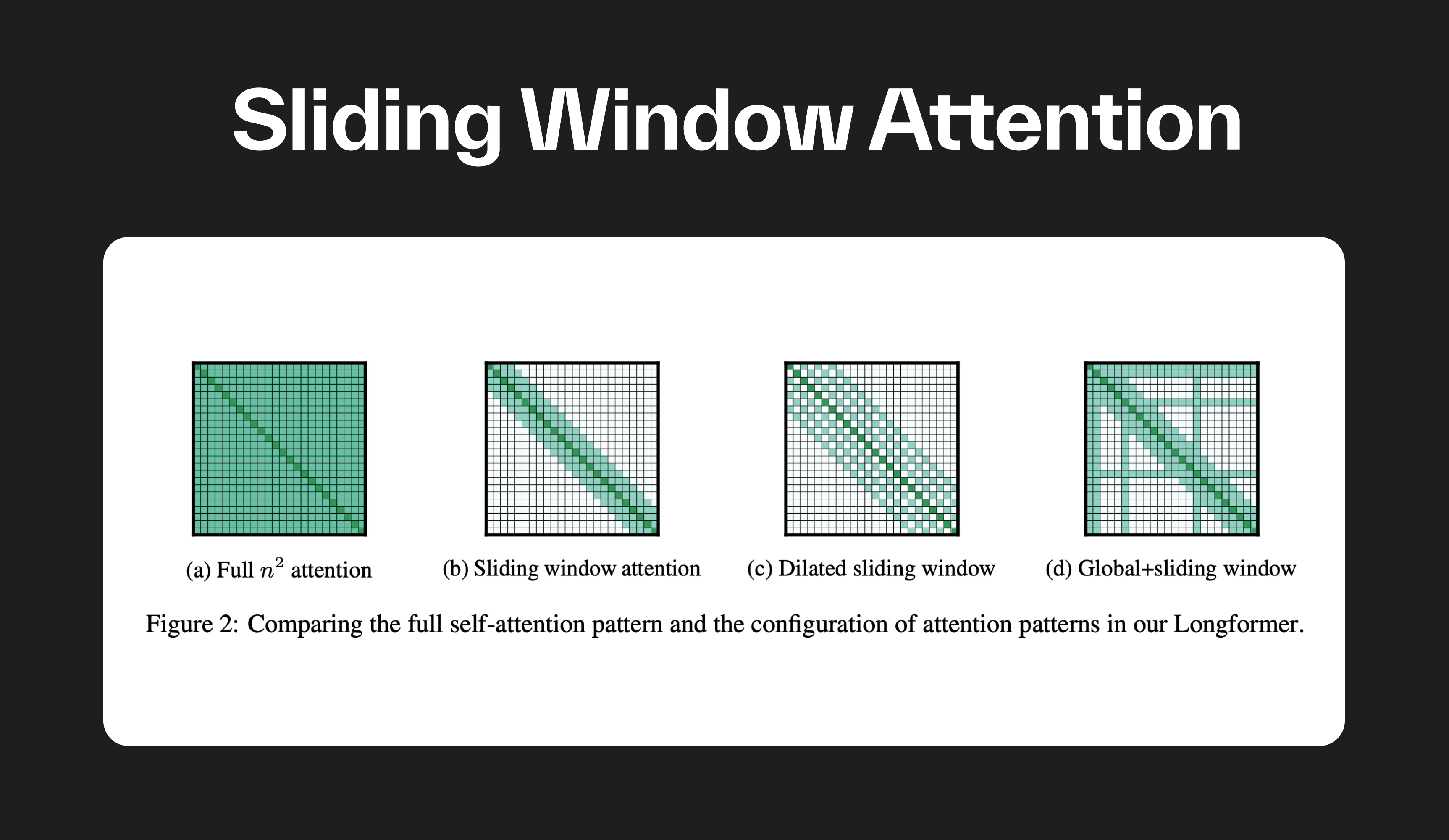
Sliding Window Attention (SWA) is a technique used in transformer models to limit the attention span of each token to a fixed size window around it. This reduces the computational complexity and makes the model more efficient.
How does Sliding Window Attention work?
Sliding Window Attention (SWA) operates by partitioning the input sequence into overlapping segments, or "windows," each of a consistent size. Here's how it works:
- The model first divides the input sequence into these windows, ensuring that each segment overlaps with the previous and next segments to maintain context continuity.
- For each window, the model computes attention scores, which determine the relevance of each token within the window to the task at hand.
- The attention mechanism then processes these windows sequentially, sliding across the input sequence and aggregating information from each window to inform the model's predictions.
This approach allows the model to focus on a manageable subset of the input at any given time, improving efficiency while still capturing the necessary contextual information for accurate predictions.
SWA can be thought of as a way to optimize the attention mechanism in transformer-based models. Instead of computing attention for each token with respect to all other tokens, SWA restricts the attention to a fixed size window around each token. This reduces the number of attention computations, leading to faster training and inference times.
There are many different ways to implement SWA, but the key idea is to limit the attention span of each token to a fixed size window around it. This can be done in various ways, such as by using a fixed window size or by dynamically adjusting the window size based on the context.
Once a model has been optimized with SWA, it can then be used for tasks such as text classification, sentiment analysis, question answering, and more. The optimized model will be faster and use less memory than the original model, but it may also be less accurate. The challenge of SWA is to reduce the computational complexity as much as possible without significantly reducing the model's accuracy.
SWA is a powerful tool for optimizing transformer models. It can be used to make models faster and more memory-efficient, which is particularly important for deploying models on devices with limited computational resources.
What is the difference between sliding window attention and global attention?
Sliding Window Attention (SWA) enhances efficiency for long sequences by focusing on overlapping segments, or "windows," within the input. It calculates attention scores for each segment, allowing the model to prioritize information as the window slides across the sequence. SWA is computationally efficient and suitable for lengthy sequences but may struggle with capturing long-range dependencies that extend beyond a single window.
Global Attention, in contrast, considers the entire input sequence at once, applying attention to all positions simultaneously. It focuses on specific, strategically chosen locations to capture the most relevant information, ensuring that each token with global attention is connected to every other token in the sequence. While Global Attention provides a comprehensive view of the sequence context, it can significantly increase computational demands.
Combining SWA with Global Attention, as seen in architectures like Longformer, offers a balanced approach. This hybrid method maintains efficiency while ensuring the model captures both local and global sequence context, crucial for accurate performance on tasks with long input sequences.
How does sliding window attention affect the performance of transformer-based models?
Sliding Window Attention (SWA) enhances Transformer-based models by reducing computational complexity from quadratic to linear with respect to input sequence length, enabling efficient handling of long sequences. By focusing on a fixed-size window around each token, SWA scales with the sequence length and window size, denoted as O(n×w), where n is the sequence length and w is the window size.
This localized attention mechanism allows Transformers to capture relevant context and, through multiple layers, build a comprehensive understanding of the entire sequence, similar to the hierarchical feature learning in Convolutional Neural Networks (CNNs). The choice of window size $$w$$ is crucial; smaller windows increase efficiency but may miss long-range dependencies, while larger windows capture more context at the cost of efficiency.
SWA improves Transformer efficiency and adaptability to long sequences by balancing computational cost with the ability to learn from local and extended contexts.
What are some common methods for implementing Sliding Window Attention?
There are a few common methods for implementing SWA in AI. One popular method is to use a fixed window size for all tokens. This is a simple and effective approach, but it may not be optimal for all tasks. Another common method is to dynamically adjust the window size based on the context. This can be more complex to implement, but it can potentially lead to better performance.
What are some benefits of Sliding Window Attention?
There are many benefits to SWA in AI. One benefit is that it can help improve the performance of transformer models by reducing the computational complexity. SWA can also help reduce the memory usage of the models, making them more suitable for deployment on devices with limited computational resources. Additionally, SWA can help improve the scalability of transformer models, allowing them to handle larger datasets and longer sequences.
What are some challenges associated with Sliding Window Attention?
There are many challenges associated with SWA in AI. One challenge is that SWA can reduce the accuracy of a model. This is because SWA limits the attention span of each token, which can lead to a loss of information. Another challenge is that SWA can be a complex process that requires a deep understanding of the model and the attention mechanism. Additionally, not all models can be effectively optimized with SWA, and the effectiveness of SWA can depend on the specific characteristics of the model and the data.
What are some future directions for Sliding Window Attention research?
There are many exciting directions for future research in SWA for AI. One direction is to develop new methods for dynamically adjusting the window size that can reduce the computational complexity and improve the accuracy of the model. Another direction is to develop methods for automatically determining the optimal window size for a given model and data. Additionally, research could focus on developing methods for optimizing models that are currently difficult to optimize with SWA, such as recurrent neural networks.