What is Needle In A Haystack Eval?
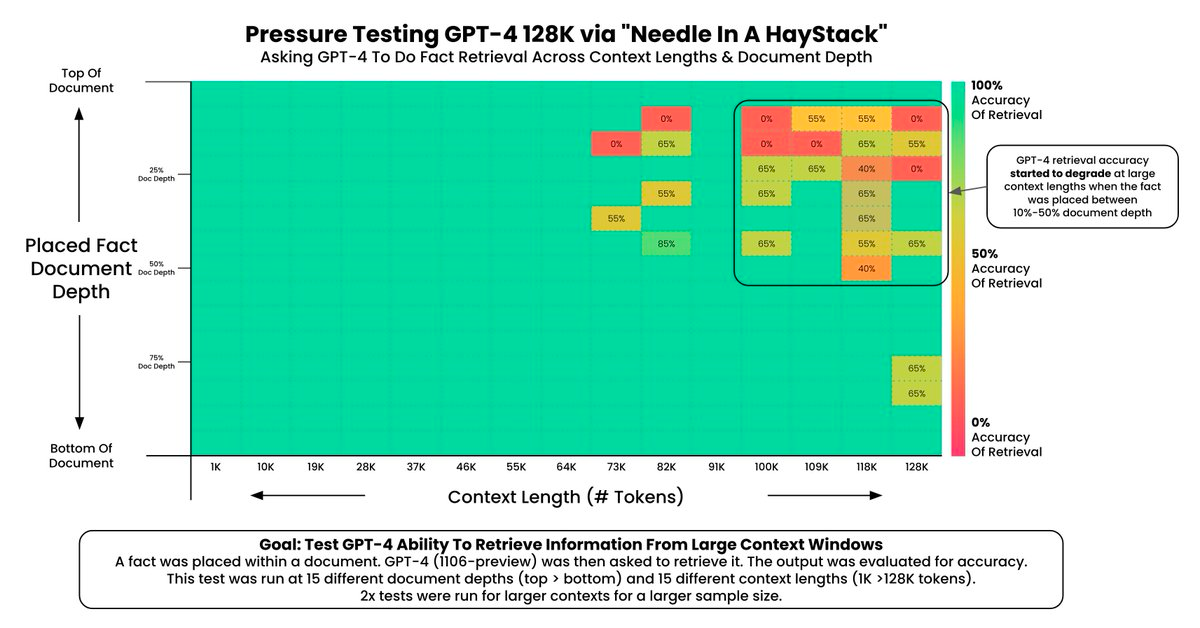
The "Needle In A Haystack" evaluation is a methodology designed to evaluate the performance of Large Language Models (LLMs) in retrieving specific information from extensive texts. This approach tests an LLM's ability to accurately and efficiently extract a particular fact or statement (the "needle") that has been placed within a much larger body of text (the "haystack"). The primary objective is to measure the model's accuracy across various context lengths, thereby assessing its capability in handling long-context information retrieval tasks.
The evaluation process involves embedding a random fact or statement within a long context window and then prompting the model to retrieve this specific piece of information. This setup aims to simulate real-world scenarios where the ability to pinpoint relevant information within extensive documents is crucial. The test is conducted at different context lengths to understand how the model's performance varies with the size of the data it processes.
The "Needle In A Haystack" evaluation is crucial for gauging LLMs' ability to deeply understand and accurately extract information from large datasets, a key skill for tasks like content summarization and detailed document analysis. It has evolved to include complex tests like the multi-needle test, which challenges LLMs with multiple key information points within a dataset, simulating more realistic and demanding data processing scenarios.
This evaluation is not just academically significant; it directly influences LLM development and optimization for practical use. By pinpointing models' strengths and weaknesses in processing extensive information, developers can refine LLM architecture, training, and data management, boosting their effectiveness in various applications, including automated customer support and in-depth data analysis.
Ultimately, the "Needle In A Haystack - Pressure Testing LLMs" stands as a vital benchmark for measuring LLMs' proficiency in one of AI's most challenging tasks: efficiently and accurately extracting relevant information from large data volumes.
How does Needle In A Haystack Eval work?
The Needle In A Haystack evaluation measures Large Language Models' (LLMs) capability to extract specific information from long texts. It embeds "needles" (key information) at random within a text, challenging LLMs to locate and retrieve these details accurately.
A newer feature, the multi-needle test, introduces multiple text snippets ("needles") into a dataset at varying depths. This complexity tests the LLM's ability to process and extract several pieces of information in a single dataset. The evaluation quantifies performance through detailed scoring for each extracted piece of information and calculates an average score, supported by visualization tools for analysis.
When to use Needle In A Haystack Eval
The "Needle In A Haystack" evaluation is particularly useful in scenarios where it's crucial to assess the ability of Large Language Models (LLMs) to extract specific, often critical, information from extensive and complex texts. This evaluation method is designed to challenge LLMs by embedding specific pieces of information, or "needles," within large bodies of text, or "haystacks," and then assessing the models' ability to identify and extract these needles accurately. Here are some scenarios where this evaluation could be particularly beneficial:
-
Information Retrieval Systems — In environments where users need to find specific information within large databases or document collections, such as legal databases, academic research, or extensive archives. The evaluation can help in developing models that improve the efficiency and accuracy of search results by focusing on the ability to pinpoint relevant information amidst vast amounts of data.
-
Content Summarization — For applications that require summarizing long documents into concise, informative abstracts, such as news articles, research papers, or reports. The evaluation can aid in training models to identify and extract the most pertinent information to include in summaries.
-
Customer Support and FAQ Automation — In customer service applications where AI is used to automatically respond to inquiries by extracting answers from detailed product manuals or knowledge bases. The evaluation can help in refining models to provide precise answers to specific questions by effectively navigating through extensive informational resources.
-
Healthcare and Medical Information Systems — For extracting patient-specific information from medical records or identifying relevant case studies and research findings from medical literature. The evaluation can contribute to the development of models that support healthcare professionals by quickly locating critical information needed for diagnosis, treatment planning, or research.
-
Legal and Compliance Document Review — In legal professions where there's a need to review large volumes of documents to find specific case-relevant information, precedents, or regulatory requirements. The evaluation can assist in creating models that streamline the review process by efficiently identifying relevant sections within extensive legal texts.
-
Educational Content Analysis — For educational platforms that aim to create summaries, quizzes, or study guides based on extensive educational materials or textbooks. The evaluation can be used to enhance models' capabilities in extracting key concepts, definitions, and explanations from lengthy educational content.
-
Financial Analysis — In the financial sector, where analysts need to extract specific data points or insights from comprehensive reports, market analyses, or regulatory documents. The evaluation can aid in developing models that assist analysts by quickly locating and extracting the necessary information for decision-making.
By applying the "Needle In A Haystack" evaluation in these scenarios, developers can significantly improve the practical utility of LLMs across various domains, enhancing their ability to serve as effective tools for information extraction and analysis in real-world applications.
Limitations of Needle In A Haystack Eval
The "Needle In A Haystack" evaluation, while a valuable tool for assessing Large Language Models' (LLMs) ability to extract specific information from large datasets, has several limitations:
-
Bias and Variability — The method of selecting and placing "needles" (key information) within the "haystack" (large text corpus) may introduce bias or variability, potentially affecting the evaluation's fairness and consistency. If the "needles" do not represent the diverse information LLMs encounter in real-world applications, the evaluation may not accurately measure an LLM's true capabilities.
-
Complexity and Realism — The evaluation's relevance to real-world applications depends on the complexity of the texts used and the realism of the scenarios. Overly simplified texts or unrealistic scenarios may not provide meaningful insights into LLMs' performance in practical settings.
-
Evaluation Metrics — The current scoring mechanism, focused on keyword presence, may not capture the full complexity of information extraction, such as the context or significance of the information retrieved. This could lead to an incomplete assessment of an LLM's extraction abilities.
-
Adaptability and Scalability — The evaluation must be flexible enough to apply to various domains and data scales. A methodology too rigid or specific to certain data types may not suit LLMs designed for diverse applications or languages.
-
Overfitting and Generalization — There is a risk of LLMs being over-optimized for the evaluation's specific challenges, leading to overfitting. This could result in models that perform well in the evaluation but fail to generalize to different or new tasks.
-
Resource Intensity — The need for extensive texts and a potentially complex setup for embedding "needles" can make the evaluation resource-intensive, limiting its use among developers or researchers with limited computational resources.
-
Interpretability and Actionability — Identifying LLMs' strengths and weaknesses in information extraction is valuable, but translating these findings into actionable insights for model improvement can be challenging without clear guidance on addressing identified limitations.