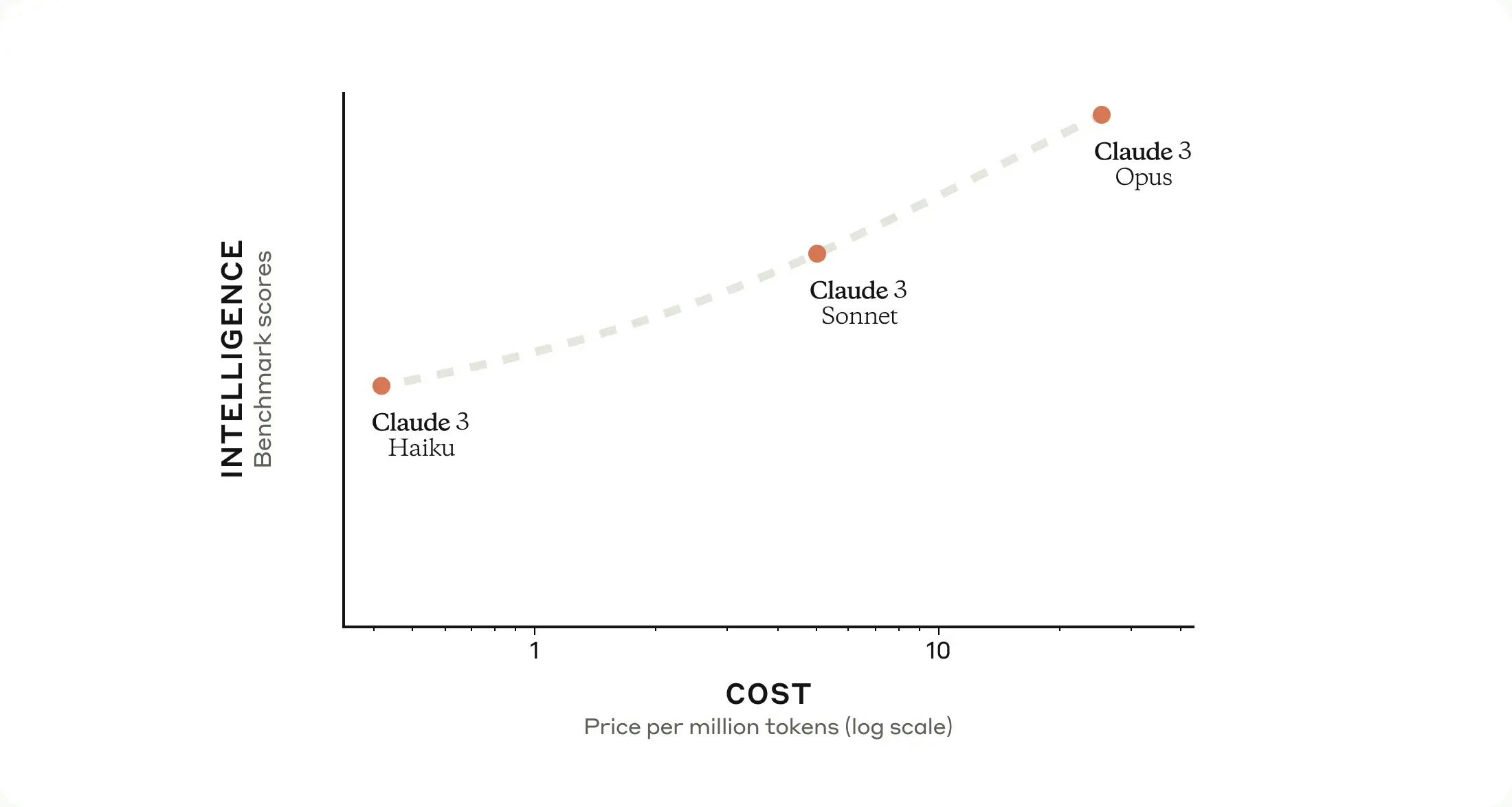
Anthropic recently unveiled the Claude 3 model family, establishing new benchmarks in a variety of cognitive tasks. This lineup includes Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus, each model offering enhanced performance levels for different user needs in terms of intelligence, speed, and cost.
- Claude 3 Haiku — The fastest and most compact model, designed for near-instant responsiveness, particularly suited for simple queries and requests.
- Claude 3 Sonnet — Offers a balance between speed and intelligence, excelling in tasks that require rapid responses like knowledge retrieval or sales automation. It is twice as fast as previous Claude models.
- Claude 3 Opus — The most intelligent model in the family, outperforming peers on benchmarks such as undergraduate and graduate-level knowledge and reasoning, basic mathematics, and more. It exhibits near-human comprehension and fluency in complex tasks.
Availability
Anthropic's Claude 3 series introduces a significant leap in Claude-series capabilities, featuring multimodal understanding that processes both text and visual inputs, including photos, charts, graphs, and technical diagrams. This advancement allows for a broader application in various fields, enhancing the AI's ability to interact with and understand complex information.
Accessible in 159 countries via claude.ai and its API, the Claude 3 models, including Opus and Sonnet, have already begun to impact the market, with plans to introduce Haiku soon. Anthropic claims models stand out in performing live customer chats, auto-completions, and data extraction tasks, demonstrating superior capabilities in benchmark tests when compared to competitors like OpenAI's GPT-4. Early tests leave some room for skepticism.
Claude 3 Benchmark Performance
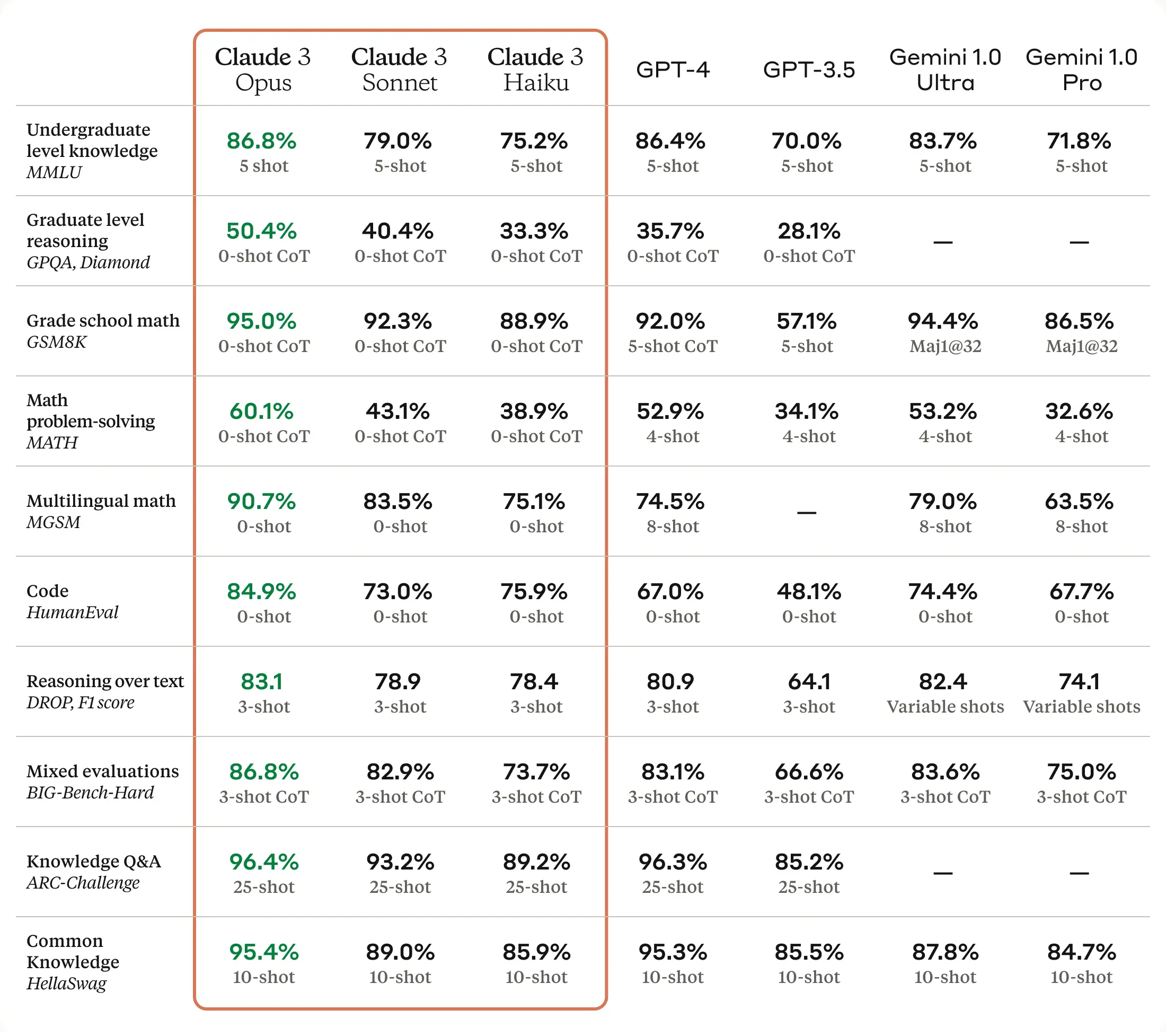
According to Anthropic's published data, the Claude 3 model family has redefined industry standards, outshining predecessors like GPT-4 and Gemini Ultra across various cognitive tasks. The Claude 3 Opus model, the most sophisticated in the lineup, showcases exceptional performance in key AI benchmarks such as MMLU (undergraduate-level knowledge), GPQA (graduate-level reasoning), GSM8K (basic mathematics), and HumanEval (coding), indicating its prowess in understanding complex tasks, mathematical reasoning, and coding, with near-human comprehension and fluency. Additionally, its advanced computer vision capabilities allow for effective information extraction from visual materials.
Comparatively, Claude 3 Opus surpasses leading models from OpenAI and Google in benchmarks, setting a new standard for conversational AI. It excels in undergraduate and graduate knowledge, and grade school math, while the Claude 3 Sonnet model impresses with its ability to understand scientific diagrams, showcasing its utility for enterprise operations and data analysis.
| Test | Claude 3 Opus | GPT-4 | Gemini 1.0 Ultra |
|---|
| Undergraduate level knowledge MMLU | 86.8% 5-shot | 86.4% 5-shot | 83.7% 5-shot |
| Graduate level reasoning GPQA, Diamond | 50.4% 0-shot CoT | 35.7% 0-shot CoT | — |
| Grade school math GSM8K | 95.0% 0-shot CoT | 92.0% 5-shot CoT | 94.4% maj@32 |
| Math problem-solving MATH | 60.1% 0-shot CoT | 52.9% 4-shot | 53.2% 4-shot |
| Multilingual math MGSM | 90.7% 0-shot | 74.5% 8-shot | 79.0% 8-shot |
| Code HumanEval | 84.9% 0-shot | 67.0% 0-shot | 74.4% 0-shot |
| Reasoning over text DROP, F1 score | 83.1% 3-shot | 80.9% 3-shot | 82.4% Variable shots |
| Mixed evaluations BIG-Bench-Hard | 86.8% 3-shot CoT | 83.1% 3-shot CoT | 83.6% 3-shot CoT |
| Knowledge Q&A ARC-Challenge | 96.4% 25-shot | 96.3% 25-shot | — |
| Common Knowledge HellaSwag | 95.4% 10-shot | 95.3% 10-shot | 87.8% 10-shot |
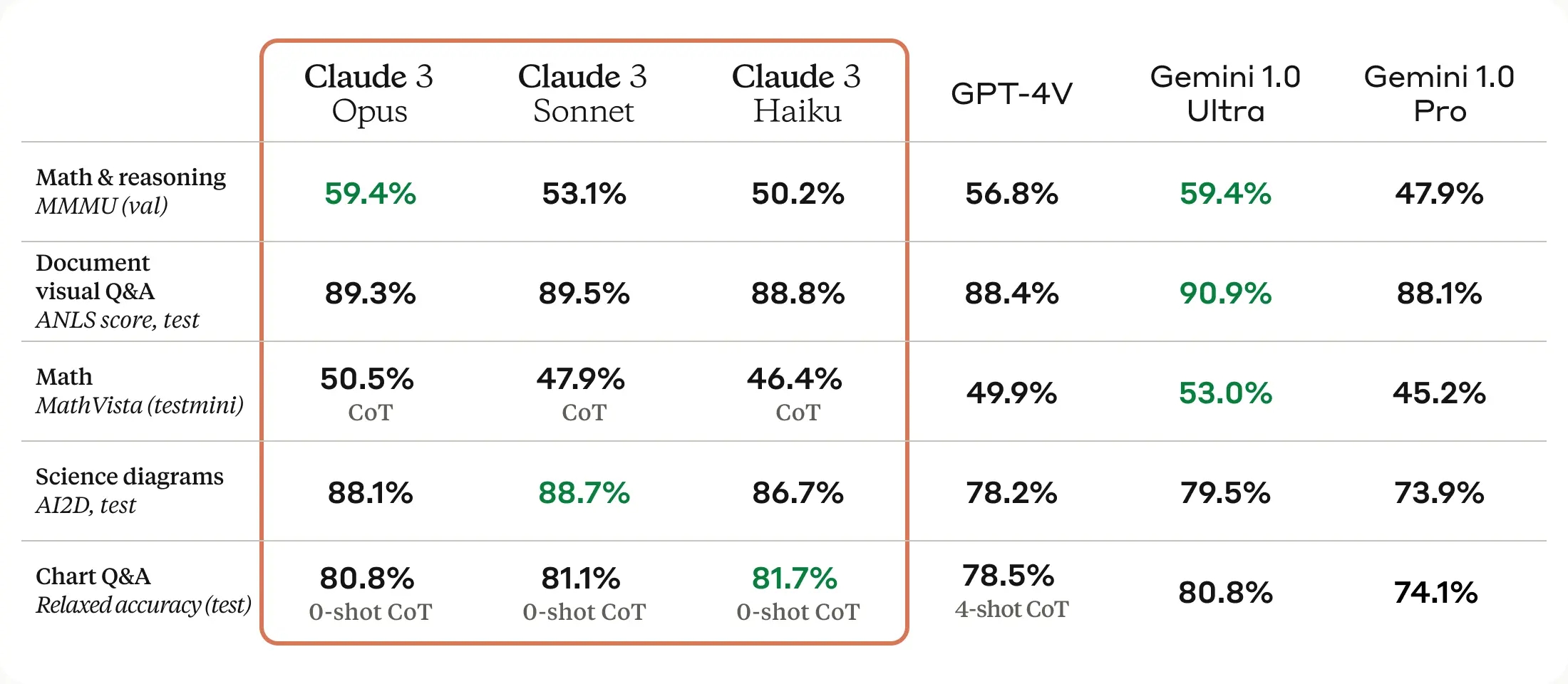
Claude 3's multimodal nature, capable of processing both text and images, significantly expands its application range. Anthropic emphasizes AI safety, actively working to mitigate bias and ensure neutrality, making Claude 3 models a top choice for both enterprise and consumer applications due to their performance, safety features, and broad applicability.
| Test | Claude 3 Opus | GPT-4 Vision | Gemini 1.0 Ultra |
|---|
| Math & reasoning MMMU (val) | 59.4% | 56.8% | 59.4% |
| Document visual Q&A ANLS score, test | 89.3% | 88.4% | 90.9% |
| Math MathVista (testmini) | 50.5% CoT | 49.9% | 53.0% |
| Science diagrams AI2D, test | 88.1% | 78.2% | 79.5% |
| Chart Q&A Relaxed accuracy (test) | 80.8% 0-shot CoT | 78.5% 4-shot CoT | 80.8% |
Claude 3 Model Series
The Claude 3 models, particularly Opus, excel in common AI evaluation benchmarks like MMLU, GPQA, and GSM8K, demonstrating near-human comprehension and fluency in complex tasks. These models also improve in analysis, forecasting, content creation, code generation, and multilingual communication.
The economic potential of Claude 3, particularly the Opus model, has been highlighted in its role as an economic analyst, suggesting its utility in specialized professional domains. When testing ourselves though and comparing against GPT-4 Turbo, we find little evidence to back this claim. With over 10,000 organizations already leveraging Amazon Bedrock for generative AI applications, the introduction of Claude 3 models is poised to further accelerate adoption.
Accuracy
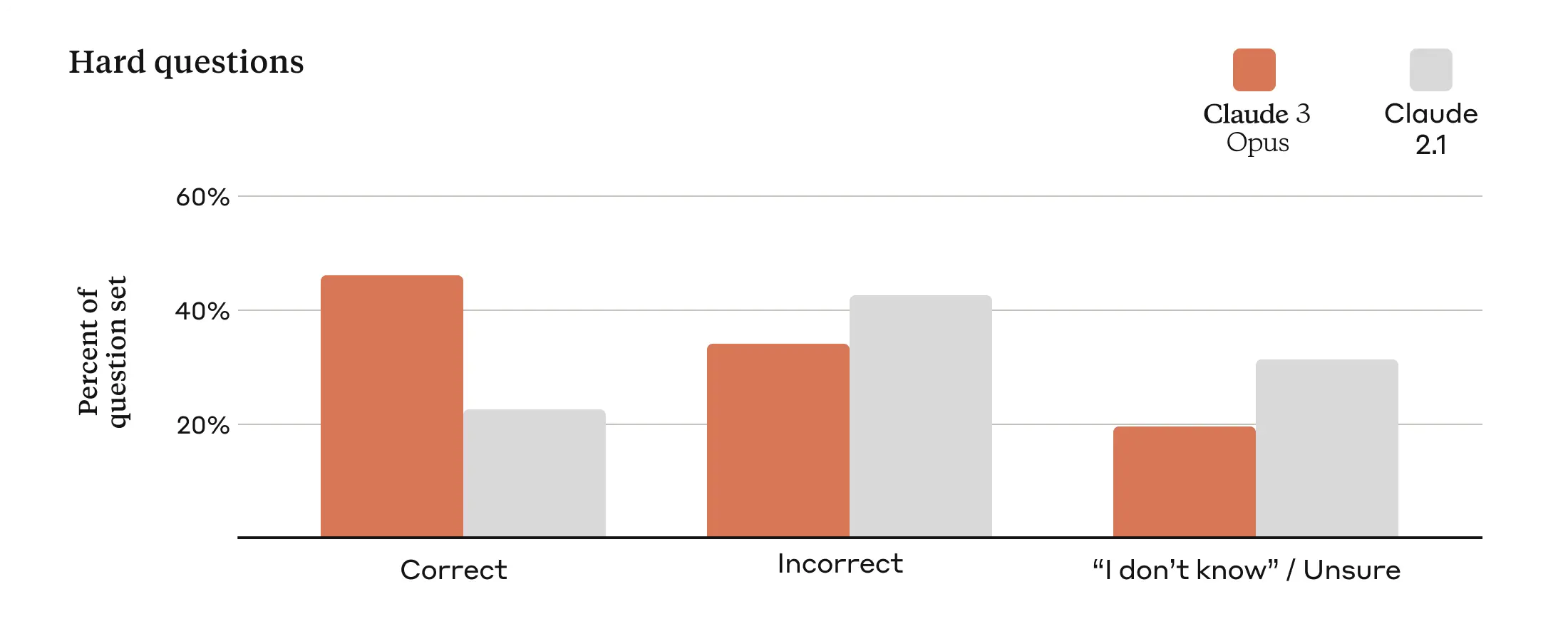
Claude historically has issues with accuracy due to its ability to be very creative. This is most noticed when iterating on complex storylines. For Claude 3, accuracy has also been improved, with Opus showing a twofold increase in correct answers for complex, factual questions. The models will soon support citations for verifying answers.
Context length up to 1 million tokens
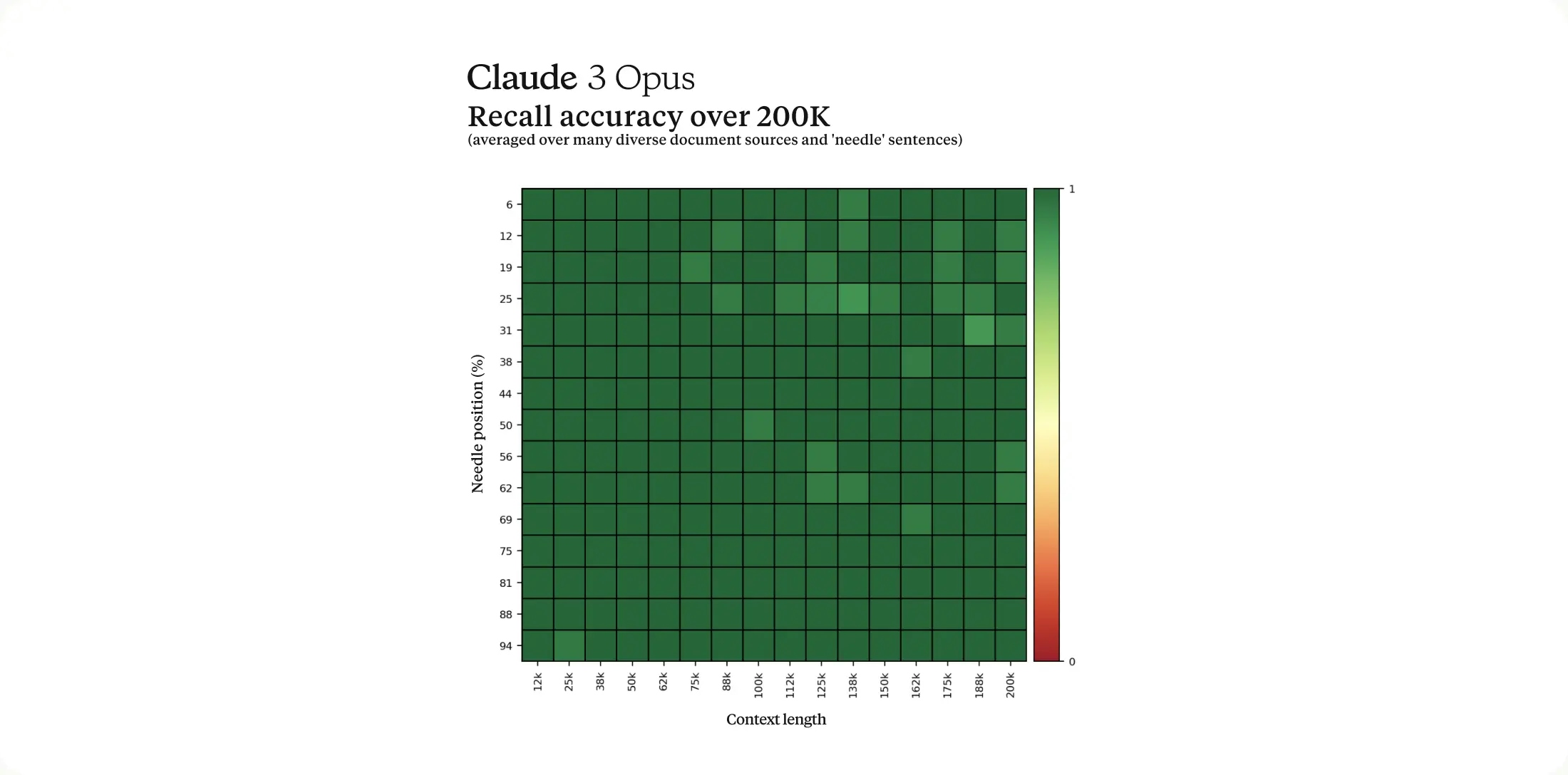
Initially, the Claude 3 models will have a 200K context window, with the potential for inputs over 1 million tokens for select customers. The models demonstrate robust recall capabilities, with Opus achieving near-perfect recall in the 'Needle In A Haystack' evaluation.
Speed
Claude 3 models deliver near-instantaneous results for live chats, auto-completions, and data extraction, with Haiku being the fastest and most cost-effective for its intelligence level. Sonnet offers double the speed of its predecessors with higher intelligence, while Opus matches their speed but with significantly enhanced intelligence.
Vision
These models also feature advanced vision capabilities, processing various visual formats and offering this capability to enterprise customers with visually encoded knowledge bases.
Instruction Following, Reduced Refusals & AI Safety
The Claude 3 models are user-friendly, adept at following complex instructions, and capable of producing structured outputs like JSON for various applications.
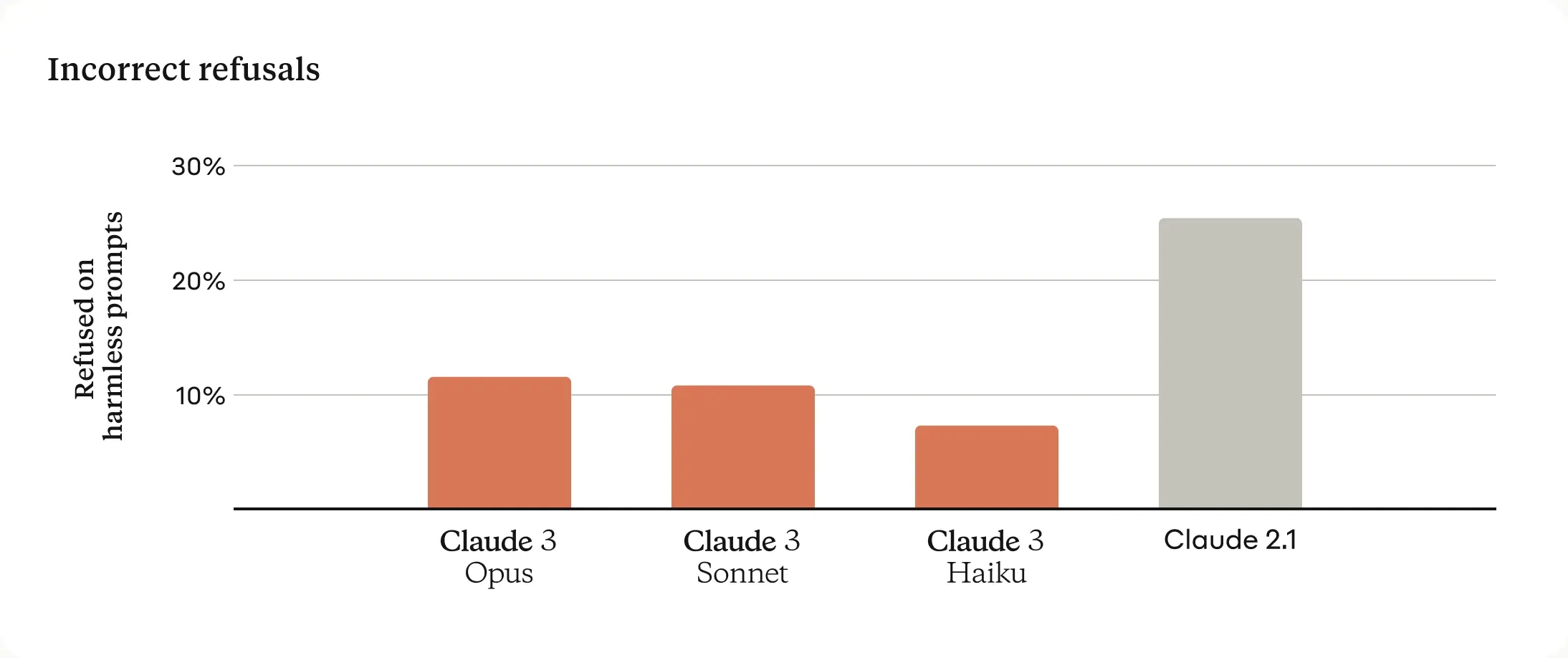
Claude 2 suffers from refusing to answer non-harmful prompts. This is due to the aggressive AI Safety measures deployed by Anthropic. Significant improvements have been made in reducing unnecessary refusals, with the new models showing a better understanding of prompts and less frequent refusals.
Anthropic's commitment to responsible AI development is evident in the Claude 3 models, which prioritize reducing biases and enhancing safety across various risk scenarios. Despite significant advancements, these models currently operate at AI Safety Level 2, under continuous monitoring to evaluate and manage risk levels effectively. The design of Claude 3 models emphasizes neutrality and bias mitigation, achieving a lower bias rate compared to previous versions. They are also equipped with advanced safety features, enabling them to handle sensitive prompts with greater efficacy.
Planned updates
The initial release of the Claude 3 models features a 200K context window, with plans to extend input capabilities up to 1 million tokens for certain customers. To remain competitive with Google Gemini 1.5's upcoming release, we expect to see Anthropic continue to push their generally available context window lengths.
Upcoming enhancements include the introduction of Tool Use (function calling), interactive coding (REPL), and advanced agentic capabilities.
Anthropic claims that the intelligence of the Claude 3 models is far from reaching its peak. Updates will be rolled out frequently in the coming months, focusing on expanding the models' functionalities, especially for enterprise applications and large-scale deployments.
Integration and support for Claude 3 models are streamlined for ease of use, with availability on major platforms like Amazon Bedrock and Google Cloud's Vertex AI. This ease of integration, coupled with significant backing from Amazon and Google, underscores the models' potential for widespread application across industries.
Pricing
Each model has distinct features and costs, catering to different needs:
- Opus is the most intelligent, ideal for complex tasks with a cost of $15 per million tokens for input and $75 for output.
- Sonnet offers a balance of intelligence and speed, suitable for enterprise workloads at $3 per million tokens for input and $15 for output.
- Haiku provides the fastest response for simple queries at $0.25 per million tokens for input and $1.25 for output.
Opus and Sonnet are currently available, with Haiku to follow. Sonnet powers the free experience on claude.ai, with Opus for Claude Pro subscribers. Availability extends to Amazon Bedrock and Google Cloud’s Vertex AI Model Garden.
Anthropic plans frequent updates for the Claude 3 family, introducing features for enterprise use and large-scale deployments. The company aims to align AI development with positive societal outcomes and encourages feedback to enhance Claude's utility.