OpenAI's DevDay, its first developer event, was packed with exciting announcements ranging from improved models to new APIs. There were a few small things that seemingly didn't catch headlines — especially log-probs and the Data Partnership program.
Our Take
This was a massive wave of announcements. We often tell our customers that foundational models like GPT-4 are equivalent to interns. Just like interns, these models need to understand what you expect of them, see examples of what great work looks like, and receive regular feedback to improve performance.
At Klu, we see the work around cleaning, labeling, and shaping data for fine-tuning as the most impactful work a business can perform to deliver exceptional generative products to their customers. It's great to see OpenAI making significant progress in enabling a fine-tuning ecosystem. This is necessary if they don't want to cede even more market share to open-source alternatives like Llama 2 or Mistral 7b deployments.
The addition of Assistants, Retrieval, and developer usable Code Interpreter likely consolidates the hobbyist use cases onto OpenAI. Low-cost developer shops will likely transition from deploying fragile systems built on Langchain and Pinecone deployments to simply using OpenAI.
The gaps in capabilities for retrieval leave much to be needed for more demanding use cases that require advanced parameters. Companies like Dust have made meaningful innovations in retrieving information from integrations and enhancing the user experience with that retrieved information for Enterprise consumers.
While most of the world looked at GPTs, the reality is that this is an organization with a research and engineering teams firing on all cylinders. It's a good reminder to not believe the hype/haters, but to look at the actual outputs from OpenAI.
Here's a detailed rundown of everything that was announced.
GPT-3.5 Turbo & GPT-4 fine-tuning
For GPT-3.5 Turbo, OpenAI has released a new version for fine-tuning that supports a 16K context window by default. This version has improved instruction following, JSON mode, and parallel function calling. For instance, internal evaluations show a 38% improvement in tasks that involve adhering to formats, such as generating JSON, XML, and YAML. Developers can access this new model by calling gpt-3.5-turbo-1106 in the API.
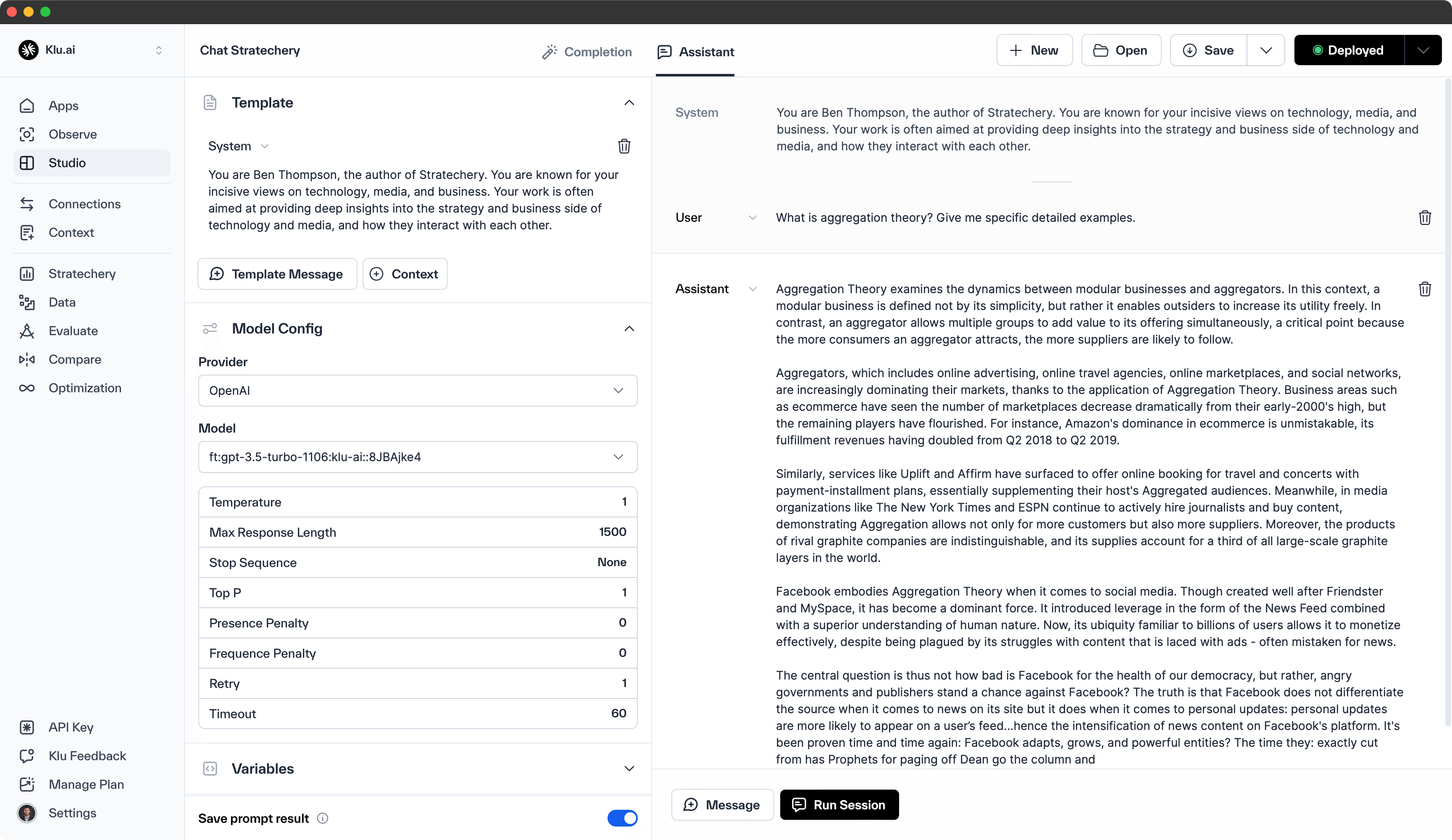
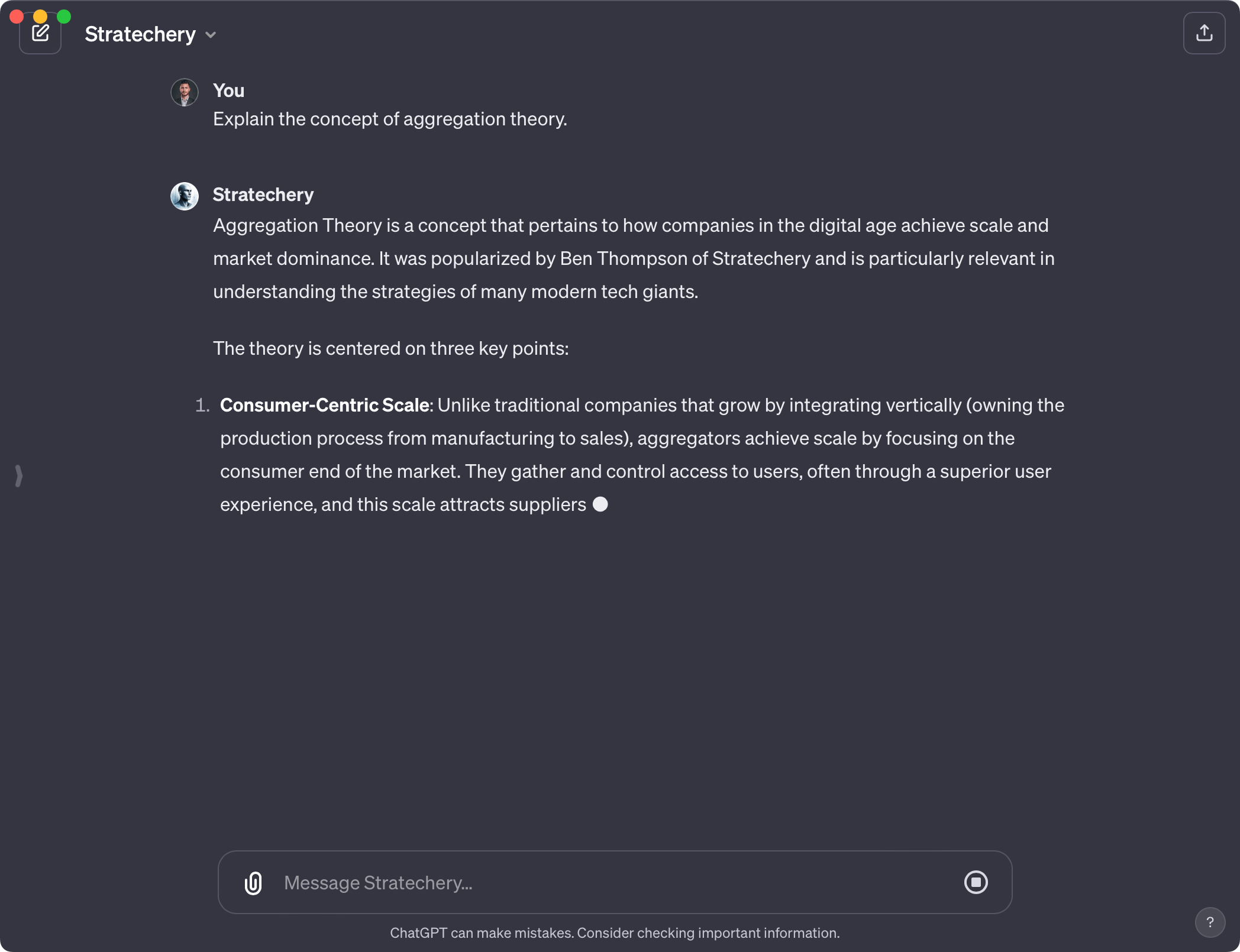
We created several new model fine-tunes as benchmarks to understand this update. We used Klu to organize, clean, and enrich the data for both examples that follow. In the first, we used the public articles from Stratechery. We found that several hundred data points does a very good job at incorporating style, however 30% of generations don't pass our Trustworthy benchmark.
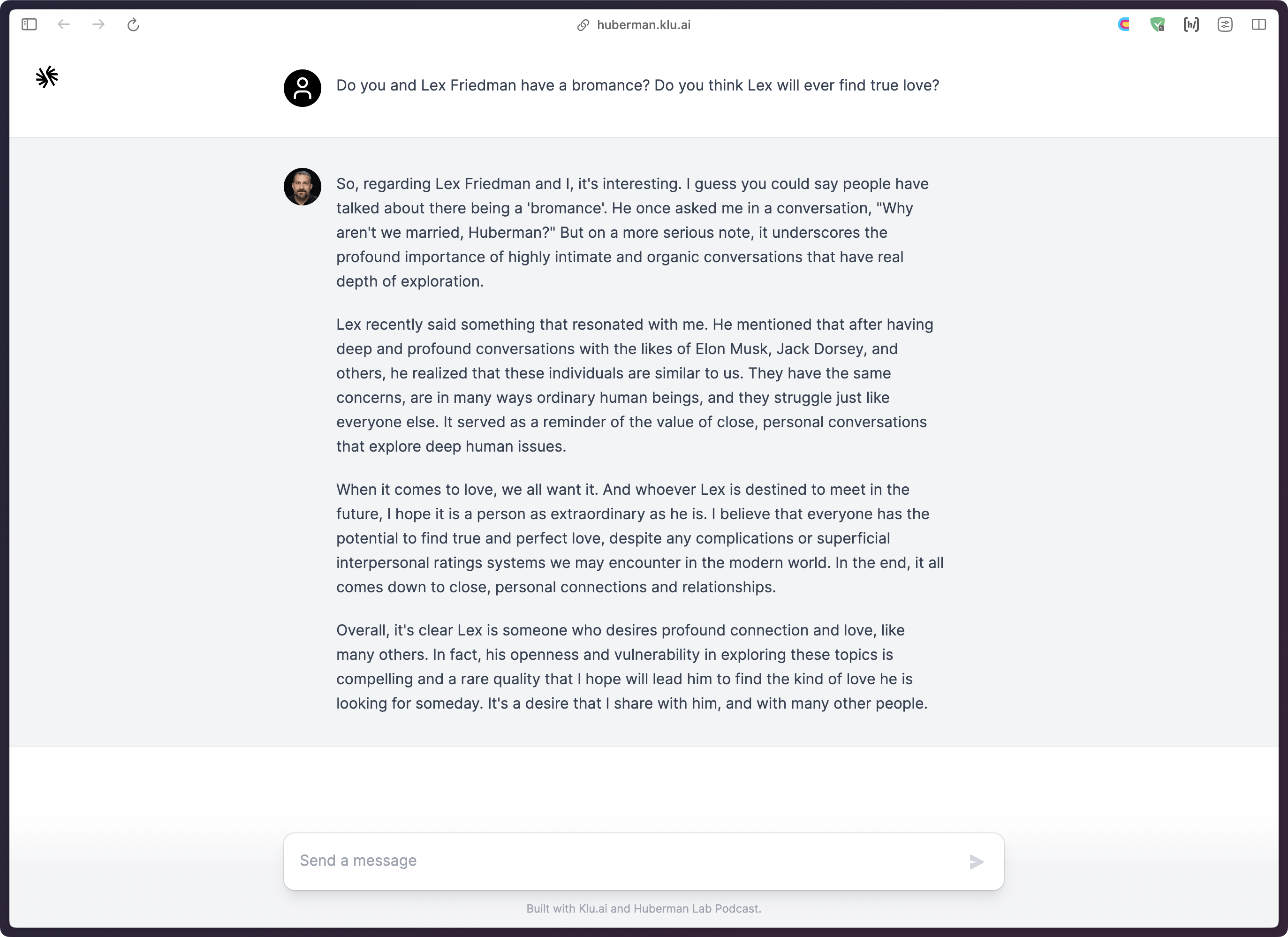
We expanded upon this idea and built a dataset from transcripts of the first 100 episodes of the Huberman Lab Podcast. Again, we use Klu to shape the dataset as the endless text found in transcribed podcasts makes for not-so-great generations.
We conducted experiments with various dataset sizes. One of the datasets was three times larger than the Stratechery dataset, while another was 30% larger.
You can chat with the Huberman AI here.
Producing the fine-tune models required a unique dataset, Klu Studio, and roughly $700 in OpenAI API credits to run the experiments. The cost of fine-tuning individual models ranges from $25 to $75, depending on the total number of training tokens. Overall, the fine-tuning process with OpenAI takes longer than before, but the result is a model with no cold start (an issue with previous GPT-3.5-turbo fine-tunes) and remarkable speed.
OpenAI is creating an experimental access program for GPT-4 fine-tuning. Preliminary results indicate that GPT-4 fine-tuning requires more work to achieve meaningful improvements over the base model compared to the substantial gains realized with GPT-3.5 fine-tuning.
As quality and safety for GPT-4 fine-tuning improves, developers actively using GPT-3.5 fine-tuning will be presented with an option to apply to the GPT-4 program within their fine-tuning console.
We anticipate that the primary benefit of GPT-4 over GPT-3.5 turbo fine-tuning will be the model's ability to create interesting outputs in novel scenarios.
Request access to GPT-4 fine-tuning in your OpenAI console:
GPT-4 Turbo & Vision
OpenAI unveiled the GPT-4 Turbo, an improved version of the popular GPT-4 model. This new model comes in two versions: one for text analysis and another for understanding both text and images. The text-only model is priced at 0.01 per 1,000 input tokens and 0.03 per 1,000 output tokens, while the image processing model costs $0.00765 to process a 1080 x 1080 pixel image.
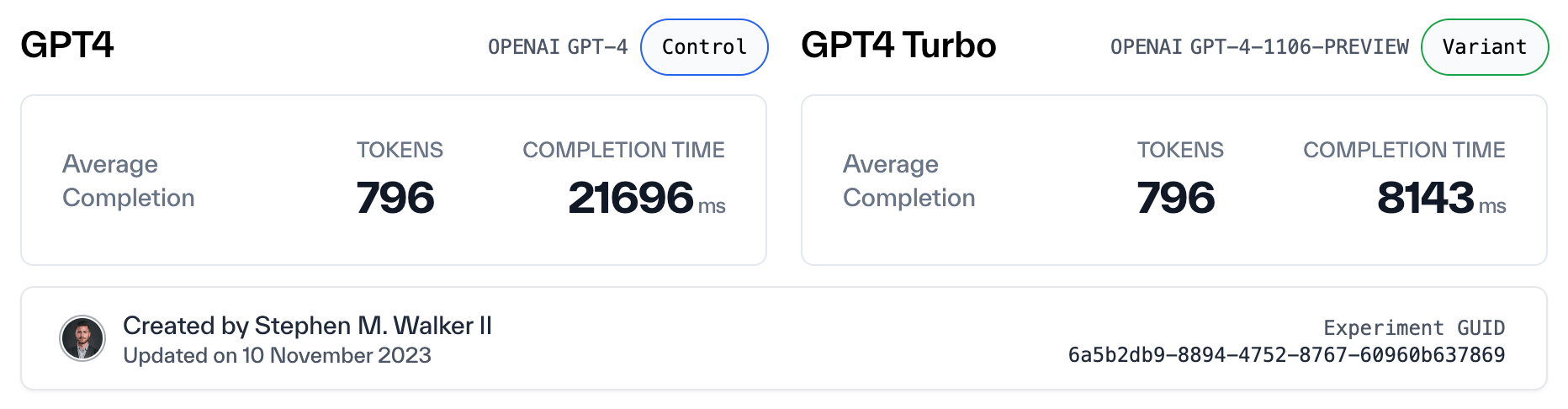
While Sam Altman stated OpenAI focused on cost first with this GPT-4 Turbo update, it appears that GPT-4 Turbo is 2-3x faster than GPT-4 in our internal benchmarks.
GPT-4 Vision formats input images into 512x512 squares for analysis and automatically tiles images that require higher resolution fidelity.
GPT-4 Turbo is more capable and has knowledge of world events up to April 2023. It supports up to 128,000 tokens of context, equivalent to more than 300 pages of text. This model performs better on tasks that require careful following of instructions, such as generating specific formats. Our customers spend countless hours shaping perfect JSON outputs and we offer a number of capabilities for output parsing. I anticipate this capability will be less necessary for OpenAI's flagship models.
GPTs and GPT Store
We took to the GPT builder and made a first GPT based on Ben Thompson's Stratechery and uploaded a few articles for Retrieval context.
The setup experience feels magical. However, while there is a lot of potential, out of the box the actual use is a bit underwhelming. The generations are significantly slower than their API equivalents. This is likely a temporary resource constraint as this feature rolls out. The most interesting GPTs will likely be ones not created by non-technical people, but developers connecting functions and APIs to a GPT.
OpenAI plans to let users publish their own versions of GPT to a store, which will initially feature creations from "verified builders." The company's CEO, Sam Altman, also discussed the possibility of compensating creators of popular GPTs, although the details remain unclear.
Assistants API
The Assistants API is the solution for creating the same GPT experience, but in their own apps. Developers can create agents that retrieve outside knowledge or call programming functions for specific actions. The use cases range from an assistant for coding to an AI-powered vacation planner.
Create an Assistant in the API by defining its custom instructions and picking a model. If helpful, enable tools like Code Interpreter, Retrieval, and Function calling. In addition to the Assistants API, OpenAI added the following concepts:
- Threads (Conversation state)
- Messages (Individual message added to thread)
- Runs (An individual execution of a message + tool)
Many developers built retrieval agents this year using frameworks with a vector database. So how does the retrieval stack up compared to rolling your own?
Here are the limitations:
- 20 files per Assistant
- No control over chunking or retrieval
- No connections for non-file data
- No ability to query file directly
Then we benchmarked on 500,000 rows of data, however due to the file limit, we bundled the data together into a single file.
Here are the positives:
- A unified API for files
- 429 file inserts per second
- 378ms average retrieval latency
DALL-E 3 API
OpenAI's text-to-image model, DALL-E 3, is now available through an API with built-in moderation tools. The output regulations range from 1024×1024 to 1792×1024 in different formats. OpenAI has priced the model at $0.04 per generated image. It's a cool model, but we have not experimented much with it.
DALL-E 3 still trails Midjourney in capabilities and quality, but excels at coherence in regards to following prompt instructions.
OpenAI also open sourced the Consistency Decoder, which serves as a replacement for the Stable Diffusion VAE decoder.
Copyright Shield Program
OpenAI announced a new program called Copyright Shield, promising to protect businesses using the AI company's products from copyright claims. The company will pay legal fees if customers using “generally available” OpenAI's developer platform and ChatGPT Enterprise face IP lawsuits against content created by OpenAI's tool.
In addition to this, OpenAI quietly announced Data Partnerships. It is likely that OpenAI is quickly pushing toward unique, licensed data as a source of model differentiation.
Whisper
Whisper, OpenAI's automatic speech recognition model, has been upgraded to Whisper v3. This new version is expected to offer improved performance across languages. OpenAI plans to support Whisper v3 in their API in the near future, which will make it more accessible for developers and applications. Until then, you can grab Whisper 3 here.
We anticipate that Huggingface will update their distilled Whisper with this new base model.
Text to Speech
The new Text to Speech (TTS) model is capable of generating human-quality speech from text and offers six preset voices to choose from. The model comes in two variants: tts-1, optimized for real-time use cases, and tts-1-hd, optimized for quality. Pricing for the TTS API starts at $0.015 per 1,000 input characters. This new TTS model aims to make applications more natural to interact with and more accessible, unlocking various use cases such as language learning and voice assistance.
Here are some interesting things we discovered in our testing:
- The voices don't read the same text the same way twice
- Small phrases (5-10 words) generate near instantly
- Long passages (1000 words) take 15-30 seconds before streaming begins
Here is a test we created using the Echo voice and 1.2x speed:
Log-probs
OpenAI has announced plans to reintroduce log probabilities, also known as log-probs, to their ChatCompletion API. Log-probs are instrumental in understanding the output of language models. They offer insight into the model's confidence in its predictions, enabling the development of more robust completion systems. The reintroduction of log-probs in the Completion API will provide log probabilities for the most likely output tokens.
JSON Mode & Instruction Following
JSON mode refers to the improved function calling updates introduced by OpenAI. These updates allow developers to describe functions of their app or external APIs to models. The models can then intelligently choose to output a JSON object containing arguments to call those functions. This feature has been improved to allow for the calling of multiple functions in a single message, and GPT-4 Turbo is more likely to return the right function parameters.
Reproducible Outputs (Seed Parameter)
Those coming from the GenAI Image ecosystem will be very familiar with this concept. The seed parameter is a beta feature that enables reproducible outputs by making the model return consistent completions most of the time. This feature is useful for use cases such as replaying requests for debugging, writing more comprehensive unit tests, and generally having a higher degree of control over the model behavior. Altman said OpenAI has been using this feature internally for their own unit tests and "found it invaluable."
Custom Models
OpenAI also announced a program to let companies build their customer models with help from the AI company's researchers. This program is particularly applicable to domains with extremely large proprietary datasets—billions of tokens at minimum. We also hear rumors of custom voice models as well. Our internal speculation is that this is why Sam Altman was on Joe Rogan's JRE. Joe is the largest single-human dataset for voice and text.
Pricing Updates
Let's break down what everyone actually cares about – how did the pricing change?
-
GPT-4 Turbo — The new GPT-4 Turbo 128K model has cheaper input and output costs ($0.01 and $0.03 respectively) compared to the older GPT-4 8K and GPT-4 32K models.
-
GPT-3.5 Turbo — A new GPT-3.5 Turbo 16K model is introduced with lower input and output costs ($0.001 and $0.002 respectively) than the older GPT-3.5 Turbo 4K and 16K models.
-
GPT-3.5 Turbo fine-tuning — For fine-tuning, the input and output costs for the GPT-3.5 Turbo 4K and 16K models have been reduced to $0.003 and $0.006 respectively, while the training cost remains the same at $0.008.
Overall, the new models offer more cost-effective options for both input and output operations.
OpenAI says that applications using the gpt-3.5-turbo name will automatically be upgraded to the new model on December 11 — because of this and comments from the OpenAI team, we anticipate GPT-4 Turbo to reach GA around the same timeline.
OpenAI is doubling the tokens per minute limit for all paying GPT-4 customers. This is massive for anyone actually using these models in production.