What is OpenAI GPT-4 Turbo?
GPT-4 Turbo is the latest and more powerful version of OpenAI's generative AI model, announced in November 2023. It provides answers with context up to April 2023, whereas prior versions were cut off at January 2022. GPT-4 Turbo has an expanded context window of 128k tokens, allowing it to process over 300 pages of text in a single prompt. This makes it capable of handling more complex tasks and longer conversations.
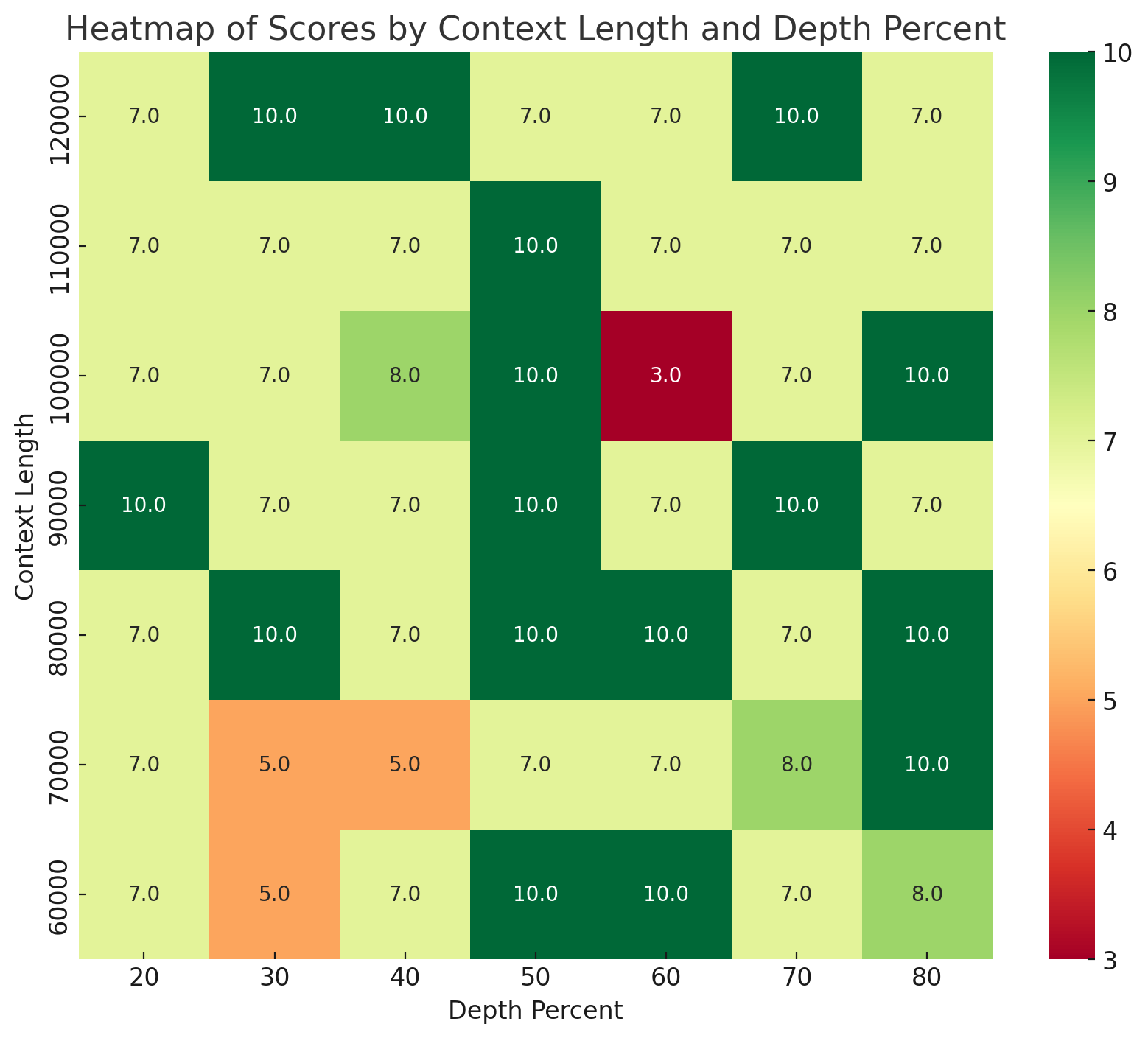
In the benchmarks conducted by Klu.ai, it was observed when dealing with 60-128k input tokens that GPT-4 Turbo tends to more consistently retrieve facts from the latter 50% of the input.
Benchmarks tested with randomly sampled facts with no intermediate libraries (LangChain, LlamaIndex, etc) or context systems (including Klu Context).
Some of the key features and improvements of GPT-4 Turbo include:
- Updated knowledge base — GPT-4 Turbo has knowledge of events up to April 2023, making it more up-to-date than previous versions.
- Larger context window — GPT-4 Turbo has a 128k token context window, allowing it to process more text in a single prompt.
- Lower cost — GPT-4 Turbo is cheaper to run for developers, with input tokens costing $0.01 per 1,000 tokens and output tokens costing $0.03 per 1,000 tokens.
- Multimodal capabilities — GPT-4 Turbo supports DALL-E 3 AI-generated images and text-to-speech, offering six preset voices to choose from.
- Customizable chatbots — OpenAI introduced GPTs, allowing users to create custom versions of ChatGPT for specific purposes.
GPT-4 Turbo is available in preview for developers and will be released to all users in January 2024.
Features
OpenAI GPT-4 Turbo is an enhanced version of the GPT-4 model, which is a large multimodal model capable of accepting both text and image inputs and producing text outputs. GPT-4 Turbo distinguishes itself with several key improvements:
-
Updated Knowledge Base — It has been trained with information up to April 2023, allowing it to provide more current context in its responses.
-
Extended Context Window — GPT-4 Turbo features a 128K token context window, which is equivalent to over 300 pages of text, enabling it to understand and remember much larger chunks of information in a single prompt.
-
Cost Efficiency — Running GPT-4 Turbo as an API is reported to cost one-third less than GPT-4 for input tokens, making it more affordable for developers to integrate into their applications.
-
Performance — The model is optimized for faster response times and supports longer inputs, which can be particularly beneficial for complex queries that require processing large amounts of data.
-
Multimodal Capabilities — While initially released with text capabilities, GPT-4 Turbo also started allowing image inputs in September 2023, enhancing its versatility.
-
Accessibility — GPT-4 Turbo is available via an API preview and is accessible to all paying developers who can use the model by passing a specific model name in the API.
-
Safety Measures — OpenAI has implemented safety measures to reduce harmful and biased outputs, and encourages feedback on problematic outputs to continuously improve the model's safety and reliability.
GPT-4 Turbo is part of OpenAI's continuous effort to advance AI technology, providing developers with a powerful tool that can handle more nuanced instructions and perform a wider range of tasks, including specific coding language outputs like XML or JSON. OpenAI plans to release a stable, production-ready Turbo model in the near future.
What are the differences between gpt-4 and gpt-4 turbo?
GPT-4 Turbo is an enhanced version of the GPT-4 model, with several key differences that make it distinct:
-
Knowledge Base — GPT-4 Turbo is trained with data up to April 2023, providing it with a more current understanding of world events, compared to GPT-4's knowledge cutoff in September 2021.
-
Context Window — The context window of GPT-4 Turbo is significantly larger at 128,000 tokens, which allows it to process and remember much more information at once than GPT-4's 8,192 tokens.
-
Cost Efficiency — GPT-4 Turbo offers a more cost-effective solution for developers, with input tokens being three times cheaper and output tokens costing half as much as those for GPT-4.
-
Performance — While both models are designed for high performance, GPT-4 Turbo is optimized for faster response times and can handle longer inputs, which is beneficial for complex queries.
-
Multimodal Capabilities — GPT-4 Turbo has been updated to handle both text and image inputs, whereas GPT-4 was initially text-only before it also gained multimodal capabilities.
-
Accessibility — GPT-4 Turbo is available via an API preview to all paying developers, whereas GPT-4 has broader availability to users with API access.
-
Safety Measures — Both models include safety measures to mitigate harmful and biased outputs, but GPT-4 Turbo emphasizes continuous improvement based on user feedback.
In essence, GPT-4 Turbo is designed to be a more advanced, cost-effective, and capable version of GPT-4, with improvements in knowledge, context understanding, and performance.
How can developers access gpt-4 turbo?
All Klu accounts come with FREE access to gpt-4 turbo for prototyping. Additionally, to access GPT-4 Turbo, developers need to have an OpenAI API account and existing GPT-4 access. The model can be accessed by passing gpt-4-1106-preview as the model name in the API.
Here's a Python example of how to make a request to the GPT-4 Turbo API:
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4-1106-preview",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
]
)