Glossary term
What are GPTs?
OpenAI's GPTs, are a new way to create custom versions of ChatGPT for specific purposes.
Read term
Zephyr 7B, spécifiquement le modèle Zephyr-7B-β, est le deuxième de la série Zephyr de modèles de langage développés par Hugging Face. C'est une version affinée du modèle Mistral-7B-v0.1, formée sur un mélange de jeux de données publiquement disponibles et synthétiques en utilisant l'Optimisation Directe des Préférences (DPO).
| Model | Arena Elo rating | MT-bench (score) | MMLU | License |
|---|---|---|---|---|
| Zephyr 7b | 1049 | 7.34 | 73.5 | Apache 2.0 |
Le modèle est principalement conçu pour agir comme un assistant utile, capable de générer des conversations fluides, intéressantes et utiles. Vous pouvez discuter avec une version en ligne ici.
Si vous voulez rapidement exécuter le modèle Zephyr, nous vous recommandons de commencer par Ollama.
Si vous voulez utiliser le modèle hors ligne, vous pouvez utiliser Ollama.ai. Après avoir installé l'outil, vous pouvez télécharger les fichiers nécessaires et utiliser la commande ollama run zephyr dans votre terminal pour exécuter le modèle.
Pour télécharger et utiliser le modèle Zephyr 7B, vous pouvez suivre ces étapes :
pip3 install huggingface-hubhuggingface-cli. Par exemple, pour télécharger le modèle zephyr-7b-beta.Q4_K_M.gguf, vous pouvez utiliser la commande suivante :huggingface-cli download TheBloke/zephyr-7B-beta-GGUF zephyr-7b-beta.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks FalseCette commande téléchargera le modèle dans le répertoire courant.
pipeline() de la bibliothèque Transformers pour exécuter le modèle. Si vous utilisez une version de Transformers <= v4.34, vous devrez l'installer à partir de la source.Veuillez noter que le modèle Zephyr 7B est un grand modèle de langage et nécessite des ressources informatiques substantielles pour fonctionner. Nous recommandons d'utiliser un Macbook Pro M2 ou ultérieur. Assurez-vous que votre machine dispose de suffisamment de ressources pour gérer le modèle.
Si vous voulez utiliser le modèle dans une interface web, vous pouvez utiliser l'outil text-generation-webui. Vous pouvez télécharger le modèle en utilisant l'interface de l'outil en entrant le repo du modèle (TheBloke/zephyr-7B-beta-GGUF) et le nom du fichier (zephyr-7b-beta.Q4_K_M.gguf) dans la section "Download Model". Une fois le modèle téléchargé, vous pouvez le charger et l'utiliser pour la génération de texte.
Zephyr 7B est un modèle de type GPT de 7 milliards de paramètres, principalement formé en anglais. Il est sous licence MIT et est affiné à partir du modèle Mistral-7B-v0.1. Le modèle a été formé en utilisant une technique appelée Optimisation Directe des Préférences (DPO), qui s'est avérée efficace pour améliorer les performances des modèles de langage.
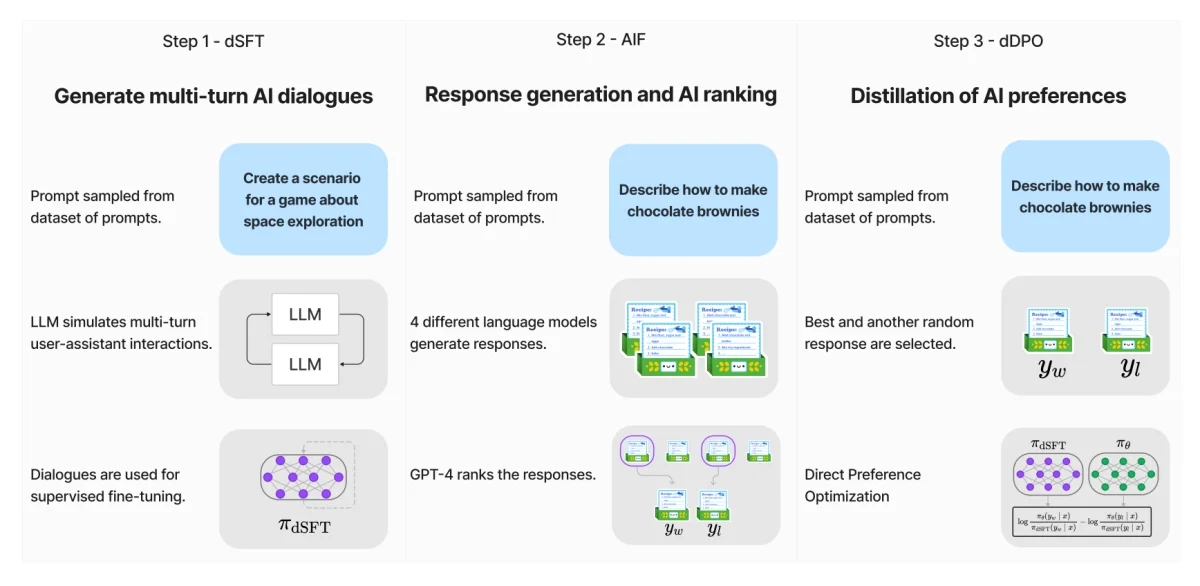
Le processus d'affinage de Zephyr 7B a impliqué trois étapes clés :
Au moment de sa sortie, Zephyr-7B-β était le modèle de chat 7B le mieux classé sur les benchmarks MT-Bench et AlpacaEval. Il a obtenu un score de 7,34 sur MT-Bench et un taux de victoire de 90,60% sur AlpacaEval, surpassant de nombreux modèles plus grands.
En comparaison avec des modèles ouverts plus grands comme Llama2-Chat-70B, Zephyr-7B-β a montré de solides performances sur plusieurs catégories de MT-Bench. Cependant, il est à noter que ses performances peuvent être en retrait par rapport aux modèles propriétaires sur des tâches plus complexes comme la codage et les mathématiques.
Zephyr 7B peut être utilisé dans une variété d'applications, y compris :
Cependant, il est important de noter que Zephyr 7B peut produire des sorties problématiques, surtout lorsqu'il est invité à le faire. Par conséquent, il est recommandé de l'utiliser uniquement à des fins éducatives et de recherche.
Bien que Zephyr 7B ait montré des performances impressionnantes, il a certaines limitations. Il n'a pas été aligné sur les préférences humaines avec des techniques comme RLHF ou déployé avec un filtrage en boucle des réponses comme ChatGPT. Cela signifie que le modèle peut produire des sorties problématiques, surtout lorsqu'il est invité à le faire.
La taille et la composition du corpus utilisé pour former le modèle de base (Mistral-7B-v0.1) sont inconnues, mais il est probable qu'il ait inclus un mélange de données Web et de sources techniques comme des livres et du code.
Zephyr 7B représente une avancée significative dans le développement des modèles de langage. Malgré ses limitations, il a montré des performances impressionnantes dans divers benchmarks, ce qui en fait un outil précieux pour une large gamme d'applications. Comme pour tout modèle d'IA, il est important de l'utiliser de manière responsable et d'être conscient de son potentiel à générer des sorties problématiques.
More terms
Glossary term
Glossary term
Collaborate with your team on reliable Generative AI features.
Want expert guidance? Book a 1:1 onboarding session from your dashboard.