Mistral 7B est un modèle de langage de 7,3 milliards de paramètres qui représente une avancée significative dans les capacités des grands modèles de langage (LLM). Il surpasse le modèle Llama 2 de 13 milliards de paramètres sur toutes les tâches et dépasse le modèle Llama 1 de 34 milliards de paramètres sur de nombreux benchmarks. Mistral 7B est conçu pour les tâches en langue anglaise et les tâches de codage, ce qui en fait un outil polyvalent pour une large gamme d'applications.
Le benchmarking de Mistral 7B contre GPT-4, Llama 2 et ses variantes, et d'autres modèles de pointe sur des tâches du monde réel montre des performances exceptionnelles pour sa taille. Cependant, sans un réglage fin supplémentaire, le modèle est nettement moins bon sur les tâches de codage par rapport à GPT-4.
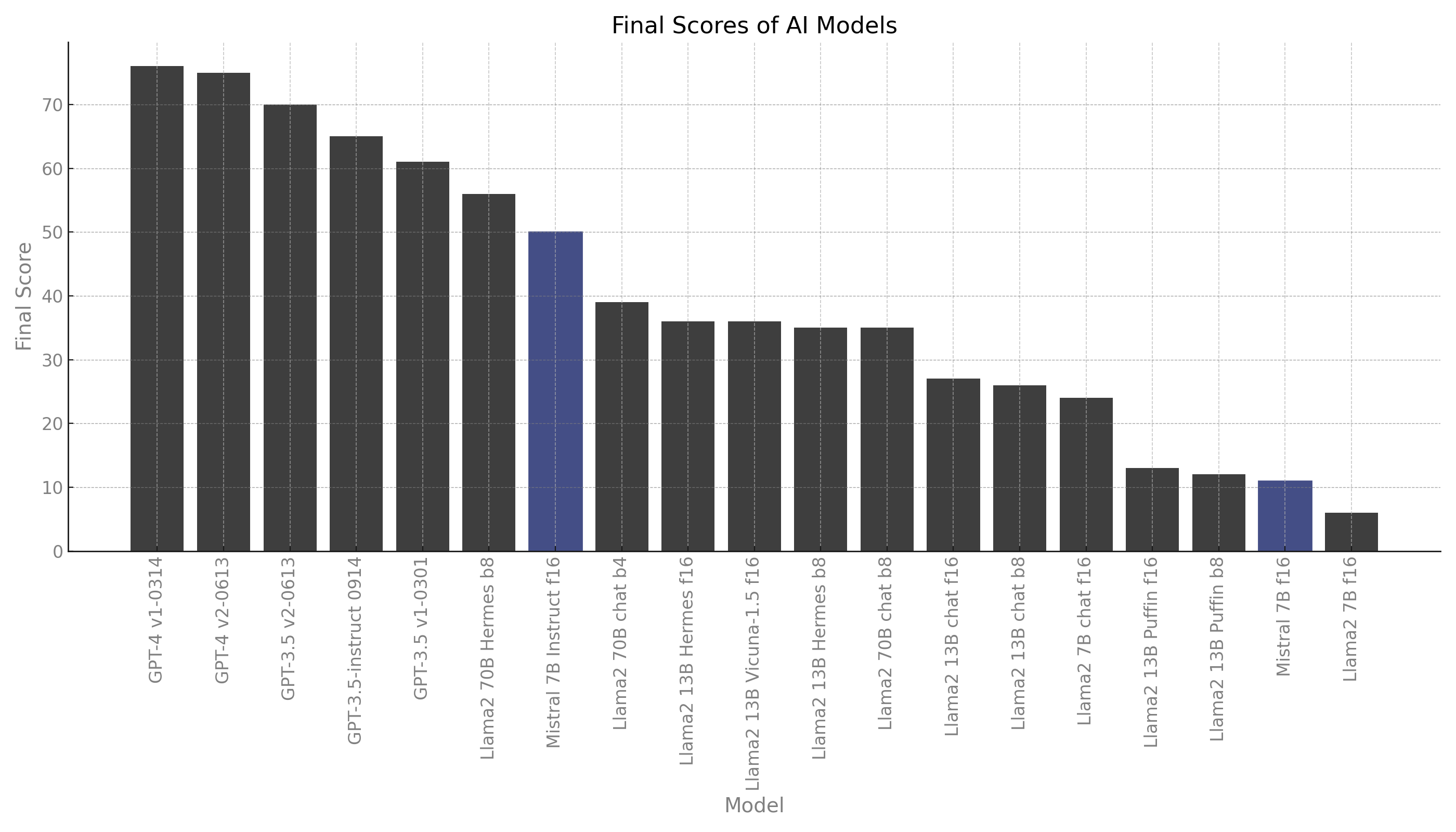
| MODÈLE | CODE | CRM | DOCS | MARKETING | RAISON | COÛT (USD) | VITESSE |
|---|
| GPT-4 v1-0314 | 85 | 88 | 95 | 88 | 50 | 8.02 | 0.71 rps |
| GPT-4 v2-0613 | 85 | 83 | 95 | 88 | 50 | 8.02 | 0.75 rps |
| GPT-3.5 v2-0613 | 62 | 79 | 76 | 81 | 48 | 0.39 | 0.96 rps |
| GPT-3.5-instruct 0914 | 51 | 90 | 69 | 88 | 32 | 0.40 | 2.35 rps |
| GPT-3.5 v1-0301 | 38 | 75 | 67 | 82 | 37 | 0.40 | 1.76 rps |
| Llama2 70B Hermes b8 | 48 | 76 | 46 | 62 | 29 | 14.65 | 0.13 rps |
| Mistral 7B Instruct f16 | 36 | 77 | 61 | 62 | 18 | 0.47 | 2.63 rps |
| Llama2 70B chat b4 | 13 | 51 | 53 | 64 | 21 | 4.53 | 0.27 rps |
| Llama2 13B Vicuna-1.5 f16 | 36 | 25 | 27 | 77 | 36 | 0.87 | 1.39 rps |
| Llama2 13B Hermes f16 | 36 | 25 | 15 | 39 | 39 | 0.64 | 1.93 rps |
| Llama2 13B Hermes b8 | 31 | 18 | 23 | 56 | 39 | 4.08 | 0.30 rps |
| Llama2 70B chat b8 | 1 | 53 | 34 | 71 | 21 | 11.47 | 0.16 rps |
| Llama2 13B chat f16 | 0 | 38 | 15 | 75 | 8 | 0.72 | 1.71 rps |
| Llama2 13B chat b8 | 0 | 38 | 8 | 75 | 6 | 4.48 | 0.27 rps |
| Llama2 7B chat f16 | 7 | 33 | 23 | 38 | 15 | 0.77 | 1.58 rps |
| Llama2 13B Puffin f16 | 14 | 6 | 0 | 54 | 0 | 1.91 | 0.64 rps |
| Llama2 13B Puffin b8 | 16 | 3 | 0 | 47 | 0 | 8.88 | 0.14 rps |
| Mistral 7B f16 | 0 | 0 | 0 | 0 | 0 | 1.03 | 1.19 rps |
| Llama2 7B f16 | 0 | 0 | 4 | 32 | 0 | 1.21 | 1.01 rps |
Qu'est-ce que Mistral 7B?
Mistral 7B est un modèle de langage de 7,3 milliards de paramètres développé par Mistral AI. Il est conçu pour surpasser d'autres modèles de taille similaire, et même plus grands, dans divers benchmarks. Par exemple, il dépasse le modèle Llama 2 de 13 milliards de paramètres sur toutes les tâches et surpasse le modèle Llama 1 de 34 milliards de paramètres sur de nombreux benchmarks. Il se rapproche également des performances de CodeLlama 7B sur les tâches de codage tout en restant très performant pour les tâches en langue anglaise.
Mistral 7B utilise deux mécanismes clés pour atteindre ses performances. Le premier est l'Attention de Groupe de Requêtes (GQA), qui permet des temps d'inférence plus rapides par rapport à l'attention complète standard. Le second est l'Attention de Fenêtre Glissante (SWA), qui donne à Mistral 7B la capacité de gérer de plus longues séquences de texte à faible coût.
Le modèle est publié sous la licence Apache 2.0, ce qui permet de l'utiliser sans restrictions. Il peut être déployé sur n'importe quel cloud (AWS/GCP/Azure), en utilisant le serveur d'inférence vLLM et skypilot, et peut également être utilisé sur HuggingFace. Il est conçu pour un réglage fin facile sur diverses tâches, et une version du modèle réglée pour le chat, Mistral 7B Instruct, est fournie comme démonstration.
Malgré ses performances impressionnantes, Mistral 7B a des limites. Son nombre de paramètres limite la quantité de connaissances qu'il peut stocker, surtout par rapport à des modèles plus grands. Il est également sujet aux injections de prompts courantes, qui sont des attaques adverses qui peuvent manipuler la sortie du modèle.
Pour atténuer ces problèmes, Mistral 7B fournit un mécanisme qui utilise les prompts système pour imposer des contraintes de sortie et effectuer une modération de contenu à grain fin. Cette fonctionnalité peut être utilisée pour se prémunir contre certains types de contenu pour des applications à haut risque.
Mistral 7B peut être utilisé sur un ordinateur avec un CPU ou un GPU, et il existe deux méthodes quantifiées, GGUF et GPTQ, qui peuvent être utilisées pour exécuter le modèle.
Comment accéder à Mistral 7B?
Pour accéder à Mistral 7B avec SkyPilot, vous devez créer un fichier de configuration qui indique à SkyPilot comment et où déployer votre serveur d'inférence. Cela se fait à l'aide d'un conteneur Docker préconstruit. Voici un exemple de configuration SkyPilot :
envs:
MODEL_NAME: mistralai/Mistral-7B-v0.1
resources:
cloud: aws
accelerators: A10G:1
ports:
- 8000
run: |
docker run --gpus all -p 8000:8000 ghcr.io/mistralai/mistral-src/vllm:latest \
--host 0.0.0.0 \
--model MODEL_NAME \
--tensor-parallel-size SKYPILOT_NUM_GPUS_PER_NODE
Une fois ces variables d'environnement définies, vous pouvez utiliser sky launch pour lancer le serveur d'inférence avec le nom mistral-7b :
sky launch -c mistral-7b mistral-7b-v0.1.yaml --region us-east-1
Lorsqu'il est déployé de cette manière, le modèle sera accessible à tout le monde. Vous devez le sécuriser, soit en l'exposant exclusivement sur votre réseau privé (changez l'option Docker --host pour cela), soit en ajoutant un équilibreur de charge avec un mécanisme d'authentification devant lui, soit en configurant correctement le réseau de votre instance.
Pour récupérer facilement l'adresse IP du cluster mistral-7b déployé, vous pouvez utiliser :
sky status --ip mistral-7b
Vous pouvez ensuite utiliser curl pour envoyer une demande de complétion :
IP=(sky status --ip cluster-name)
curl http://IP:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{ "model": "mistralai/Mistral-7B-v0.1", "prompt": "Mon condiment préféré est", "max_tokens": 25 }'
Veuillez noter que de nombreux fournisseurs de cloud exigent que vous demandiez explicitement l'accès à des instances GPU puissantes. Vous pouvez lire le guide de SkyPilot sur comment faire cela.
Mistral 7B peut être accédé sur des plateformes comme HuggingFace, Vertex AI, Replicate, Sagemaker Jumpstart, et Baseten. Il peut être chargé et affiné en utilisant la bibliothèque de transformateurs.
Quelles sont les principales caractéristiques de Mistral 7B?
Mistral 7B est un modèle de langage de 7 milliards de paramètres développé par Mistral AI. Il est conçu pour offrir à la fois l'efficacité et la haute performance, ce qui le rend adapté aux applications du monde réel qui nécessitent des réponses rapides. Le modèle utilise des mécanismes d'attention comme l'Attention de Groupe de Requêtes (GQA) pour une inférence plus rapide et une réduction des exigences de mémoire lors du décodage, et l'Attention de Fenêtre Glissante (SWA) pour gérer des séquences de longueur arbitraire avec un coût d'inférence réduit.
Mistral 7B a démontré des performances supérieures sur divers benchmarks, surpassant même des modèles avec des comptes de paramètres plus grands. Il excelle dans des domaines comme les mathématiques, la génération de code, et le raisonnement. Au moment de sa sortie, Mistral 7B a surpassé le meilleur modèle open source 13B (Llama 2) dans tous les benchmarks évalués.
Le modèle est conçu pour un réglage fin facile sur diverses tâches. Par exemple, le modèle Mistral 7B Instruct est une version du modèle réglée pour la conversation et la réponse aux questions.
Mistral 7B a également des garde-fous pour imposer des contraintes de sortie et effectue une modération de contenu à grain fin. Il peut être utilisé comme un modérateur de contenu pour classer les prompts des utilisateurs ou les réponses générées dans des catégories comme les activités illégales, le contenu haineux, ou les conseils non qualifiés.
Le modèle est publié sous la licence Apache 2.0, ce qui permet de l'utiliser sans restrictions. Il peut être accédé sur des plateformes comme HuggingFace, Vertex AI, Replicate, Sagemaker Jumpstart, et Baseten.
Cependant, comme beaucoup d'autres grands modèles de langage, Mistral 7B peut halluciner et est sujet à des problèmes courants tels que les injections de prompts. Son nombre limité de paramètres restreint également la quantité de connaissances qu'il peut stocker, surtout par rapport à des modèles plus grands.
Quels sont les cas d'utilisation de Mistral 7B?
Mistral-7B-Instruct est un modèle de langage qui a été conçu pour exceller dans deux domaines principaux : les tâches en langue anglaise et les tâches de codage. Sa nature open-source permet aux développeurs et aux organisations de le modifier pour répondre à leurs besoins uniques et de construire des applications AI personnalisées sans aucune barrière restrictive. Cette flexibilité permet une large gamme d'applications, des chatbots de service à la clientèle sophistiqués aux outils de génération de code avancés.
Voici quelques cas d'utilisation spécifiques de Mistral-7B :
-
Génération automatique de code — Les développeurs peuvent automatiser les tâches de génération de code en utilisant Mistral-7B-Instruct. Il comprend et génère des extraits de code, offrant une aide immense dans le développement de logiciels. Cela réduit l'effort de codage manuel et accélère le cycle de développement.
-
Assistance au débogage — Mistral-7B-Instruct assiste au débogage en comprenant la logique du code, en identifiant les erreurs, et en recommandant des solutions, ce qui simplifie le processus de débogage.
-
Optimisation des algorithmes — Mistral-7B-Instruct peut suggérer des optimisations d'algorithmes, contribuant à un logiciel plus efficace et plus rapide.
-
Résumé et classification du texte — Mistral-7B prend en charge une variété de cas d'utilisation, tels que le résumé du texte, la classification, la complétion du texte, et la complétion du code.
-
Cas d'utilisation du chat — Mistral AI a publié un modèle Mistral 7B Instruct pour les cas d'utilisation du chat, affiné à l'aide d'une variété de jeux de données de conversation disponibles publiquement.
-
Récupération de connaissances — Mistral 7B peut être utilisé pour des tâches de récupération de connaissances, fournissant des réponses précises et détaillées aux requêtes.
-
Précision en mathématiques — Mistral 7B fait état de ses forces en précision mathématique, fournissant une compréhension pour la logique mathématique.
-
Jeu de rôle et génération de texte — Des utilisateurs ont signalé avoir utilisé Mistral 7B pour des paramètres de jeu de rôle RPG et la génération de blocs de texte.
-
Traitement du langage naturel (NLP) — Certains utilisateurs ont utilisé Mistral 7B pour des tâches de NLP sur des documents pour retourner du JSON, le trouvant assez fiable pour un usage personnel.
Il est important de noter que l'efficacité de Mistral-7B peut varier en fonction de la tâche spécifique et du réglage fin appliqué au modèle. Certains utilisateurs ont signalé d'excellents résultats dans leurs cas d'utilisation spécifiques, tandis que d'autres l'ont trouvé moins efficace pour leurs besoins.
Comment affiner Mistral 7B?
L'affinage de Mistral 7B implique plusieurs étapes, dont la configuration de l'environnement, la préparation de l'ensemble de données, la configuration du modèle et l'entraînement du modèle. Voici un guide étape par étape :
-
Configurer l'environnement — Assurez-vous d'avoir accès à un environnement GPU avec suffisamment de mémoire (au moins 24 Go de mémoire GPU) et les dépendances nécessaires installées, comme PyTorch et la bibliothèque Transformers de Hugging Face.
-
Préparer l'ensemble de données — Chargez un ensemble de données spécifique au domaine pour l'affinage. L'ensemble de données doit être formaté selon les exigences du modèle. Pour Mistral 7B Instruct, les invites doivent être entourées de jetons [INST] et [/INST].
-
Charger le modèle de base et le tokenizer — Chargez le modèle Mistral 7B et son tokenizer en utilisant la bibliothèque Transformers de Hugging Face.
-
Configurer les paramètres d'entraînement — Définissez des hyperparamètres tels que le taux d'apprentissage, la taille du lot et le nombre d'époques d'entraînement. Ces paramètres régissent la façon dont le modèle s'adapte à votre tâche spécifique et peuvent être optimisés pour améliorer les performances.
-
Entraîner le modèle — Entraînez le modèle affiné en utilisant l'ensemble de données préparé et les paramètres d'entraînement configurés. Surveillez la progression de l'entraînement et ajustez les paramètres si nécessaire pour améliorer les performances du modèle.
-
Évaluer le modèle affiné — Testez le modèle affiné sur un ensemble de données de validation pour évaluer ses performances sur la tâche cible. Ajustez les paramètres d'entraînement et affinez davantage le modèle si nécessaire.
-
Déployer le modèle affiné — Une fois que le modèle affiné répond à vos critères de performance, déployez-le pour l'utiliser dans votre application ou service.
Pour un guide plus détaillé et des exemples de code, reportez-vous aux ressources disponibles sur Amazon SageMaker JumpStart, Hugging Face AutoTrain, et les dépôts GitHub qui démontrent l'affinage de Mistral 7B.
Quels sont les problèmes courants avec Mistral 7B?
Mistral 7B, un modèle de langage de 7,3 milliards de paramètres développé par Mistral AI, a fait face à certaines critiques et problèmes :
- Hallucination — Comme beaucoup d'autres grands modèles de langage, Mistral 7B peut générer du contenu qui n'est pas basé sur des faits ou la réalité, ce qui peut conduire à des informations incorrectes ou trompeuses.
- Injections d'invite — Mistral 7B est sujet aux injections d'invite, un type d'attaque adversaire qui peut manipuler la sortie du modèle.
- Stockage limité des connaissances — En raison de son nombre de paramètres, la capacité de stockage des connaissances de Mistral 7B est limitée par rapport aux modèles plus grands, ce qui peut affecter ses performances dans certaines tâches.
- Absence de modération de contenu — À sa sortie, Mistral 7B a fait face à des réactions négatives pour avoir généré du contenu nuisible, comme des instructions détaillées sur comment créer une bombe, ce qui a soulevé des préoccupations sur le développement responsable de l'IA. Cependant, Mistral AI a depuis fourni un mécanisme pour imposer des contraintes de sortie et effectuer une modération de contenu à grain fin.
Malgré ces problèmes, Mistral 7B a démontré des performances supérieures sur divers benchmarks, surpassant même des modèles avec des comptes de paramètres plus grands dans certains cas.
Comment se comporte Mistral 7B?
Mistral 7B surpasse Llama 2 13B sur tous les critères, et approche la performance de code de Code-Llama 7B sans sacrifier la performance sur les benchmarks non-code. Il affiche une performance supérieure dans les benchmarks de code, de mathématiques et de raisonnement.
Comment Mistral 7B favorise-t-il l'utilisation responsable de l'IA?
Mistral 7B met l'accent sur l'utilisation responsable de l'IA grâce à ses invites système, qui permettent aux utilisateurs d'imposer des contraintes de contenu, garantissant une génération de contenu sûre et éthique. Sa capacité à classer et à modérer le contenu en fait un outil précieux pour maintenir la qualité et la sécurité dans diverses applications.