LLMOpsガイド
by Stephen M. Walker II, 共同創設者 / CEO
LLMOps(大規模言語モデルオペレーション)とは?
LLMOpsは、機械学習オペレーション(MLOps)の中で、大規模言語モデル(LLM)を管理することに特化した分野です。OpenAIのGPT-4、GoogleのPalm、MistralのMixtralなどのLLMを生産環境で管理します。
LLMOpsは、LLMの展開を効率化し、スケーラビリティを確保し、関連するリスクを軽減します。LLMが直面する特有の課題に取り組み、深層学習と膨大なデータセットを活用してテキストを理解、生成、予測します。LLMの台頭は、これらの高度なAIアルゴリズムを開発し実装する企業の成長を促進しました。
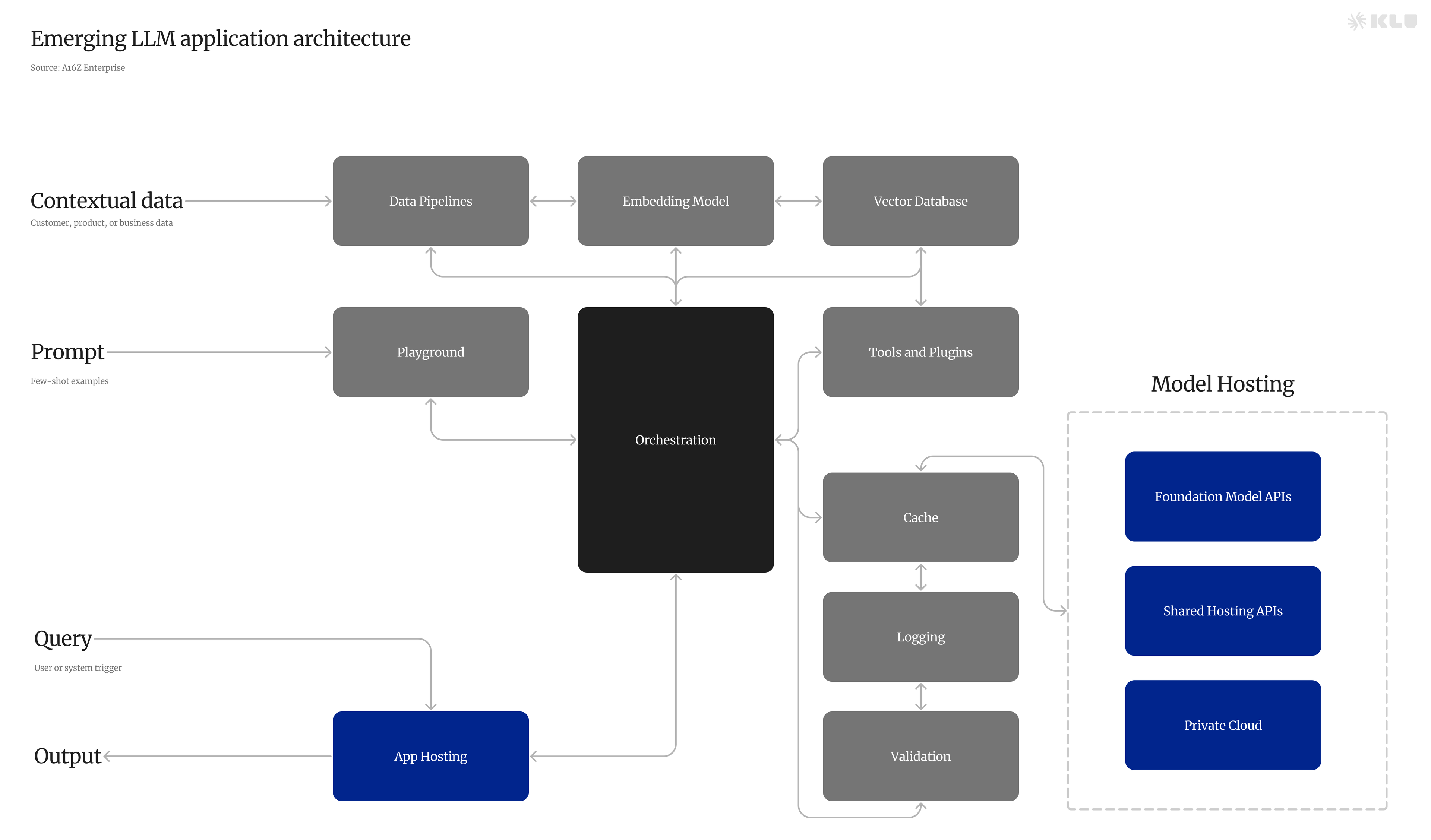
LLMOpsの主要な要素には、データ管理、プロンプトエンジニアリング、モデルの微調整、モデルの展開、モデルの監視などがあります。これらのプロセスを同期させ、協力して機能させるためには、データエンジニアリングからデータサイエンス、MLエンジニアリングまでのチーム間の協力と厳格な運用が必要です。
モデル展開後、LLMの使用はLLMOpsの一部であり、モデルのパフォーマンスを維持し、潜在的な問題に対処するために監視と更新を行います。
アプリケーション開発者向けのLLMOpsの重要な側面には以下が含まれます:
- プロンプトエンジニアリング — 言語モデルの応答を導くためのよく設計されたプロンプトを作成します。
- LLMアプリのパフォーマンス最適化 — チャットボット、プログラミングアシスタント、変革的プロンプトなどのアプリケーションに生成プロンプトを統合し、最適化します。
- LLM評価 — モデルとアプリのパフォーマンスを定期的に評価し、品質を確保し、問題に対処します。
- LLM可観測性 — モデル展開後にリアルタイムのデータポイントを収集し、モデルパフォーマンスの潜在的な劣化を検出します。
データおよびMLチーム向けのLLMOpsは、クラシックなMLOpsを直接反映しており、以下を含みます:
- 監視 — モデルのパフォーマンス、基盤性、トークン消費、インフラストラクチャのパフォーマンスを継続的に追跡します。
- 微調整 — モデルの重みとハイパーパラメータを調整してパフォーマンスを向上させ、特定のユースケースに対応します。
- 展開 — モデルをウェブサービスやモバイルアプリなどのアプリケーションに統合します。
- メンテナンス — モデルを最新の状態に保ち、効果的にするために、新しいデータで更新し、必要に応じて微調整します。
LLMOpsは、LLMを生産環境で展開および管理するための重要な側面であり、効率的なLLMの展開、監視、およびメンテナンスを可能にし、最適なパフォーマンスとユーザー満足度を確保します。
このガイドでは、LLMOpsの実践的な側面を掘り下げ、その主要な要素、ベストプラクティス、実際のアプリケーションを探ります。専門家がどのように出力を整え、ユーティリティを向上させ、これらの強力なモデルの一貫した高性能を維持するかを明らかにします。
重要なポイント
-
クラシックなMLワークフロー — データ管理と前処理、モデルの微調整/適応、監視/メンテナンスは、効果的なLLMOpsワークフローのコアコンポーネントです。
-
最適化 — プロンプトエンジニアリングやリトリーバル拡張生成などの技術は、LLMをタスクに適応させ、知識のギャップを埋めるためのベストプラクティスです。
-
ベンチマーク — 定期的なモデル評価/ベンチマークは、時間をかけて最適なLLMパフォーマンスを確保します。プライバシーとコンプライアンス規制の遵守も重要です。
-
オーケストレーション — オーケストレーションプラットフォーム、フレームワーク、ライブラリ、可観測性ツールは、効率的なLLMの開発、展開、メンテナンスをスケールで促進します。
LLMOpsの出現
機械学習モデル、特にLLMの使用が増加する中で、効率的な管理と展開戦略が必要とされています。LLM、または基盤モデルは、大規模なテキストデータセットでトレーニングするために深層学習を使用し、文法、意味、文脈を学習します。このテキスト関係を理解する能力により、LLMは文中の次の単語を予測することができ、現代のAIシステムに不可欠な存在となっています。
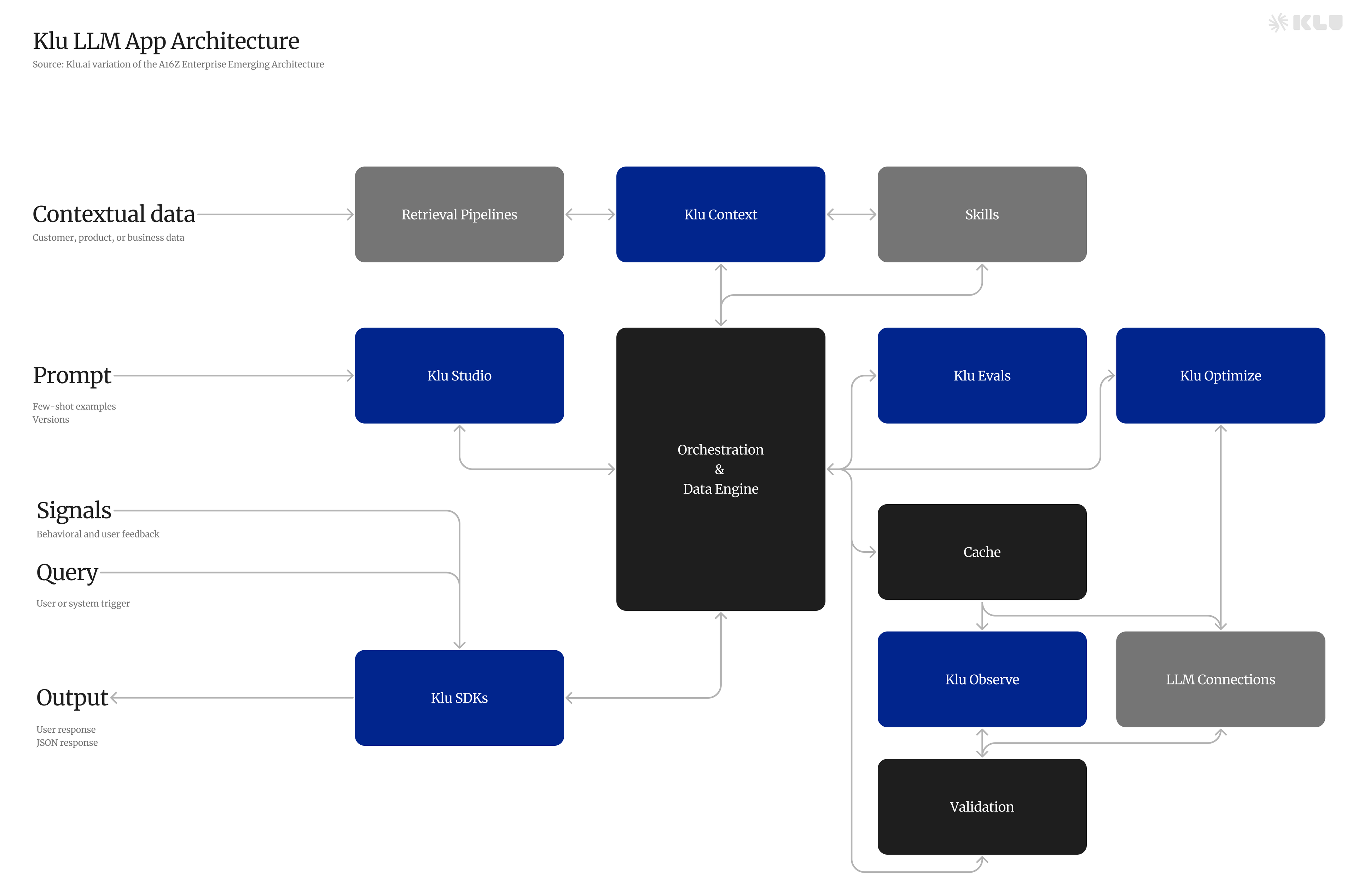
しかし、彼らのライフサイクルを管理し、さまざまなタスクでのパフォーマンスを最適化するには、専門的な技術とツールが必要であり、その役割を果たすのがLLMOpsです。
LLMOpsは、LLMのライフサイクルを管理する包括的なアプローチであり、これらのモデルを生産環境で展開および維持するための特定の要件に対応します。事前にトレーニングされた言語モデルを特定のタスクにカスタマイズしながら、データ保護を確保することに焦点を当てています。
LLMOpsは、ユーザーが以下を行うための協力的な環境を促進します:
LLMの課題
大規模言語モデル(LLM)は、自然言語処理において変革的であり、チャットボット、コンテンツ生成、機械翻訳などのアプリケーションを支えています。これらのモデルは、より自然で直感的なコミュニケーション能力を提供することで、人間と機械の相互作用を強化します。
しかし、LLMはその効果を最大化するために対処すべき重要な課題に直面しています。
-
言語の曖昧さ — 自然言語の曖昧さは、LLMによる誤解を招き、誤った出力をもたらす可能性があります。これに対処するには、LLMが文脈を深く理解し、正確な仮定を行う能力が必要です。
-
幻覚とバイアス — LLMは、根拠のない出力(幻覚)を生成したり、トレーニングデータからのバイアスを反映したりすることがあります。これらの問題を軽減するには、バランスの取れたデータセットを使用し、データ拡張や正則化などの技術を適用することが必要です。
-
計算コストと遅延 — LLMの計算要求は高コストと潜在的な遅延をもたらし、ユーザーエクスペリエンスやLLMの実用的な展開に影響を与える可能性があります。計算効率の最適化が重要です。
-
完了の整合性 — LLMの出力をユーザーの意図に合わせることは困難です。これには、洗練されたアルゴリズムとモデル、および生成された完了が関連性と正確性を持つことを保証するためのタスクの明確な理解が必要です。
-
タスクの熟練度 — LLMは、特定のタスクに対して最適に機能するために微調整を必要とすることがよくあります。このプロセスは複雑であり、モデルとタスクの両方についての徹底的な知識が必要です。
-
知識のギャップ — LLMは最新の知識やドメイン固有の専門知識を持っていない可能性があり、その出力にギャップが生じることがあります。データ拡張、転移学習、リトリーバル拡張生成モデルなどの技術がこれらのギャップを埋めるのに役立ちます。
LLMOpsの主要コンポーネント
LLMOpsは、データ管理と前処理、リトリーバルシステム、モデルの微調整と適応、展開と監視、プロンプトのバージョン管理と評価の5つの主要コンポーネントを包含し、LLMが直面する課題に対処し、その最適なパフォーマンスを保証します。
これらのコンポーネントを効果的に実装することで、LLMOpsはLLMの開発、展開、メンテナンスを簡素化し、組織がこれらの強力なモデルの潜在能力を最大限に活用できるようにします。
データ管理と前処理
効果的なデータ管理と前処理は、LLMトレーニングにおいて重要であり、データの収集、クリーニング、組織化を含みます。データ品質と整合性を確保することは、LLMのパフォーマンスに直接影響を与えるため、不可欠です。スペルチェック、レーベンシュタイン距離計算、重複排除、外れ値の除去などの技術がデータセットを洗練するために一般的に使用されます。
さらに、データの暗号化やアクセス制御などのデータストレージとセキュリティ対策を実施し、機密情報を保護し、特にドメイン固有のデータを扱う際にはデータ保護規制に準拠する必要があります。
リトリーバルシステム
リトリーバルシステムは、LLMOpsにおいて重要な役割を果たし、リトリーバル拡張生成技術の基盤として機能します。これらのシステムは、膨大なデータプールから関連情報を取得し、LLMの外部知識源として機能します。リトリーバルシステムを統合することで、LLMはトレーニングデータに存在しない追加情報にアクセスし、知識ベースを強化し、出力品質を向上させることができます。
ベクトルデータベースは、複雑な言語特徴を表す高次元データベクトルを効率的に処理することで、LLMOpsのリトリーバルシステムにおいて重要な役割を果たします。これらのデータベースは、スケールでの類似性検索を可能にし、精度と速度のバランスを取り、LLMに必要な情報への迅速なアクセスを提供し、応答時間を犠牲にすることなくコンテンツ品質を向上させます。
モデルの微調整と適応
事前にトレーニングされたLLMを特定のタスクに適応させるための微調整とプロンプトエンジニアリングは、望ましい出力を得るために不可欠であり、タスクパフォーマンスを向上させます。微調整には、適切なモデルアーキテクチャの選択、モデルトレーニングの最適化、モデルパフォーマンスの評価が含まれます。
一方、プロンプトエンジニアリングは、タスクに特化したプロンプトの設計に焦点を当てています。これらのアプローチを組み合わせることで、LLMはさまざまなタスクに対して正確で関連性のある出力を生成するように調整できます。
展開と監視
生産環境でのLLMの展開と監視は、パフォーマンスの維持、問題の解決、コンプライアンスの保証に不可欠です。継続的インテグレーションと展開(CI/CD)パイプラインは、テストとモデル展開プロセスを自動化することで、モデル開発プロセスを促進します。
適切なメトリクス(精度、F1スコア、BLEUなど)を使用した定期的なモデル評価とベンチマークは、モデルパフォーマンスを評価し、パフォーマンスの問題を検出して修正するために重要です。モデル監視の実装は、このプロセスをさらに強化できます。
さらに、データプライバシーを維持し、GDPRやCCPAなどのデータ保護規制に準拠することは、責任あるLLMの展開と監視の重要な側面です。
プロンプトのバージョン管理と評価
プロンプトのバージョン管理は、LLMのための異なるバージョンのプロンプトを作成し、管理することを含みます。このプロセスにより、データサイエンティストは異なるプロンプトを試し、その効果をテストし、タスクに最適なものを選択することができます。
プロンプトのバージョン管理は、フィードバックと結果に基づいてプロンプトを継続的に改善し、適応させることができるため、LLMのパフォーマンスを向上させる可能性があります。また、使用されたプロンプトの履歴を提供し、将来の参照やモデルパフォーマンスの進化を理解するのに役立ちます。
プロンプトの効果を評価することは、それを作成することと同様に重要です。プロンプト評価は、LLMが望ましい出力を生成するために異なるプロンプトのパフォーマンスを評価することを含みます。
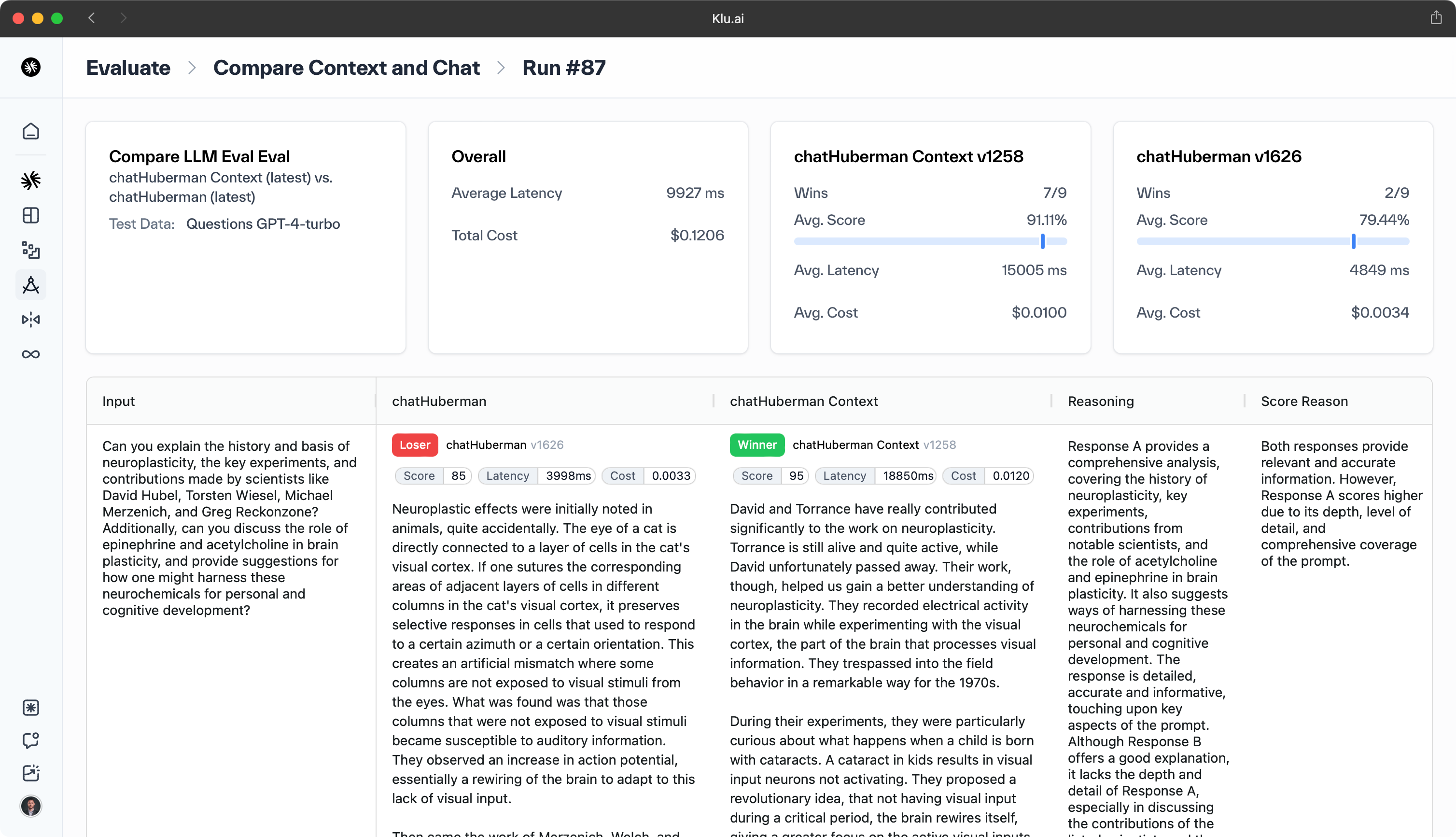
これは、異なるプロンプトによって生成された出力を比較したり、精度、F1スコア、BLEUなどのメトリクスを使用したり、ユーザーフィードバックを通じて行うことができます。定期的なプロンプト評価は、選択されたプロンプトが引き続き最良の結果をもたらすことを保証し、プロンプトの洗練と改善を時間とともに可能にします。
LLMOpsのベストプラクティス
LLMOpsのベストプラクティスを実施することで、LLMのパフォーマンスを大幅に向上させ、その展開に関連するリスクを軽減できます。これらのプラクティスには以下が含まれます:
-
モデル評価とベンチマーク
-
プライバシーとコンプライアンス
組織は、これらのベストプラクティスを遵守することで、これらの高度なAIモデルの潜在能力を最大限に引き出し、その力だけでなく、安全性と責任も確保できます。
プロンプトエンジニアリング
効果的なプロンプトを作成することは、LLMが望ましい出力を生成し、タスクパフォーマンスを向上させるために不可欠です。よく構築されたプロンプトは、モデルに望ましい出力を生成させることができ、不適切なプロンプトは無関係または意味のない結果をもたらす可能性があります。
効果的なプロンプトを作成するためには、簡潔な言葉を使用し、曖昧さを排除し、モデルがタスクを理解するために十分なコンテキストを提供することが推奨されます。
リトリーバル拡張生成
LLMを外部の知識源と組み合わせることで、その能力を強化し、欠けている知識の問題に対処できます。リトリーバル拡張生成は、リトリーバルモデルと生成モデルを組み合わせて、より正確で多様な出力を生成する技術です。
このアプローチは、LLMの知識のギャップを埋め、さまざまなタスクに対してより正確で関連性のある出力を生成することを可能にします。
モデル評価とベンチマーク
適切なメトリクスとベンチマークを使用してLLMのパフォーマンスを定期的に評価することは、品質を維持し、問題に対処するために重要です。精度、F1スコア、BLEUなどのメトリクスに対してモデルパフォーマンスを評価することで、パフォーマンス関連の問題を検出し、修正することができます。
llmops
model outputs
model drift
model outputs
model outputs
large language models
model performance
foundation model
large language models llms
large language model operations
model management
data management
model training
model outputs
vector databases
model drift
robust data management practices
ml models
sensitive data
improve model performance
deep learning models
model deployment
machine learning lifecycle
model optimization
model evaluation
model development process
machine learning
model architecture
continuous model monitoring
deliver higher quality models
fine tuning
model monitoring
prompt engineering
model and pipeline development
ethical model development
ai models
retrieval augmented generation
optimizing model training
rest api model endpoints
optimizing model latency
model review
efficient model management
continuous integration
exploratory data analysis
smooth and efficient workflow
machine learning models
reinforcement learning
training data
data storage
model and pipeline lineage
data collection
natural language processing
automate data collection
prompt templates
data labeling
human feedback
only well performing models
multiple llm calls
model development
performance metrics
higher quality models
data teams
model availability
pre trained
machine learning projects
foundation models
models effectively
model inference
computational power requirements
new data
model security
language models
model latency
distributed training
domain specific data
track model
seamless model updates
classical ml models
external system interactions
access controls
machine learning operations
model fine tuning
complex tasks
fine tune models
モデルのパフォーマンスを他のモデルや業界のベンチマークと比較することで、モデルパフォーマンスと最適化を改善するための貴重な洞察を得ることができます。
プライバシーとコンプライアンス
データプライバシーと規制の遵守を確保することは、LLMOpsにおいて重要です。取るべき重要なステップには以下が含まれます:
-
データセットから個人を特定できる情報(PII)を削除するための匿名化技術の実施
-
GDPRやCCPAなどのデータ保護規制の遵守
-
機密データを保護し、責任あるLLMの展開を確保する
定期的な監査と評価は、継続的なコンプライアンスとセキュリティを保証するために重要です。これにより、高いデータ保護基準が維持され、強力なモデル管理が確立されます。
LLMOpsのツールとプラットフォーム
さまざまなオーケストレーションプラットフォーム、フレームワーク、ライブラリ、可観測性ツールがLLMOpsをサポートし、LLMの開発、展開、継続的な管理を効率化します。これらのリソースは、データサイエンティストやエンジニアがLLMの展開の複雑さに効果的に対処し、さまざまなアプリケーションでのピークパフォーマンスを維持することを可能にします。
モデルオーケストレーションプラットフォーム
DatabricksやHugging Faceのようなオーケストレーションプラットフォームは、データ管理、モデルチューニング、展開、監視を含むLLMの管理の全ライフサイクルを効率化します。これらのプラットフォームは、データを効率的に処理し、実験を行い、モデルとパイプラインを開発し、精度と制御を持って展開するための協力的な環境をチームに提供し、LLMを生産ワークフローにシームレスに統合することを保証します。
フレームワークとライブラリ
TensorFlowやPyTorchのようなオープンソースフレームワークは、LLMの開発を効率化し、モデルの構築、微調整、展開のための基本的なツールを提供します。これらのフレームワークは、スケーラブルな生産グレードのパイプラインの作成をサポートし、さまざまなアプリケーションのためのLLMの効率的な管理と展開を可能にします。
可観測性とメンテナンスツール
Kluのような可観測性とメンテナンスツールは、LLMのリアルタイム監視に不可欠であり、その健康とパフォーマンスを保証します。これらのツールは、チームが問題を迅速に特定し、対処することを可能にし、さまざまなアプリケーションでのLLMの品質とパフォーマンスを維持するために重要です。
LLMOpsの実践
LLMとLLMOpsは、さまざまな業界やユースケースで適用されており、これらの強力なAIモデルの多様性と可能性を示しています。医療からAIアシスタント、チャットボットからプログラミング、教育からデータとの対話アプリケーション、販売からSEOまで、LLMはAI技術との相互作用と活用方法を再定義しています。
以下のサブセクションでは、LLMとLLMOpsの実際のアプリケーションをいくつか紹介し、さまざまな分野での変革的な影響を示します。
AIアシスタント
LLMOpsは、AIアシスタントとチャットボットを大幅に強化し、より自然で会話的なインタラクションを可能にし、シームレスなユーザーエクスペリエンスを提供します。また、チャットボットが正確でパーソナライズされたサポートを提供し、さまざまなセクターでの顧客満足度を向上させることを保証します。
チャットボット
LLMOpsは、チャットボットの開発と管理を革命的に変え、そのパフォーマンスと有用性を向上させました。モデルのトレーニング、パッケージング、検証、展開プロセスを効率化することで、チャットボットはより正確でパーソナライズされたインタラクションでユーザーと関わることができるようになりました。この進歩により、企業は顧客サービスを向上させ、運用を最適化し、成長を促進し、顧客体験を向上させることができます。
データQ&A
LLMとLLMOpsによって強化されたデータとの対話アプリケーションは、業界がビッグデータと対話する方法を変革しています。データとの自然言語会話を可能にすることで、これらのアプリケーションはパターン、トレンド、洞察の迅速な特定を促進します。その結果、生産性、効率、顧客満足度を向上させる意思決定プロセスが簡素化されます。
LLMOpsプラットフォーム
LLMOpsは、大規模言語モデルのライフサイクルを管理するためにさまざまなツールを利用します。以下は、LLMOpsツールの例です:
-
Klu.ai — 野心的なスタートアップや企業向けの完全なアプリライフサイクルLLMOpsで、プロンプトとモデルの改善のための継続的なフィードバック収集とLLMを活用したデータラベリングに焦点を当てています。
-
Weights & Biases (W&B) — このプラットフォームは、MLOpsプラットフォーム内でLLMOpsツールのスイートを提供します。LLMの実行フローの視覚化と検査、入力と出力の追跡、中間結果の表示、プロンプトとLLMチェーン構成の安全な管理のための機能を含みます。
-
Amazon SageMaker — データサイエンティストと開発者が機械学習(ML)モデルを迅速に構築、トレーニング、展開できるようにする完全管理型サービスで、LLMOpsの文脈で使用できます。
LLMを使用したプログラミングタスクの自動化は、ソフトウェア開発プロセスを革命的に変える可能性があります。LLMOpsの助けを借りて、LLMはコードスニペットを生成し、バグ修正を自動化し、ユーザー入力に基づいてアプリケーション全体を作成することさえできます。
これにより、開発プロセスが効率化されるだけでなく、開発者がより複雑で高価値のタスクに集中できるようになり、最終的にソフトウェア開発の品質と効率が向上します。
結論
LLMとLLMOpsの統合は、さまざまなセクターを再形成し、AIが日常の活動において果たす役割を強化しています。
LLMOpsは、LLMの複雑さに対処し、さまざまなアプリケーションのパフォーマンスを最適化します。このシナジーは、組織の成長、運用効率、成果の向上を促進します。
LLMとLLMOpsが進化するにつれて、AIが私たちの生活にさらに組み込まれ、イノベーションを推進し、私たちの相互作用、仕事、問題解決の方法を改善することを約束します。将来の影響についてのより深い理解を得るには、LLMOpsの将来の洞察をご覧ください。