Ajustement fin supervisé (SFT)
by Stephen M. Walker II, Co-Fondateur / PDG
Qu'est-ce que l'ajustement fin supervisé ?
L'ajustement fin supervisé (SFT) est une technique utilisée pour adapter un Modèle de Langage de Grande Taille (LLM) pré-entraîné (de base) à une tâche spécifique en aval en utilisant des données étiquetées. La majorité des LLM utilisés en 2024 sont affinés pour des interactions basées sur le chat ou les instructions.
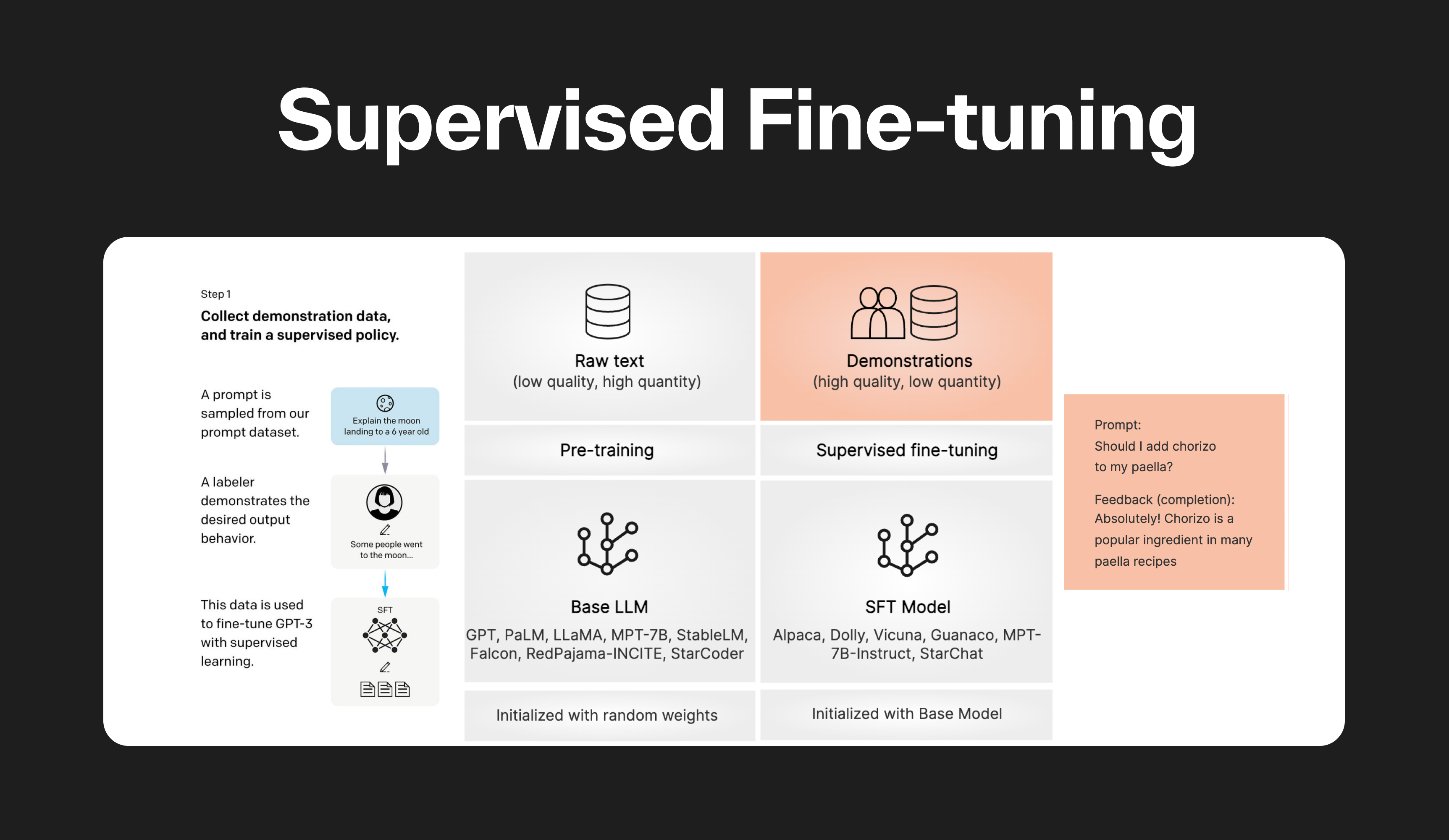
Dans le SFT, le LLM pré-entraîné est affiné sur un ensemble de données étiquetées en utilisant des techniques d'apprentissage supervisé. Les poids du modèle sont ajustés en fonction des gradients dérivés de la perte spécifique à la tâche, qui mesure la différence entre les prédictions du LLM et les étiquettes de vérité terrain.
Ce processus permet au modèle d'apprendre des motifs et des nuances spécifiques à la tâche en adaptant ses paramètres selon la distribution des données spécifiques et les exigences de la tâche.
Le SFT est généralement effectué après le pré-entraînement du modèle et est utilisé pour enseigner au modèle comment suivre des instructions spécifiées par l'utilisateur. Il est plus coûteux en calcul que l'ajustement fin non supervisé mais est également plus susceptible d'atteindre de meilleures performances.
La quantité d'ajustement fin requise dépend de la complexité de la tâche et de la taille de l'ensemble de données. Pour un simple transfert de style utilisant des modèles OpenAI tels que GPT-3.5 ou GPT-4, généralement 30 à 50 exemples de haute qualité peuvent donner d'excellents résultats.
Pour transformer un Modèle de Langage de Grande Taille (LLM) de base en un LLM suivant des instructions (par exemple, de Mistral à Mistral Instruct), il faut généralement un entraînement avec des dizaines de milliers d'exemples.
L'entraînement de l'ajustement fin de Zephyr 7b a été réalisé sur 16 GPU Nvidia A100 pendant environ 4 heures, ce qui sert de point de départ pour les modèles avec 7 milliards de paramètres.
Comment fonctionne l'ajustement fin supervisé ?
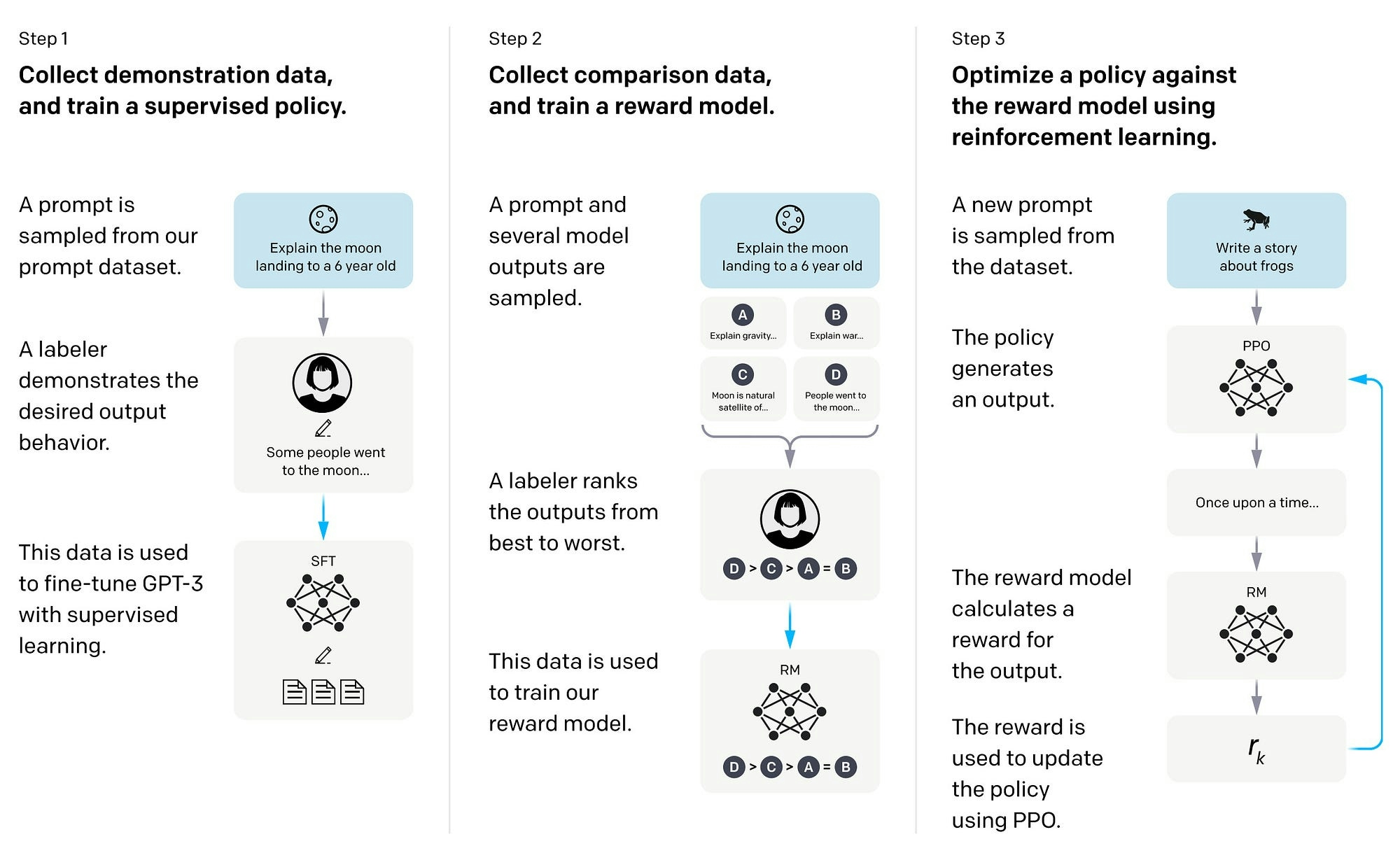
L'ajustement fin supervisé est un processus en trois étapes utilisé en IA et dans les Modèles de Langage de Grande Taille (LLM) pour optimiser les modèles pour des tâches spécifiques.
-
Étape 1 : Pré-entraînement — Le modèle de base ou fondation est initialement entraîné sur un grand ensemble de données, apprenant à comprendre les motifs de langage, la grammaire et le contexte en prédisant le mot suivant dans une phrase donnée. Cette étape aide le modèle à développer une compréhension large du langage.
-
Étape 2 : Étiquetage des données — L'ensemble de données utilisé pour l'ajustement fin est préparé. Chaque point de données est étiqueté avec la sortie ou la réponse correcte. Ces données étiquetées sont cruciales pour l'apprentissage supervisé, car elles guident le modèle dans l'ajustement de ses paramètres pendant le processus d'ajustement fin.
-
Étape 3 : Ajustement fin — Le modèle pré-entraîné est ensuite affiné sur un ensemble de données spécifique à la tâche avec des données étiquetées. Le modèle ajuste ses paramètres pour améliorer sa performance sur cette tâche spécifique. Ces tâches peuvent aller de la classification de texte, l'analyse de sentiment, aux systèmes de questions-réponses.
Le terme "supervisé" est utilisé car ce processus exploite des données étiquetées, où les sorties correctes sont déjà connues, pour guider le processus d'apprentissage. Cette méthode améliore la précision du modèle en appliquant la compréhension large du langage acquise lors du pré-entraînement à une tâche spécifique et ciblée pendant l'ajustement fin.
Quels sont les avantages de l'ajustement fin supervisé ?
L'ajustement fin supervisé (SFT) est une technique puissante utilisée pour adapter les Modèles de Langage de Grande Taille (LLM) pré-entraînés à des tâches spécifiques en aval en utilisant des données étiquetées. Les avantages de l'ajustement fin supervisé incluent :
-
Motifs et nuances spécifiques à la tâche — Le SFT permet au modèle d'apprendre des motifs et des nuances spécifiques à la tâche en adaptant ses paramètres selon la distribution des données spécifiques et les exigences de la tâche.
-
Amélioration des performances — L'ajustement fin d'un modèle pré-entraîné lui permet de tirer parti des connaissances et des représentations apprises à partir de vastes quantités de données, conduisant à une amélioration des performances sur des tâches spécifiques.
-
Efficacité des données — Le SFT peut être appliqué à un large éventail de scénarios réels, même lorsque le nombre d'exemples étiquetés est limité, le rendant plus efficace en termes de données.
-
Efficacité des ressources — L'ajustement fin des modèles pré-entraînés permet de gagner un temps considérable et des ressources computationnelles qui seraient autrement nécessaires pour entraîner un modèle à partir de zéro.
-
Personnalisation — Le SFT permet l'adaptation du comportement d'un LLM, de son style d'écriture ou de ses connaissances spécifiques à un domaine à des nuances, des tons ou des terminologies spécifiques, offrant un alignement profond avec des styles ou des domaines d'expertise particuliers.
-
Réduction du surapprentissage — Des techniques comme l'arrêt précoce, le dropout et l'augmentation des données peuvent être employées pendant l'ajustement fin pour atténuer le risque de surapprentissage sur de petits ensembles de données et promouvoir la généralisation à de nouvelles données.
Quelles sont les techniques courantes d'ajustement fin supervisé ?
Les méthodes courantes d'ajustement fin supervisé pour les Modèles de Langage de Grande Taille (LLM) incluent LoRA (Low-Rank Adaptation) et sa variante économe en mémoire, QLoRA (Quantized LoRA). Ces techniques font partie de la famille de l'Ajustement Fin Efficace en Paramètres (PEFT), qui vise à rendre l'ajustement fin plus efficace et accessible.
L'approche de LoRA pour l'ajustement fin utilise la décomposition de faible rang pour représenter les mises à jour de poids avec deux matrices plus petites, réduisant le nombre de paramètres entraînables et rendant l'ajustement fin plus efficace. Cette méthode a montré qu'elle surpasse l'ajustement fin complet dans certains cas tout en évitant l'oubli catastrophique, un phénomène qui se produit lorsque les connaissances acquises lors du pré-entraînement sont perdues pendant l'ajustement fin.
- LoRA (Low-Rank Adaptation) — Une technique d'ajustement fin efficace en paramètres qui utilise la décomposition de faible rang pour représenter les mises à jour de poids avec deux matrices plus petites, réduisant le nombre de paramètres entraînables.
- QLoRA (Quantized LoRA) — Une variante économe en mémoire de LoRA qui réduit encore les exigences de mémoire pour l'ajustement fin des grands LLM.
D'autres techniques d'ajustement fin supervisé pour les Modèles de Langage de Grande Taille (LLM) incluent :
-
Ajustement des hyperparamètres de base — Cela implique d'ajuster manuellement les hyperparamètres du modèle, tels que le taux d'apprentissage, la taille du lot et le nombre d'époques, jusqu'à ce que la performance souhaitée soit atteinte.
-
Apprentissage par transfert — Cette technique implique d'affiner un LLM pré-entraîné sur une tâche spécifique en aval en utilisant des données étiquetées.
-
Apprentissage multi-tâches — Cette approche entraîne le LLM sur plusieurs tâches simultanément, permettant au modèle d'apprendre des motifs et des nuances spécifiques à la tâche.
-
Apprentissage par peu d'exemples — Cette technique implique d'entraîner le LLM sur un petit nombre d'exemples étiquetés pour une tâche spécifique, en tirant parti des connaissances préexistantes du modèle pour faire des prédictions.
-
Ajustement fin spécifique à la tâche — Cette méthode implique d'entraîner l'ensemble du modèle sur des données spécifiques à la tâche, permettant à toutes les couches du modèle d'être ajustées pendant le processus d'entraînement.
-
Modélisation de la récompense — Cette technique implique d'entraîner le LLM sur un ensemble de données étiquetées spécifique à la tâche, où chaque point de données d'entrée est associé à une réponse ou une étiquette correcte. Le modèle apprend à ajuster ses paramètres pour prédire ces étiquettes aussi précisément que possible.
-
Optimisation de la politique proximale — Cette méthode implique d'affiner le LLM sur une tâche spécifique en utilisant l'apprentissage par renforcement à partir de retours humains (RLHF).
-
Classement comparatif — Cette technique implique d'entraîner le LLM à classer différentes sorties en fonction de leur pertinence ou de leur qualité, permettant au modèle d'apprendre à générer des sorties plus pertinentes et de haute qualité.
Ces techniques d'ajustement fin aident à adapter les LLM pré-entraînés à des tâches et des domaines spécifiques, améliorant leur performance et les rendant plus adaptés à diverses applications.
Quels sont les problèmes courants avec l'ajustement fin supervisé ?
Certains problèmes courants avec l'ajustement fin supervisé des Modèles de Langage de Grande Taille (LLM) incluent :
-
Surapprentissage — Le surapprentissage se produit lorsque le modèle devient trop spécifique aux données d'entraînement, conduisant à une généralisation sous-optimale sur des données non vues. C'est un problème courant en apprentissage automatique et peut également survenir pendant le processus d'ajustement fin des LLM.
-
Ajustement des hyperparamètres — La sélection d'hyperparamètres inappropriés peut entraîner une convergence lente, une généralisation médiocre ou même un entraînement instable. Maîtriser l'ajustement des hyperparamètres est un défi critique qui peut être un fardeau en termes de temps et de ressources.
-
Problèmes de qualité des données — L'ajustement fin des LLM n'est aussi bon que la qualité des données fournies. Une connaissance insuffisante du modèle ou de la source de données peut conduire à de mauvais résultats d'ajustement fin.
-
Oubli catastrophique — Ce phénomène se produit lorsque l'ajustement fin d'un modèle pré-entraîné le fait oublier les connaissances précédemment acquises, conduisant à une instabilité dans le processus d'ajustement fin.
-
Performance incohérente — L'ajustement fin des LLM peut parfois entraîner une performance incohérente sur des cas limites ou une incapacité à intégrer suffisamment de prompts à quelques exemples dans la fenêtre de contexte pour orienter le modèle.
Aborder les problèmes courants avec l'ajustement fin supervisé des Modèles de Langage de Grande Taille (LLM) implique plusieurs stratégies. L'ajustement des hyperparamètres peut être automatisé en utilisant des techniques telles que la recherche en grille ou l'optimisation bayésienne, qui explorent efficacement l'espace des hyperparamètres pour identifier des configurations optimales. Le surapprentissage et l'oubli catastrophique peuvent être combattus en incorporant des techniques comme la distillation des connaissances. Assurer la qualité et la pertinence des données pour la tâche ou le cas d'utilisation spécifique est crucial. Enfin, le processus d'ajustement fin doit être surveillé et évalué par une analyse continue des erreurs et une amélioration itérative.
FAQ
Quelle est la différence entre l'ajustement fin supervisé et l'ajustement fin non supervisé ?
L'ajustement fin supervisé affine un modèle pré-entraîné avec des données étiquetées, fournissant des exemples explicites de paires entrée-sortie pour guider le processus d'apprentissage. Cette approche ciblée donne souvent une précision plus élevée mais nécessite plus de ressources computationnelles en raison de la complexité de la minimisation de la fonction de perte impliquée.
En revanche, l'ajustement fin non supervisé n'utilise pas de données étiquetées, s'appuyant plutôt sur la capacité intrinsèque du modèle à discerner des motifs et des structures au sein des données. Cette méthode est moins exigeante en calcul mais peut ne pas atteindre les niveaux de performance des méthodes supervisées en raison de l'absence de retour direct.
La décision d'utiliser l'ajustement fin supervisé ou non supervisé dépend de la tâche à accomplir, de la disponibilité des données étiquetées, du budget computationnel et des exigences de performance. L'ajustement fin supervisé est généralement la méthode privilégiée pour une précision maximale, tandis que l'ajustement fin non supervisé est une option lorsque les ressources sont limitées ou que les données étiquetées ne sont pas accessibles.
Comment l'ajustement fin supervisé diffère-t-il de l'apprentissage par transfert ?
Bien que les deux impliquent l'adaptation d'un modèle pré-entraîné à une nouvelle tâche, l'ajustement fin supervisé nécessite généralement des données étiquetées et se concentre sur l'ajustement des poids du modèle sur ces données. L'apprentissage par transfert peut également impliquer l'utilisation d'un modèle pré-entraîné comme point de départ, puis son entraînement sur un nouvel ensemble de données, qui peut ne pas être nécessairement étiqueté.
L'ajustement fin supervisé peut-il être appliqué à n'importe quel LLM ?
En théorie, oui. Cependant, l'efficacité de l'ajustement fin peut dépendre de facteurs tels que la taille du LLM, la qualité et la quantité des données d'ajustement fin, et la similarité entre les tâches de pré-entraînement et la tâche cible.
Quelles sont les meilleures pratiques pour éviter le surapprentissage lors de l'ajustement fin supervisé ?
Les meilleures pratiques incluent l'utilisation de techniques comme le dropout, l'arrêt précoce et l'augmentation des données, ainsi que la sélection minutieuse des hyperparamètres et l'emploi de méthodes de régularisation. Il est également important d'utiliser un ensemble de validation pour surveiller la performance du modèle et l'empêcher d'apprendre le bruit dans les données d'entraînement.
Comment mesurez-vous le succès de l'ajustement fin supervisé ?
Le succès de l'ajustement fin supervisé est évalué à travers une variété de métriques d'évaluation qui mesurent la performance du modèle sur un ensemble de test qu'il n'a pas rencontré pendant l'entraînement. Bien que la précision, la précision, le rappel et le score F1 soient des métriques standard, le choix de l'évaluation LLM dépend des objectifs d'ajustement fin et de la nature de la tâche.