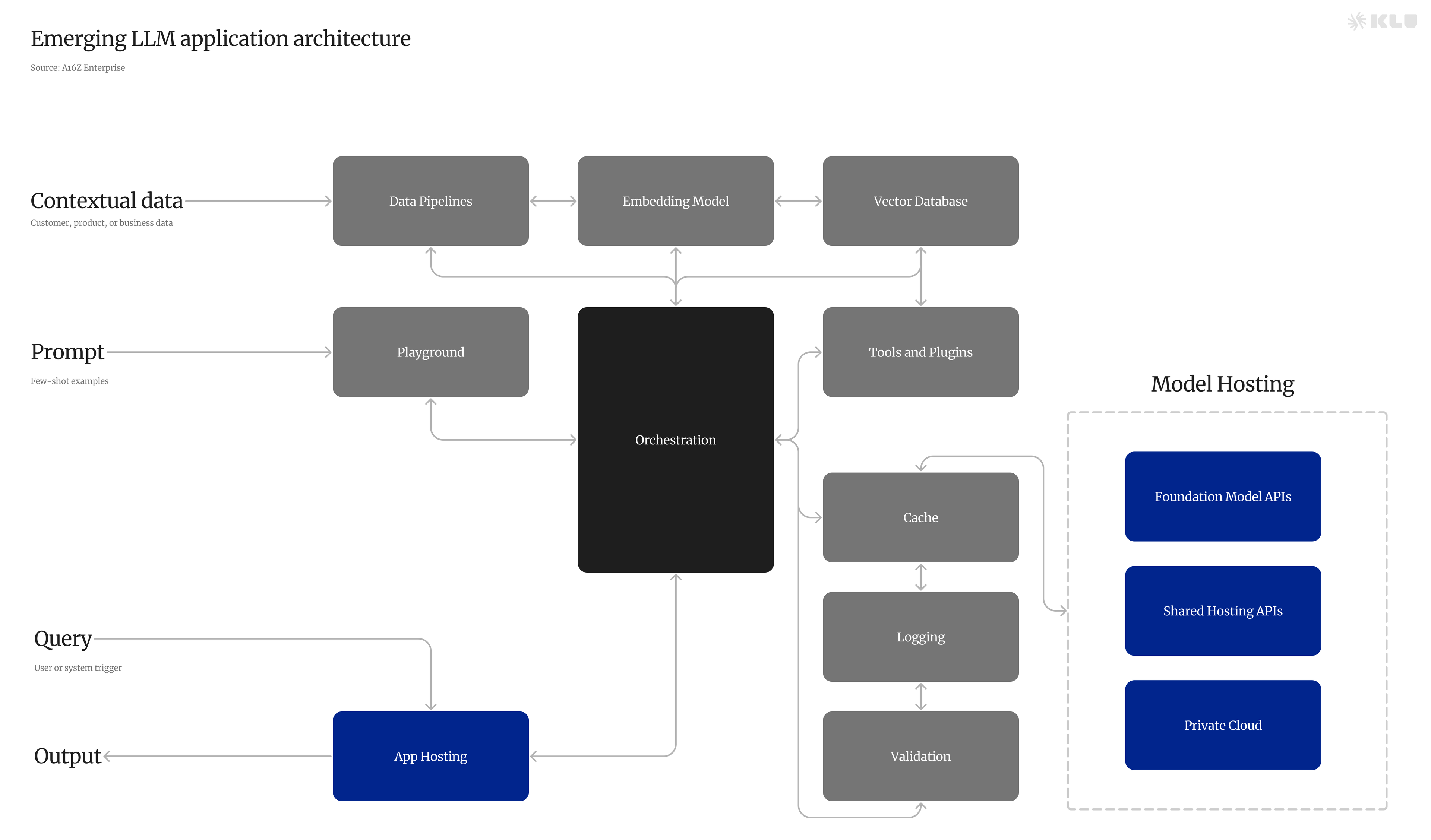
Emerging Architectures for LLM Applications is a comprehensive reference architecture for the emerging LLM app stack created by the venture firm A16Z. It shows the most common systems, tools, and design patterns used by AI startups and sophisticated tech companies. This provides a comprehensive overview of the emerging architectures for LLM applications.
The LLM App Stack
The LLM app stack includes data pipelines, embedding models, vector databases, playgrounds, orchestration, APIs/plugins, and LLM cache. These components work together to facilitate the process of writing, code generation, troubleshooting, and brainstorming in an LLM application.
Emerging architectures for Large Language Models (LLMs) applications are being shaped by several key trends and technologies. These architectures are designed to leverage the power of LLMs in various applications, ranging from chatbots and virtual assistants to data analysis and content generation.
Pivotal Trends
Three pivotal trends are also shaping the trajectory of LLM applications: Federated Learning, Sparse Attention Mechanisms, and New Model Architectures. Federated Learning involves training models across multiple devices or servers, each holding local data, which not only safeguards user privacy but also reduces reliance on centralized data storage. Sparse Attention Mechanisms address the computational intensity of traditional attention mechanisms by selectively focusing on pertinent tokens, significantly enhancing the efficiency of these models. New Model Architectures like LongFormer and CLIP are redefining the capabilities of LLMs. LongFormer extends the capabilities of Transformers, enabling them to process longer sequences of text, while CLIP opens the door to a host of applications that demand a holistic comprehension of both visual and textual mediums.
Moreover, LLMs are influencing data architecture trends. For instance, co-pilots, AI systems that assist in tasks like writing design documents, creating data architecture diagrams, and auditing SQLs against approved patterns, are expected to become more prevalent in data architecture. These co-pilots can help expedite the daily process of a data architect and potentially lead to cost optimization as productivity increases.
The emerging architectures for LLM applications are a combination of innovative design patterns, a diverse stack of tools and technologies, and the influence of key trends in federated learning, sparse attention mechanisms, and new model architectures. These architectures are poised to revolutionize how we interact with technology and unlock new realms of possibilities for LLMs.
Design Pattern: In-context Learning
One of the key architectural patterns for LLM applications is the in-context learning design pattern. This pattern involves using LLMs off the shelf, without any fine-tuning, and controlling their behavior through clever prompting and conditioning on private "contextual" data. This approach effectively reduces an AI problem to a data engineering problem that most startups and big companies already know how to solve.
In-context learning is a design pattern that uses LLMs off the shelf, then controls their behavior through clever prompting and conditioning on private “contextual” data. This pattern effectively reduces an AI problem to a data engineering problem that most startups and big companies already know how to solve.
Data Preprocessing / Embedding
Data preprocessing / embedding involves storing private data to be retrieved later. Typically, the documents are broken into chunks, passed through an embedding model, then stored in a specialized database called a vector database.
Prompt Construction / Retrieval
When a user submits a query, the application constructs a series of prompts to submit to the language model. A compiled prompt typically combines a prompt template hard-coded by the developer; examples of valid outputs called few-shot examples; any necessary information retrieved from external APIs; and a set of relevant documents retrieved from the vector database.
Prompt Execution / Inference
Once the prompts have been compiled, they are submitted to a pre-trained LLM for inference—including both proprietary model APIs and open-source or self-trained models. Some developers also add operational systems like logging, caching, and validation at this stage.
How do Agents fit into the LLM App Architecture?
AI agent frameworks are an important component missing from this reference architecture. Agents give AI apps a fundamentally new set of capabilities: to solve complex problems, to act on the outside world, and to learn from experience post-deployment. They do this through a combination of advanced reasoning/planning, tool usage, and memory / recursion / self-reflection.
How will this architecture change in the future?
The LLM app stack is still very early and may change substantially as the underlying technology advances. However, it serves as a useful reference for developers working with LLMs now. As the field continues to evolve, developers can expect to see new tools and techniques emerge to make the process of building LLM applications even more efficient and effective.
Emerging Technologies
In terms of specific technologies and tools, the LLM app stack includes data pipelines, embedding models, vector databases, orchestration tools, APIs/plugins, and LLM caches. Some of the tools and technologies used in this stack include Klu.ai, Databricks, OpenAI, Pinecone, Langchain, Serp, Redis, Airflow, Cohere, Qdrant, LlamaIndex, Wolfram, SQLite, Unstructured, Hugging Face, ChromaDB, ChatGPT, GPTCache, pgvector, Logging / LLMOps, Weights & Biases, Guardrails, Vercel, AWS, MLflow, Rebuff, Anthropic, Replicate, GCP, Anyscale, Microsoft Guidance, Azure, Mosaic, LMQL, Modal, CoreWeave, Modal, RunPod.