Was ist Reinforcement Learning from Human Feedback (RLHF)?
Reinforcement Learning from Human Feedback (RLHF) ist eine maschinelle Lernmethode, die Reinforcement Learning mit menschlichem Feedback kombiniert, um KI-Agenten zu trainieren, insbesondere bei Aufgaben, bei denen die Definition einer Belohnungsfunktion herausfordernd ist, wie z.B. menschliche Präferenzen in der natürlichen Sprachverarbeitung.
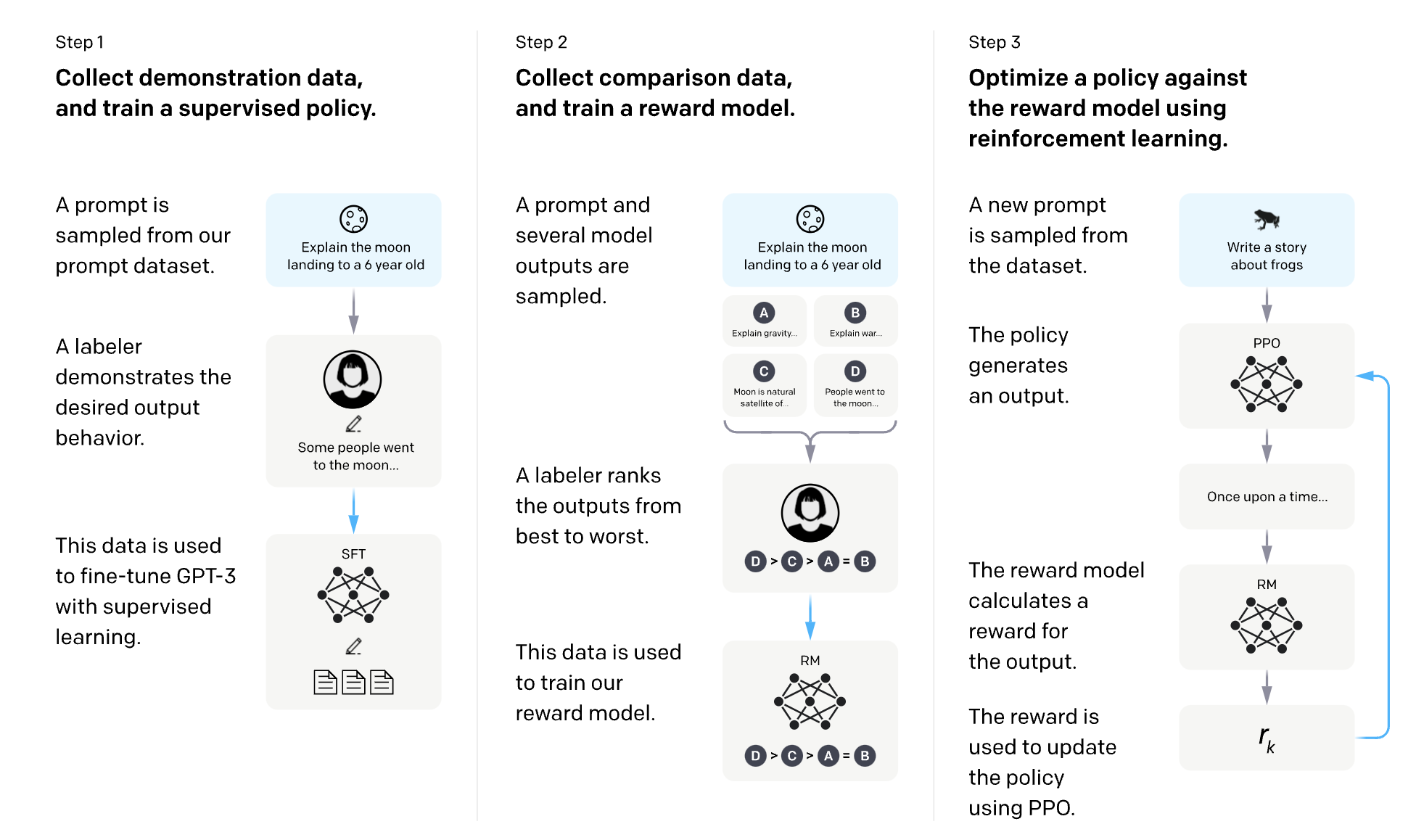
Bei RLHF wird ein "Belohnungsmodell" direkt aus menschlichem Feedback trainiert, das dann als Belohnungsfunktion verwendet wird, um die Politik des Agenten mit Hilfe von Reinforcement Learning-Algorithmen wie Proximal Policy Optimization zu optimieren.
Der Prozess umfasst typischerweise drei Kernschritte:
- Vortraining eines Sprachmodells (LM) oder KI-Agenten.
- Sammeln von Daten und Training eines Belohnungsmodells basierend auf menschlichem Feedback, oft indem Menschen gebeten werden, Instanzen des Verhaltens des Agenten zu bewerten.
- Feinabstimmung des LM oder KI-Agenten mit Reinforcement Learning, wobei das Belohnungsmodell zur Steuerung der Optimierung verwendet wird.
RLHF wurde in verschiedenen Bereichen angewendet, einschließlich Konversationsagenten, Textzusammenfassung und natürlichem Sprachverständnis. Es hilft, die Robustheit und Exploration von Reinforcement-Learning-Agenten zu verbessern, insbesondere wenn die Belohnungsfunktion spärlich oder verrauscht ist.
Was ist Reinforcement Learning from AI Feedback (RLAIF)?
RLAIF, oder Reinforcement Learning mit KI-Feedback, ist ein fortgeschrittener maschineller Lernansatz, bei dem ein künstliches Intelligenzsystem lernt, Entscheidungen basierend auf Feedback aus seiner Umgebung zu treffen. Es ist ein Teilgebiet der KI, das sich auf Strategien zur Aktionsauswahl konzentriert. Bei dieser Methode wird ein KI-System trainiert, bestimmte Aktionen auszuführen, mit dem Ziel, eine Art von Belohnung zu maximieren.
Im Laufe der Zeit verbessert die KI durch einen Prozess von Versuch und Irrtum ihr Verhalten basierend auf dem positiven oder negativen Feedback, das sie aus ihren Aktionen erhält, und erhöht so die kumulative Belohnung. Das Ziel von RLAIF ist es, Algorithmen und Techniken zu entwickeln, die es Computersystemen und Robotern ermöglichen, optimale Verhaltensweisen zu erlernen, indem sie mit ihrer Umgebung interagieren und aus ihren Fehlern lernen.
Was sind die Schlüsselkomponenten von RLHF?
Reinforcement Learning from Human Feedback (RLHF) ist eine Art von maschinellem Lernen, das Reinforcement Learning (RL) und überwachtes Lernen aus menschlichem Feedback kombiniert. Bei RLHF lernt ein KI-System sowohl aus seinen eigenen Erfahrungen in einer Umgebung (wie im traditionellen RL) als auch aus Feedback, das von Menschen oder anderen KI-Systemen bereitgestellt wird. Dieses Feedback kann dem KI-System helfen, schneller zu lernen und schädliche oder unerwünschte Aktionen zu vermeiden.
Es gibt drei Schlüsselkomponenten für RLHF in der KI:
-
Ein Reinforcement Learning-Algorithmus: Dieser wird verwendet, um dem KI-System zu ermöglichen, aus seinen eigenen Erfahrungen in einer Umgebung zu lernen.
-
Menschliches Feedback: Dieses wird verwendet, um dem KI-System zusätzliche Anleitung zu geben, damit es schneller lernt und schädliche oder unerwünschte Aktionen vermeidet.
-
Eine Methode zur Kombination des RL-Algorithmus und des menschlichen Feedbacks: Diese wird verwendet, um das Lernen aus dem RL-Algorithmus und dem menschlichen Feedback in einen einzigen, kohärenten Lernprozess zu integrieren.
Was sind einige der Herausforderungen bei RLHF?
RLHF steht vor mehreren Herausforderungen und Einschränkungen, die in drei Hauptbereiche eingeteilt werden können:
Qualitativ hochwertiges menschliches Feedback sammeln
- Die Modellierung menschlicher Präferenzen ist schwierig aufgrund ihrer Flüchtigkeit, Kontextabhängigkeit und Komplexität.
- Die Auswahl einer repräsentativen Stichprobe von Annotatoren, die konsistentes und genaues Feedback liefern können, ist herausfordernd.
Genauigkeit beim Erlernen eines Belohnungsmodells aus menschlichem Feedback
- Die Bewertung von Belohnungsmodellen ist schwierig und kostspielig, insbesondere wenn die wahre Belohnungsfunktion unbekannt ist.
- Belohnungshacking kann auftreten, was zu unbeabsichtigten Konsequenzen und unerwünschtem Verhalten führt.
Optimierung der KI-Politik mit dem unvollkommenen Belohnungsmodell
- Von RLHF trainierte Modelle können unter Problemen wie Halluzinationen, Voreingenommenheit und Anfälligkeit für adversative Angriffe leiden.
- Feinabstimmung reduziert die Vielfalt der von einem Modell produzierten Proben, was zu einem "Mode-Kollaps" führt.
Um diese Herausforderungen anzugehen, betonen Forscher die Wichtigkeit, die Grenzen von RLHF zu erkennen und es in einen breiteren technischen Rahmen zu integrieren, der Methoden für eine sichere und skalierbare menschliche Aufsicht, den Umgang mit Unsicherheiten in gelernten Belohnungen, adversatives Training sowie Transparenz- und Prüfverfahren umfasst.
Was sind einige der jüngsten Fortschritte in RLHF?
Es gibt viele jüngste Fortschritte in RLHF, aber hier sind drei der bedeutendsten:
-
Verbesserte Methoden zur Integration von RL und menschlichem Feedback: Diese Methoden zielen darauf ab, die Stärken von RL und menschlichem Feedback zu nutzen und gleichzeitig ihre Schwächen zu minimieren.
-
Techniken zur Verringerung von Verzerrungen im menschlichen Feedback: Diese Techniken zielen darauf ab, sicherzustellen, dass das KI-System effektiv aus menschlichem Feedback lernen kann, ohne ungebührlich von menschlichen Verzerrungen beeinflusst zu werden.
-
Entwicklung effizienterer RL-Algorithmen: Diese Algorithmen zielen darauf ab, dem KI-System zu ermöglichen, schneller und effektiver aus seinen eigenen Erfahrungen in einer Umgebung zu lernen.
Was sind einige potenzielle Anwendungen von RLHF?
RLHF, eine Art von maschinellem Lernen, zeichnet sich in Szenarien aus, in denen KI-Systeme optimal mit einer Umgebung unter menschlicher Anleitung interagieren. Dies macht es ideal für verschiedene KI-Anwendungen, einschließlich Robotik, Gaming und Steuerungssystemen.
In der Robotik kann RLHF einem Roboter beibringen, Aufgaben wie das Umsetzen von Objekten durchzuführen. Der Roboter lernt aus seinen Erfahrungen und menschlichem Feedback, beschleunigt seinen Lernprozess und verhindert schädliche oder unerwünschte Aktionen.
Im Gaming kann RLHF hochrangige Spielagenten entwickeln. Diese Agenten, die aus ihren Erfahrungen und menschlichem Feedback lernen, können ihre Leistung schnell verbessern und gleichzeitig schädliche oder unerwünschte Aktionen vermeiden.
Schließlich findet RLHF Anwendung in Steuerungssystemen, wie z.B. bei der Entwicklung von Controllern für autonome Autos oder Industrieroboter. Ziel ist es, eine Politik zu erlernen, die es dem Agenten ermöglicht, sicher und effizient mit seiner Umgebung zu interagieren, mit dem zusätzlichen Vorteil der menschlichen Anleitung.