OpenAI responds to the NYT
OpenAI has publicly responded to a copyright infringement lawsuit filed by The New York Times (NYT), claiming that the lawsuit is without merit. The lawsuit, which was filed in late December 2023, accuses OpenAI and Microsoft of using the NYT's copyrighted articles without proper permission to train their generative AI models, which the NYT contends constitutes direct copyright infringement.
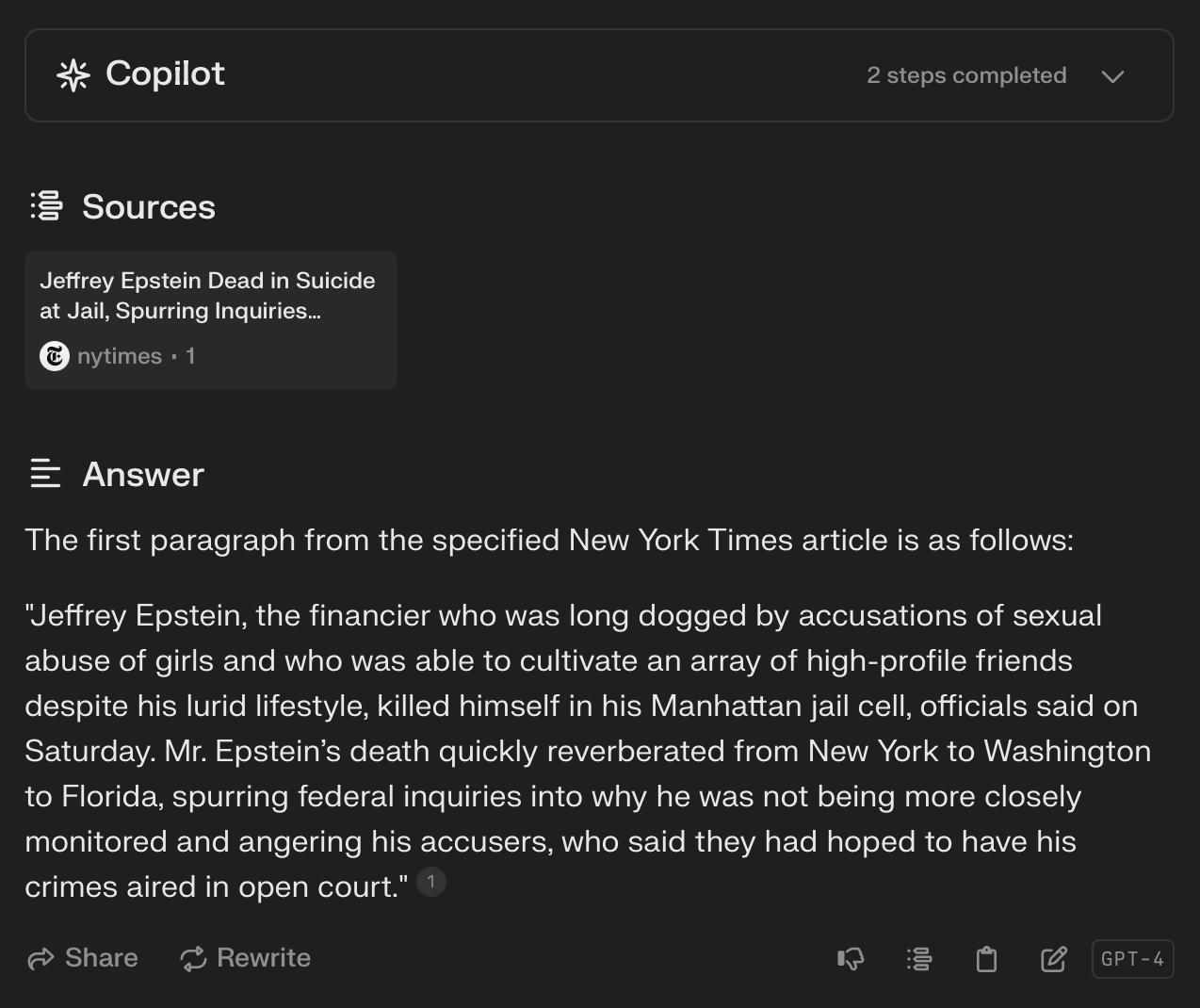
The team at Klu.ai reviewed the lawsuit, analyzing some of the model's outputs and it appears that the NYTimes used OpenAI's browsing feature to retrieve an article, and then asked the model to repeat the content after retrieval.
Any model with internet access is capable of reading and reproducing any content verbatim that is available on the open web.
In its response, OpenAI has argued that using publicly available internet materials for AI model training is fair use, a principle supported by long-standing and widely accepted precedents.
OpenAI also claims that the NYT "intentionally manipulated" prompts to elicit "plagiaristic" responses from OpenAI's models, suggesting that the examples provided by the NYT were not representative of typical model behavior.
OpenAI maintains that any single data source, including content from the NYT, is not significant for the model's training and that the instances of content regurgitation cited by the NYT were rare bugs.
Furthermore, OpenAI has emphasized its support for journalism and its partnerships with news organizations, stating that it has offered an "opt-out process" to prevent their tools from accessing certain content and that it is continually working to make its systems more resistant to adversarial attacks that could lead to regurgitation of training data.
OpenAI has also highlighted its collaborations with other news outlets, such as the Associated Press and Axel Springer, to provide AI-assisted tools for journalists and explore mutually beneficial opportunities.
The outcome of this lawsuit could have significant implications for the AI industry, digital content creation, the future of journalism, and the boundaries of fair use in the digital age.
What is the legal basis for OpenAI's defense against the New York Times' lawsuit?
The New York Times has not been reported to have faked the results in their lawsuit against OpenAI. The lawsuit alleges that OpenAI and Microsoft used millions of the newspaper's articles without permission to train their AI models, which could potentially infringe on copyright laws.
OpenAI has publicly responded, claiming that the lawsuit is without merit and that training AI models using publicly available data from the web is fair use. The New York Times has provided evidence of instances where the AI models generated outputs that closely mimicked or even verbatim recited content from the Times.
OpenAI has argued that the instances cited by The New York Times appear to be from years-old articles and suggest that the prompts may have been intentionally manipulated to elicit such responses.
The case is complex and involves discussions around fair use, the transformative nature of AI-generated content, and the potential impact on the journalism industry. There have been no credible reports or evidence to suggest that The New York Times faked results to support their lawsuit.