Attention de requête groupée
by Stephen M. Walker II, Co-Fondateur / PDG
L'Attention de requête groupée (GQA) est une interpolation de l'attention multi-requête et multi-tête qui atteint une qualité proche de l'attention multi-tête tout en maintenant une vitesse comparable à l'attention multi-requête.
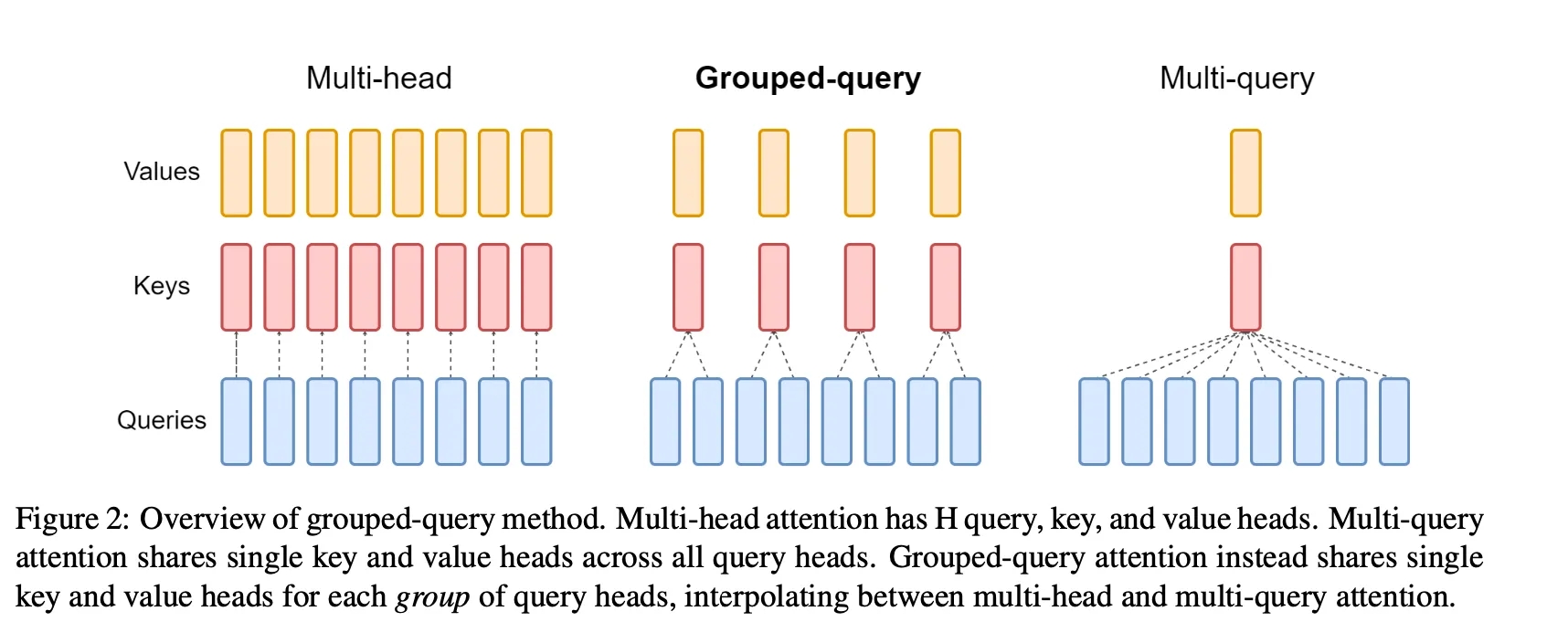
Dans le contexte des modèles de transformateur, l'attention multi-tête consiste en plusieurs couches d'attention (têtes) en parallèle avec différentes transformations linéaires sur les requêtes, les clés, les valeurs et les sorties. D'autre part, l'attention multi-requête est identique sauf que les différentes têtes partagent un seul ensemble de clés et de valeurs.
Qu'est-ce que l'Attention de requête groupée?
L'Attention de requête groupée (GQA) est une méthode qui interpole entre l'attention multi-requête (MQA) et l'attention multi-tête (MHA). Elle vise à atteindre la qualité de l'attention multi-tête tout en maintenant la vitesse de l'attention multi-requête.
La GQA peut être considérée comme un moyen d'optimiser le mécanisme d'attention dans les modèles basés sur des transformateurs. Au lieu de calculer l'attention pour chaque requête indépendamment, la GQA regroupe les requêtes ensemble et calcule leur attention conjointement. Cela réduit le nombre de calculs d'attention, ce qui conduit à des temps d'inférence plus rapides.
Cependant, alors que la MQA accélère considérablement l'inférence du décodeur, elle peut entraîner une dégradation de la qualité. Pour y remédier, la GQA a été introduite comme une généralisation de la MQA, en utilisant un nombre intermédiaire de têtes de clés-valeurs, qui est plus d'une mais moins que le nombre de têtes de requêtes.
Dans la GQA, les têtes de requêtes sont divisées en groupes, chacun partageant une seule tête de clé et de valeur. Cette approche permet à la GQA d'interpoler entre l'attention multi-tête et multi-requête, atteignant un équilibre entre la qualité et la vitesse. Par exemple, la GQA avec un seul groupe (et donc une seule tête de clé et de valeur) est équivalente à la MQA, tandis que la GQA avec des groupes égaux au nombre de têtes est équivalente à la MHA.
La méthode GQA a été appliquée pour accélérer l'inférence sur les grands modèles de langage sans sacrifier significativement la qualité. C'est une technique prometteuse pour améliorer l'efficacité des modèles de transformateurs, en particulier dans le contexte de l'IA générative.
Quelles sont quelques méthodes courantes pour mettre en œuvre l'Attention de requête groupée?
Les méthodes courantes pour mettre en œuvre l'Attention de requête groupée (GQA) comprennent :
-
Regroupement des requêtes en fonction de la similarité : Une méthode populaire pour mettre en œuvre la GQA consiste à regrouper les requêtes en fonction de leur similarité. Cela implique de calculer une métrique de similarité entre les requêtes puis de les assigner à des groupes en conséquence.
-
Division des têtes de requêtes en groupes : Dans la GQA, les têtes de requêtes sont divisées en groupes, chacun partageant une seule tête de clé et de valeur. Cette approche permet à la GQA d'interpoler entre l'attention multi-tête et multi-requête, atteignant un équilibre entre la qualité et la vitesse.
-
Utilisation d'un nombre intermédiaire de têtes de clés-valeurs : La GQA trouve un équilibre entre l'attention multi-requête (MQA) et l'attention multi-tête (MHA) en utilisant un nombre intermédiaire de têtes de clés-valeurs, qui est plus d'un mais moins que le nombre de têtes de requêtes.
-
Répétition des paires clés-valeurs pour l'efficacité computationnelle : Dans la GQA, les paires clés-valeurs sont répétées pour optimiser les performances tout en maintenant la qualité. Cela est réalisé en répétant les paires clés-valeurs n_rep fois, où n_rep correspond au nombre de têtes de requêtes qui partagent la même paire clé-valeur.
Ces méthodes peuvent être combinées et adaptées pour répondre aux exigences spécifiques d'une tâche ou d'une architecture de modèle donnée.
Quels sont les avantages de l'Attention de requête groupée?
Les avantages de l'Attention de requête groupée (GQA) comprennent :
-
Qualité : La GQA atteint une qualité proche de l'attention multi-tête (MHA) en interpolant entre l'attention multi-requête (MQA) et la MHA, trouvant un équilibre entre les deux.
-
Vitesse : La GQA maintient une vitesse comparable à la MQA, qui est plus rapide que la MHA, en utilisant un nombre intermédiaire de têtes de clés-valeurs.
-
Réduction de la complexité computationnelle : La GQA peut réduire significativement la complexité computationnelle des grands modèles de langage, conduisant à des temps d'inférence plus rapides.
-
Parallélisme multi-GPU : La GQA permet le parallélisme multi-GPU, permettant une utilisation plus efficace des ressources computationnelles.
-
Faible utilisation de la mémoire : La GQA combine la faible utilisation de la mémoire de la MQA avec la qualité de la MHA, la rendant adaptée aux modèles à grande échelle avec des contraintes de mémoire.
Quels sont les défis associés à l'Attention de requête groupée?
L'Attention de requête groupée (GQA) est une technique utilisée dans les grands modèles de langage pour accélérer le temps d'inférence en regroupant les requêtes ensemble et en calculant leur attention collectivement. C'est une interpolation de l'attention multi-requête et multi-tête qui atteint une qualité proche de l'attention multi-tête à une vitesse comparable à l'attention multi-requête. Cependant, il y a plusieurs défis associés à la GQA :
-
Dégradation de la qualité et instabilité de l'entraînement : La GQA est une évolution de l'Attention Multi-Requête (MQA), qui utilise plusieurs têtes de requêtes mais une seule tête de clé et de valeur. Alors que la MQA accélère l'inférence du décodeur, elle peut entraîner une dégradation de la qualité et une instabilité de l'entraînement. La GQA tente de pallier cela en utilisant un nombre intermédiaire de têtes de clés-valeurs (plus d'une mais moins que les têtes de requêtes), mais l'équilibre entre la vitesse et la qualité est un défi.
-
Surcharge de la bande passante mémoire : L'inférence du décodeur autoregressif est un goulot d'étranglement sévère pour les modèles de transformateur en raison de la surcharge de la bande passante mémoire due au chargement des poids du décodeur et de toutes les clés et valeurs d'attention à chaque étape de décodage. La GQA tente de résoudre ce problème en divisant les têtes de requêtes en groupes, chacun partageant une seule tête de clé et de valeur. Cependant, la gestion de cette surcharge de la bande passante mémoire est un défi significatif.
-
Complexité de la mise en œuvre : La mise en œuvre de la GQA dans le contexte d'un décodeur autoregressif utilisant un modèle de transformateur peut être complexe. Elle implique la répétition des paires clés-valeurs pour l'efficacité computationnelle, la gestion des paires clés-valeurs mises en cache, et l'exécution du calcul d'attention de produit de points échelonné.
-
Division de groupe : Les nœuds d'entrée sont divisés en plusieurs groupes et l'attention est calculée uniquement dans ce bloc local. Si le nombre total de nœuds ne peut pas être divisé par la longueur du groupe, des nœuds rembourrés de zéro sont ajoutés pour correspondre à la longueur. Cette division et cette gestion des groupes ajoutent à la complexité de la mise en œuvre de la GQA.
-
Réglage des hyperparamètres : Pour obtenir des performances optimales avec la GQA, il faut un réglage minutieux des hyperparamètres. Par exemple, le nombre de groupes dans lesquels les têtes de requêtes sont divisées peut avoir un impact significatif sur les performances et l'efficacité du modèle.
Malgré ces défis, la GQA est une technique prometteuse pour améliorer l'efficacité des grands modèles de langage, et la recherche en cours s'attaque à ces problèmes pour optimiser encore plus ses performances.
Quelles sont les orientations futures pour la recherche sur l'Attention de requête groupée?
Les orientations futures pour la recherche sur l'Attention de requête groupée (GQA) pourraient inclure :
-
Explorer différentes stratégies de regroupement : L'implémentation actuelle de la GQA divise les têtes de requêtes en groupes, chacun partageant une seule tête de clé et de valeur. Les recherches futures pourraient explorer différentes stratégies pour regrouper les têtes de requêtes, potentiellement en fonction de la nature des données ou de la tâche en question.
-
Combiner les clés, les requêtes et les valeurs dans l'auto-attention : Certaines recherches ont montré des performances exceptionnelles lors de la combinaison des clés et des requêtes. Il reste à savoir s'il est bénéfique de combiner les clés, les requêtes et les valeurs dans l'auto-attention, ce qui pourrait être une direction intéressante pour la recherche sur la GQA.
-
Appliquer la GQA à différentes tâches : La GQA a été appliquée pour accélérer l'inférence sur les grands modèles de langage. Les recherches futures pourraient explorer l'application de la GQA à d'autres tâches, comme la classification d'images, la détection d'objets, la segmentation sémantique, la compréhension vidéo, la génération d'images, la vision 3D, les tâches multimodales et l'apprentissage auto-supervisé.
-
Améliorer l'efficacité avec des motifs d'attention éparses : Certaines recherches ont proposé d'apprendre des motifs d'attention éparses dynamiques qui évitent d'allouer des calculs et de la mémoire pour prêter attention au contenu sans rapport avec la requête d'intérêt. Cela pourrait être une direction intéressante pour améliorer l'efficacité de la GQA.
-
Compréhension personnalisée des requêtes : Avec l'évolution du domaine de la compréhension des requêtes, il y a un intérêt croissant pour la compréhension personnalisée des requêtes. Les recherches futures pourraient explorer comment la GQA peut être adaptée pour mieux comprendre et répondre aux requêtes individuelles des utilisateurs.
-
Sélection de contenu et génération de plan de contenu : Un nouveau mécanisme d'attention appelé Attention de requête groupée a été proposé pour la sélection de contenu et la génération de plan de contenu dans les modèles de génération de données en texte. Ceci pourrait être une direction intéressante pour la recherche sur la GQA.
Ces directions pourraient potentiellement conduire à des améliorations de la qualité et de l'efficacité de la GQA, ainsi qu'à son applicabilité à un plus grand nombre de tâches.