What is DeepSpeech?
DeepSpeech is an open-source Speech-To-Text (STT) engine that uses a model trained by machine learning techniques. It was initially developed based on Baidu's Deep Speech research paper and is now maintained by Mozilla.
The engine is designed to automatically transcribe spoken audio into text. It takes digital audio as input and returns a "most likely" text transcript of that audio. This process is known as speech recognition inference. DeepSpeech can be used for two key activities related to speech recognition: training and inference.
DeepSpeech is an implementation of an "end-to-end" speech recognition system. This means that the model takes in audio and directly outputs characters or words, as opposed to traditional speech recognition models that might involve multiple stages.
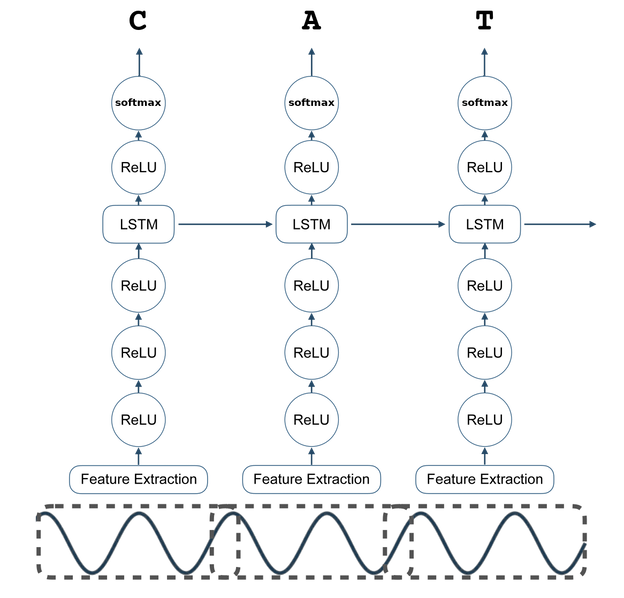
The engine works by first converting the audio into a sequence of probabilities over characters in the alphabet. Then, this sequence of probabilities is converted into a sequence of characters.
DeepSpeech can be used with appropriate hardware (like a GPU) to train a model using a set of voice data, known as a corpus. Then, inference or recognition can be performed using the trained model. DeepSpeech includes several pre-trained models.
The engine is designed to run in real time on a variety of devices, ranging from a Raspberry Pi 4 to high power GPU servers. It can be installed and used via Python, and pre-trained English model files can be downloaded from the DeepSpeech GitHub repository.
It's important to note that as of the latest updates, only 16 kilohertz (kHz) .wav files are supported.
How does DeepSpeech work?
DeepSpeech is an open-source speech recognition engine developed by Mozilla, based on the DeepSpeech algorithm by Baidu. It's designed to convert spoken audio into written text, a process known as speech recognition inference.
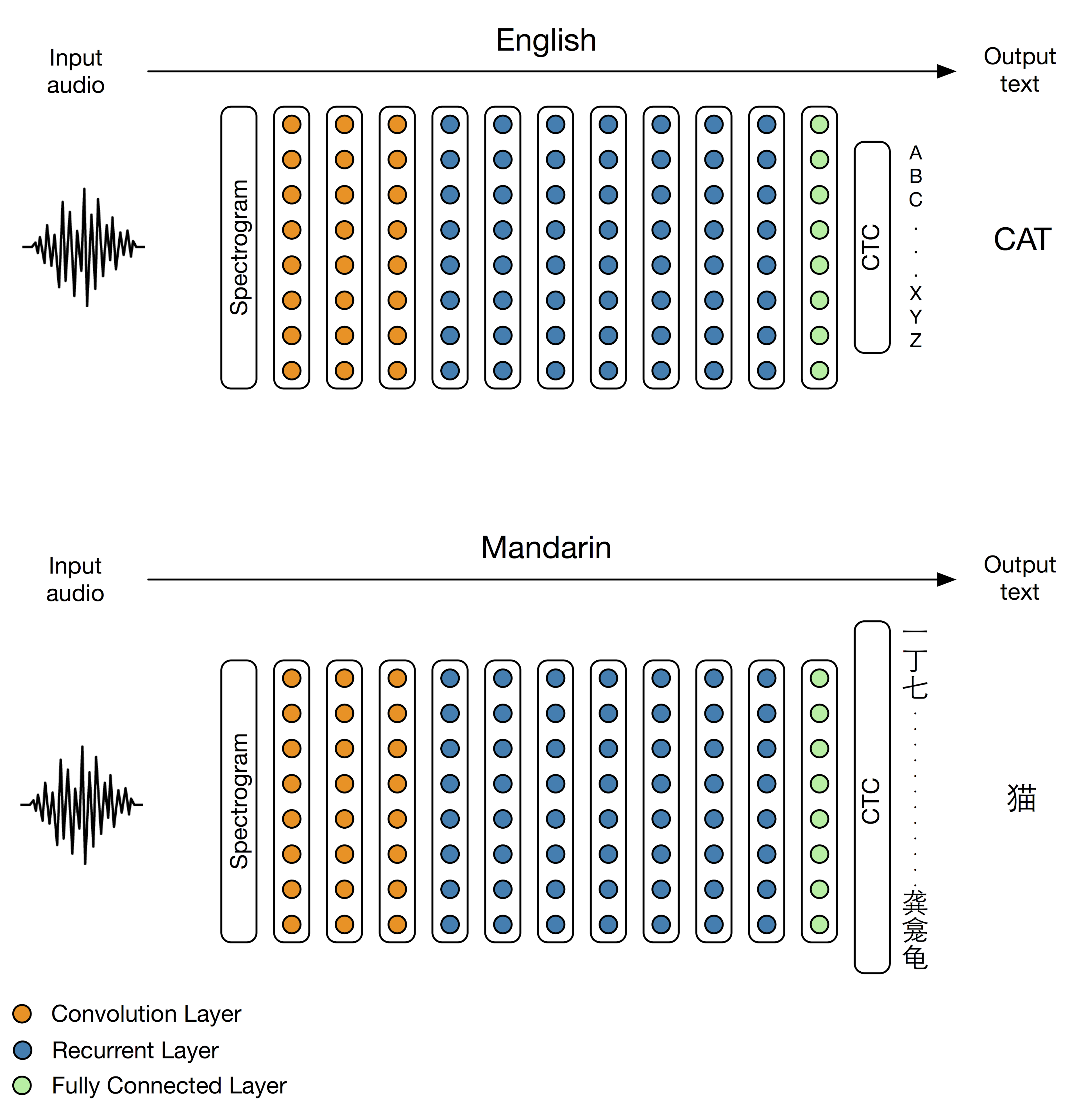
The core of DeepSpeech is a Recurrent Neural Network (RNN) that ingests speech spectrograms. The engine takes a stream of audio as input and converts it into a sequence of characters in the designated alphabet. This conversion involves two main steps:
- The audio is converted into a sequence of probabilities over characters in the alphabet. This is achieved using a Deep Neural Network.
- The sequence of probabilities is then converted into a sequence of characters.
The architecture of DeepSpeech includes several layers.
DeepSpeech can be trained using a set of voice data, known as a corpus. The training process involves updating the gradient to find the lowest loss, with the amount of processing done in one step depending on the batch size. By default, DeepSpeech processes one audio file in each step.
The performance of the model is evaluated using metrics like Word Error Rate (WER) and Character Error Rate (CER). WER measures how accurately DeepSpeech was able to recognize a word, indicating the performance of the language model (scorer). CER measures how accurately DeepSpeech was able to recognize a character, indicating the performance of the acoustic model.
DeepSpeech is designed to be simple, open, and ubiquitous. It doesn't require server-class hardware to execute and is designed to run on many platforms with bindings to many different languages. It's also possible to use pre-trained models released by Mozilla to bootstrap the training process, which can be particularly useful when working with smaller datasets.
How does DeepSpeech compare to other speech-to-text engines?
DeepSpeech, an open-source Speech-To-Text (STT) engine, has several strengths and weaknesses when compared to other STT engines.
Strengths:
- DeepSpeech is based on an end-to-end deep learning approach, which means it does not require hand-designed features to model background noise, reverberation, or phoneme dictionary. Instead, it relies on large amounts of varied data for training.
- It offers reasonably high accuracy and easy trainability with your data.
- DeepSpeech can run in real-time on a range of devices, from high-powered GPUs to a Raspberry Pi 4.
- It provides a pre-trained English model, which means you can use it without sourcing your own data.
Weaknesses:
- Mozilla has wound down development on DeepSpeech, which could mean less support when bugs arise in the software and issues need to be addressed.
- DeepSpeech is provided solely as a Git repo, meaning that to integrate it into a larger application, developers would need to build an API around its inference methods.
- As of the latest updates, only 16 kilohertz (kHz) .wav files are supported.
Comparisons with other STT engines:
- Wav2Letter++: Created by Facebook AI Research, Wav2Letter++ is a more recent engine compared to DeepSpeech. However, it requires more work to integrate into a larger application, similar to DeepSpeech.
- Kaldi: An older and more mature STT engine written in C++, Kaldi is more focused on classical speech recognition techniques rather than deep learning. This could make it less suitable for certain applications compared to DeepSpeech.
- Whisper: OpenAI's Whisper processes voice data on-device and supports multiple languages. However, it only supports batch audio processing, meaning it can't be used for real-time transcription applications like DeepSpeech.
- Commercial APIs: Commercial APIs like Google Speech-to-Text, Amazon Transcribe, and IBM Watson Speech-to-Text are typically more accurate and easier to integrate, with more out-of-the-box features than open-source options like DeepSpeech. However, large scale use of these APIs typically comes with a cost.
In terms of performance, DeepSpeech's accuracy can vary depending on the test dataset used. For example, one test showed a Word Error Rate (WER) of 8.3% for DeepSpeech on the LibriSpeech clean test data set. However, it's important to note that results can vary widely depending on the specific conditions of the test, including the language, accent, and quality of the audio data.
Getting started with DeepSpeech
DeepSpeech is an open-source speech recognition engine developed by Mozilla, based on a neural network architecture first published by Baidu. It's an "end-to-end" model, meaning it takes in audio and directly outputs characters or words.
To get started with DeepSpeech, you'll need to install it and download the pre-trained English model files. You can do this using the following commands:
# Install DeepSpeech
pip3 install deepspeech
# Download pre-trained English model files
curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-models.pbmm
curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-models.scorer
Once you've installed DeepSpeech and downloaded the model files, you can use the Python API to perform speech recognition. Here's a basic example of how to use the API:
# Import the DeepSpeech model
from deepspeech import Model
# Load the model
ds = Model('deepspeech-0.9.3-models.pbmm')
# Perform inference
print(ds.stt(audio))
The audio variable in this example should be a 16-bit, mono raw audio signal at the appropriate sample rate (matching what the model was trained on).
If you want to use DeepSpeech for real-time speech recognition, you can check out the guide on how to do real-time Speech Recognition in Python.
For more advanced usage, such as training your own models with DeepSpeech, you'll need to dive deeper into the documentation and tutorials available online.
Please note that DeepSpeech currently performs best in low-noise environments with clear recordings. Some users may need to train the model further to meet their intended use-case.
FAQs
How Does DeepSpeech Process an Audio File for Speech to Text Conversion?
DeepSpeech processes an audio file for speech-to-text conversion by first loading the audio data, typically in WAV format. It then divides this data into multiple smaller audio frames, suitable for processing. The pre-trained models in DeepSpeech analyze these frames, converting speech (voiced audio) into text. This process involves various machine learning techniques and utilizes models like the acoustic model and language model.
Begins yielding audio frames and generates audio frames for the input wav file regardless of the audio length.
What is the Role of PCM Audio Data in DeepSpeech's Speech Recognition Process?
PCM (Pulse-Code Modulation) audio data plays a crucial role in DeepSpeech's speech recognition process. It represents the raw audio data that DeepSpeech processes. This data is yielded from the input audio file, typically a WAV file, which is then segmented into frames. The frame generator yields PCM audio data for each frame, which is then fed into the speech recognition system for analysis and transcription.
How Does DeepSpeech Handle Longer Audio Files and Non-Voiced Audio Segments?
For longer audio files, DeepSpeech might split the file into smaller, manageable segments. This ensures efficient processing and accurate recognition. Non-voiced audio frames, which contain background noise or silence, are identified using voice activity detection techniques. These frames are usually excluded from processing to improve the accuracy and speed of the speech-to-text conversion.
Can DeepSpeech Perform Asynchronous Speech Recognition and Real-Time Speech Recognition?
Yes, DeepSpeech is capable of performing both asynchronous and real-time speech recognition. Asynchronous recognition involves processing pre-recorded audio files, while real-time recognition deals with streaming audio data, such as from a microphone. This is achieved through the use of various machine learning techniques and optimized model files that can handle continuous audio input and yield immediate transcription results.
What is the Functionality of the Frame Generator in DeepSpeech?
The frame generator in DeepSpeech is responsible for breaking down the input audio data into individual frames of a specified duration. This is essential for processing the audio in smaller, manageable chunks. The frame generator takes into account factors like the desired frame duration, sample rate, and sample width to ensure that each frame is optimally prepared for further processing by the speech recognition models.
How Does DeepSpeech Utilize Pre-Trained Models for Speech Recognition?
DeepSpeech utilizes pre-trained models to convert speech to text. These models, trained on vast datasets, include an acoustic model that interprets the sound waves and a language model that helps in understanding the context and syntax of the spoken language. The pre-trained models significantly enhance the accuracy and efficiency of the speech recognition process.
What is the Importance of the Language Model in DeepSpeech?
The language model in DeepSpeech plays a critical role in understanding and predicting the sequence of words in spoken language. It helps in contextualizing the speech patterns and improves the accuracy of the transcription by considering the linguistic structure and syntax. The language model works in conjunction with the acoustic model to provide a more accurate and coherent speech-to-text conversion.
How Does Voice Activity Detection Work in DeepSpeech?
Voice Activity Detection (VAD) in DeepSpeech is a technique used to identify voiced audio frames, which contain speech, from non-voiced audio frames, which contain silence or background noise. This distinction is crucial for efficient processing, as it allows the system to focus on analyzing frames that are likely to contain meaningful speech data.
What Are the Steps Involved in Saving a Transcript After Speech Recognition in DeepSpeech?
After speech recognition in DeepSpeech, the transcript can be saved by collecting the output text from the recognition process and writing it to a file or database. The process typically involves running inference on the audio frames, gathering the recognized text, and then using file operations to save the transcript in the desired format and location.
How is DeepSpeech's Performance on Multiple GPUs for Training Models?
DeepSpeech's performance on multiple GPUs is generally very efficient for training models. Multiple GPUs allow for parallel processing of large datasets, significantly speeding up the training process. This is especially beneficial for training complex models with vast amounts of voice data, as it reduces the time required to train and refine the models.