Just kidding, they won't die. At least not the product category.
We'll continue to use them and they are crucial to certain products. But most of these Vector DB companies are features, and many of those teams will go on to build great database products at Microsoft and Oracle.
This is part one of a two-part series. In this part, I'll provide some background on how we ended up building on top of pgvector.
Klu is built on PGVector/Supabase
Contrary to most headlines, I think 2022 was the actual year of GenAI and 2023 was the year of the Vector DB. There's massive hype around Vector DBs and the inbound-sales requests from these organizations match the hype cycle. So much hype that in the spring, my co-founder Stefan and I even talked about moving to something like Pinecone. The effort and numbers didn't make sense.
When Pinecone sales reps reached out, the first question I asked was: show me the benchmarks.
I did not receive a response to this request.
Klu is my fourth project built on Supabase and is likely not my last. I discovered Supabase in 2019, and my interest in it was highly influenced by my frustrations with Firebase at a previous startup. While Neon and Scale have great offerings these days, Supabase is the fastest way to build out a SQL database and begin to wrap features around the data.
Evolution and current platform
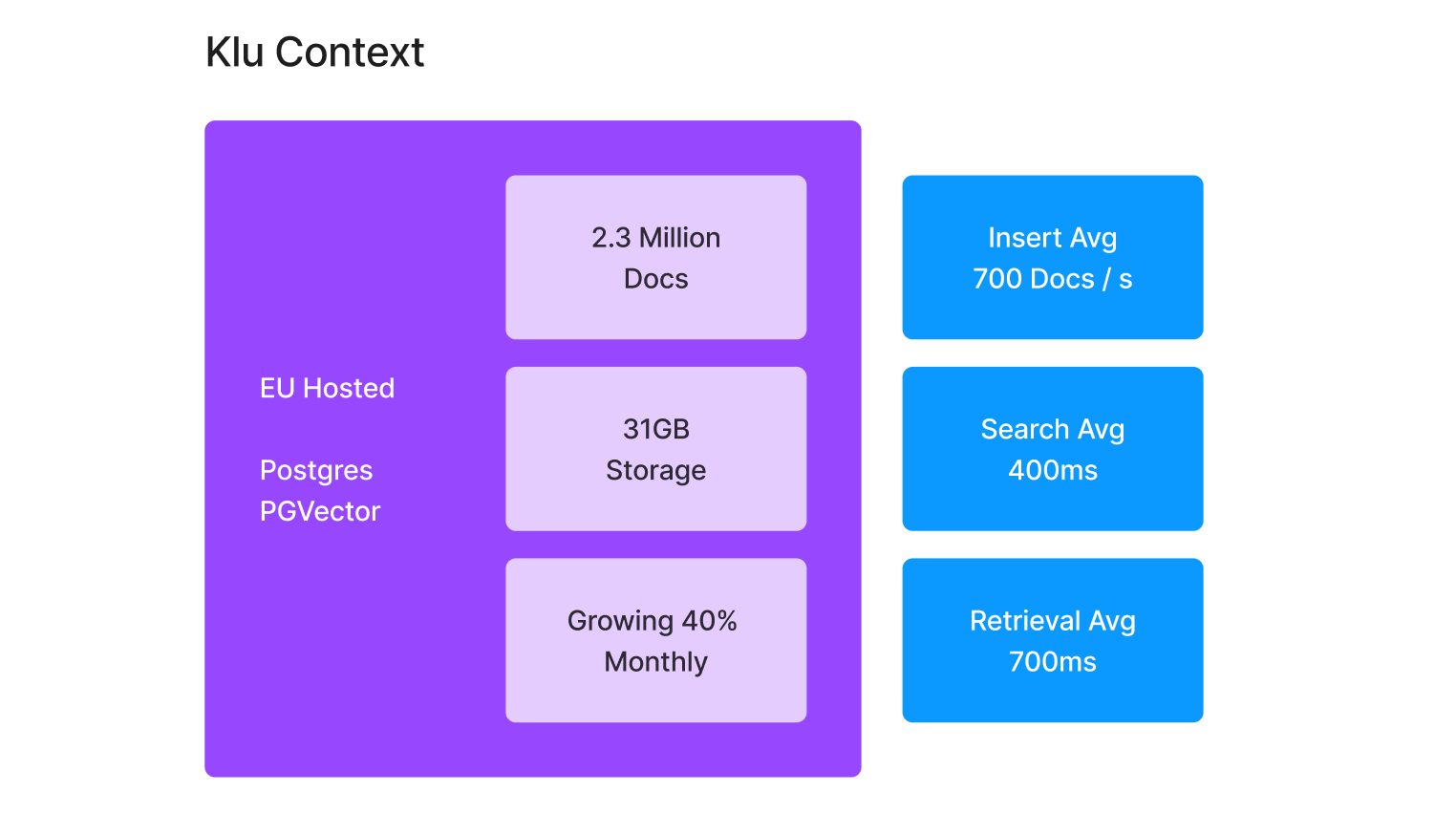
Klu began as a few fine-tuned davinci-003 models and a handful of Python scripts, but has rapidly evolved into a platform serving over 500,000 weekly requests. Klu Context is a custom vector engine built on Supabase using pgvector, which provides management of vector docs, as well as metadata filtering for multi-tenant or other advanced search capabilities.
Here are a few stats from our current system:
- Total documents stored: 2.3M docs at 31GB
- Document insert speeds average 700 docs per second
- Document search averages 400ms
- Document retrieval averages 700ms
It's not the fastest system. I'll be the first to admit this and we've found ways to get the search down to 200ms. But I'm not worried – and let me explain why.
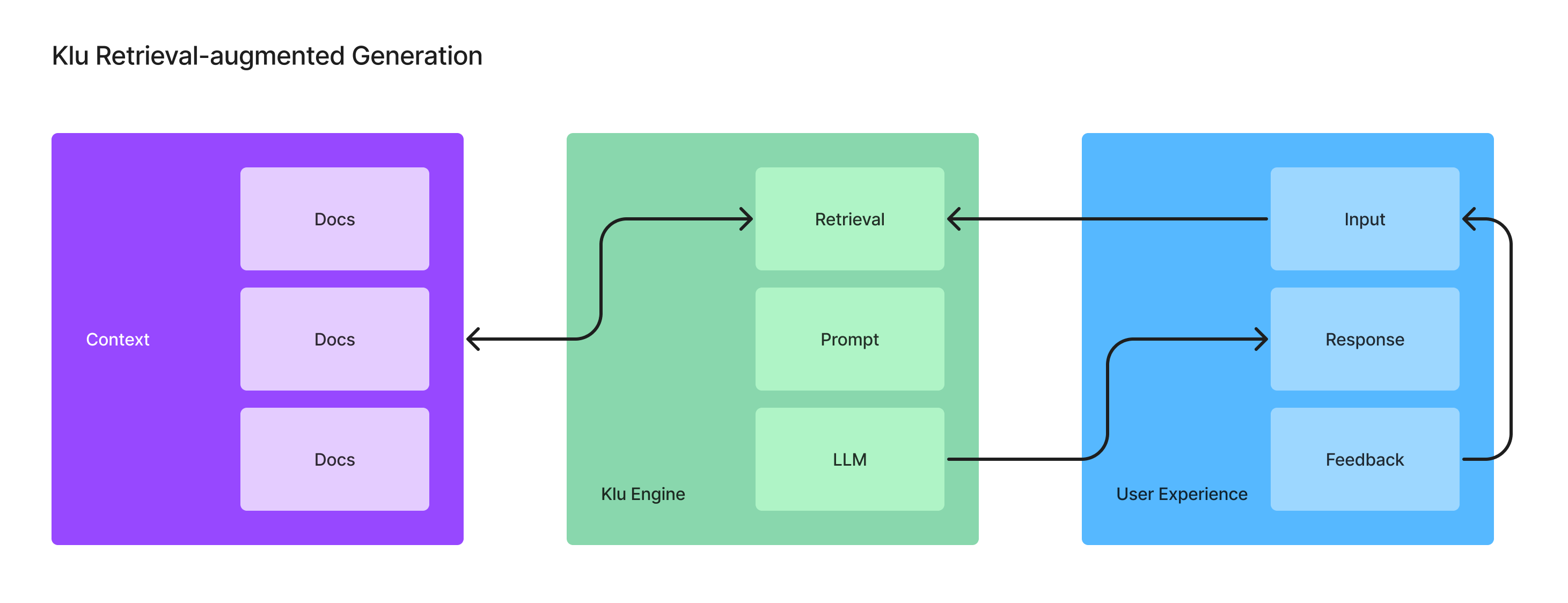
The Retrieval (RAG) Layer Cake
Retrieving just-in-time context for inference is a thing of magic. I first saw this concept working in the fall of 2022. We used data pulled from Amplitude and Notion into a virtual datatable that Davinci then used to answer questions and describe ground truth in Slack.
To perform this trick, you need to:
- Know what to search for
- Query the data
- Retrieve the right information
- Inject this info into the prompt
- Run inference
- Return the result
Retrieval is a layer cake of operations that assemble magic. Each layer adds latency, and latency matters.
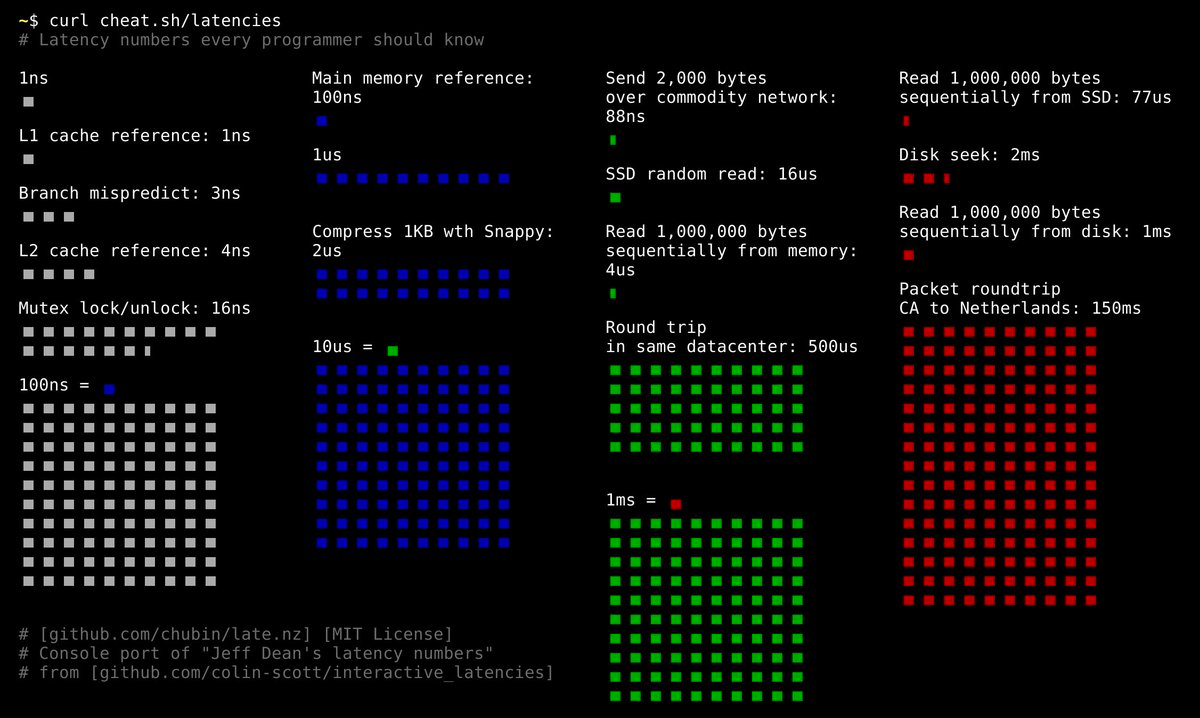
Good APIs respond in 100ms. Good web apps respond in under 1s.
Humans perceive latency around 200ms.
LLMs respond at a rate of 35-200ms per token.
On a bad day, you're waiting 60-90s for GPT-4 to finish.
So what's 200ms more?
What are your users really going to get by obsessing over the retrieval speed when the LLM takes 30-90x longer? I would rather focus on providing more, better data for retrieval, and optimizing an enjoyable UX for inference latency.
Pick the right battles
There are few use cases where optimizing for speed and performance are everything. Perplexity comes to mind – it used to be a bit slow – and now is blazing fast. It needs to be for a great search and research experience. Today, I never ditch Perplexity for a Google Search and in most cases I'm willing to wait a few seconds for the synthesis. But, I'll give you 1M:1 odds that you're not building Perplexity right now, and I would want some conviction or traction before optimizing for speed first. You increase both by optimizing your build and learning velocity.
Building on Postgres/pgvector gave us a tested standard to iterate quickly on as we learned from real-world use. We started on free plans, with a monolith database structure. I've never worried about our backend costs growing out of control due to use and storage – a common frustration heard from founders building on Pinecone.
Unlike the Pinecone sales reps that never answered, Supabase teams continually meet up to listen to our feedback on their vector support, bring us into beta programs for Supavisor and HNSW, and help us migrate to a multi-region architecture.
Since our origins we always built for speed of learnings: we've pivoted, we rebuilt the Klu API engine twice, and moved to a multi-database, multi-region architecture.
Almost all of our architecture decisions prioritize speed of learning and building over a "right way."
But mostly, if I started an all new project tomorrow, I would choose1 Supabase again.
See you in Part 02, where I'll break down our internal benchmarks on a 500k row Q&A dataset. Spoiler: Supabase is not the fastest. And neither is Pinecone.
1 Maybe Chroma, those guys seem cool.